 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Identities: An Ethical Audit of Human and AI-Crafted Personas
May 07, 2025As LLMs (large language models) are increasingly used to generate synthetic personas particularly in data-limited domains such as health, privacy, and HCI, it becomes necessary to understand how these narratives represent identity, especially that of minority communities. In this paper, we audit synthetic personas generated by 3 LLMs (GPT4o, Gemini 1.5 Pro, Deepseek 2.5) through the lens of representational harm, focusing specifically on racial identity. Using a mixed methods approach combining close reading, lexical analysis, and a parameterized creativity framework, we compare 1512 LLM generated personas to human-authored responses. Our findings reveal that LLMs disproportionately foreground racial markers, overproduce culturally coded language, and construct personas that are syntactically elaborate yet narratively reductive. These patterns result in a range of sociotechnical harms, including stereotyping, exoticism, erasure, and benevolent bias, that are often obfuscated by superficially positive narrations. We formalize this phenomenon as algorithmic othering, where minoritized identities are rendered hypervisible but less authentic. Based on these findings, we offer design recommendations for narrative-aware evaluation metrics and community-centered validation protocols for synthetic identity generation.
Can Third-parties Read Our Emotions?
Apr 25, 2025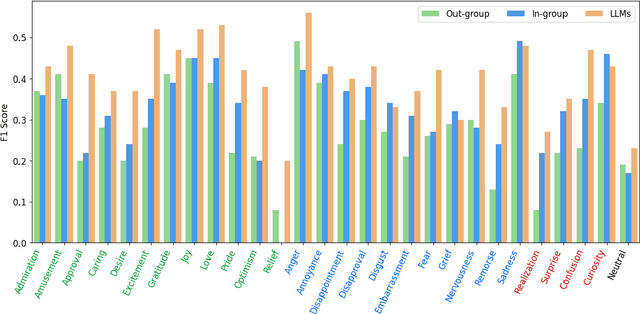
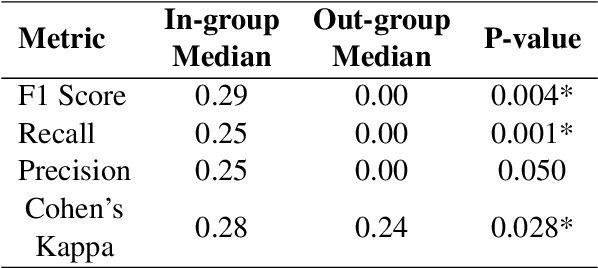
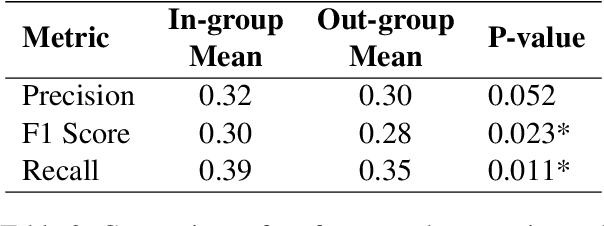
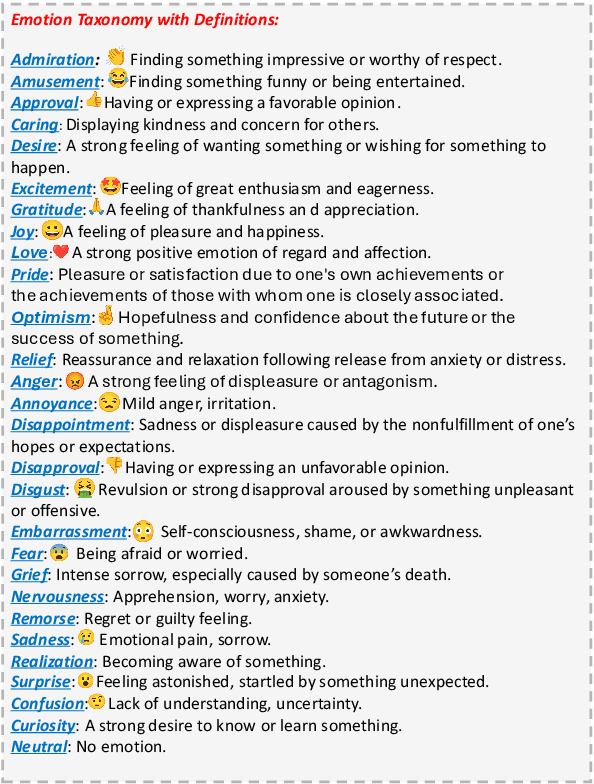
Natural Language Processing tasks that aim to infer an author's private states, e.g., emotions and opinions, from their written text, typically rely on datasets annotated by third-party annotators. However, the assumption that third-party annotators can accurately capture authors' private states remains largely unexamined. In this study, we present human subjects experiments on emotion recognition tasks that directly compare third-party annotations with first-party (author-provided) emotion labels. Our findings reveal significant limitations in third-party annotations-whether provided by human annotators or large language models (LLMs)-in faithfully representing authors' private states. However, LLMs outperform human annotators nearly across the board. We further explore methods to improve third-party annotation quality. We find that demographic similarity between first-party authors and third-party human annotators enhances annotation performance. While incorporating first-party demographic information into prompts leads to a marginal but statistically significant improvement in LLMs' performance. We introduce a framework for evaluating the limitations of third-party annotations and call for refined annotation practices to accurately represent and model authors' private states.
The study of short texts in digital politics: Document aggregation for topic modeling
Mar 07, 2025Statistical topic modeling is widely used in political science to study text. Researchers examine documents of varying lengths, from tweets to speeches. There is ongoing debate on how document length affects the interpretability of topic models. We investigate the effects of aggregating short documents into larger ones based on natural units that partition the corpus. In our study, we analyze one million tweets by U.S. state legislators from April 2016 to September 2020. We find that for documents aggregated at the account level, topics are more associated with individual states than when using individual tweets. This finding is replicated with Wikipedia pages aggregated by birth cities, showing how document definitions can impact topic modeling results.
The Reopening of Pandora's Box: Analyzing the Role of LLMs in the Evolving Battle Against AI-Generated Fake News
Oct 25, 2024



With the rise of AI-generated content spewed at scale from large language models (LLMs), genuine concerns about the spread of fake news have intensified. The perceived ability of LLMs to produce convincing fake news at scale poses new challenges for both human and automated fake news detection systems. To address this gap, this work presents the findings from a university-level competition which aimed to explore how LLMs can be used by humans to create fake news, and to assess the ability of human annotators and AI models to detect it. A total of 110 participants used LLMs to create 252 unique fake news stories, and 84 annotators participated in the detection tasks. Our findings indicate that LLMs are ~68% more effective at detecting real news than humans. However, for fake news detection, the performance of LLMs and humans remains comparable (~60% accuracy). Additionally, we examine the impact of visual elements (e.g., pictures) in news on the accuracy of detecting fake news stories. Finally, we also examine various strategies used by fake news creators to enhance the credibility of their AI-generated content. This work highlights the increasing complexity of detecting AI-generated fake news, particularly in collaborative human-AI settings.
Monolingual and Multilingual Misinformation Detection for Low-Resource Languages: A Comprehensive Survey
Oct 24, 2024



In today's global digital landscape, misinformation transcends linguistic boundaries, posing a significant challenge for moderation systems. While significant advances have been made in misinformation detection, the focus remains largely on monolingual high-resource contexts, with low-resource languages often overlooked. This survey aims to bridge that gap by providing a comprehensive overview of the current research on low-resource language misinformation detection in both monolingual and multilingual settings. We review the existing datasets, methodologies, and tools used in these domains, identifying key challenges related to: data resources, model development, cultural and linguistic context, real-world applications, and research efforts. We also examine emerging approaches, such as language-agnostic models and multi-modal techniques, while emphasizing the need for improved data collection practices, interdisciplinary collaboration, and stronger incentives for socially responsible AI research. Our findings underscore the need for robust, inclusive systems capable of addressing misinformation across diverse linguistic and cultural contexts.
The Unappreciated Role of Intent in Algorithmic Moderation of Social Media Content
May 17, 2024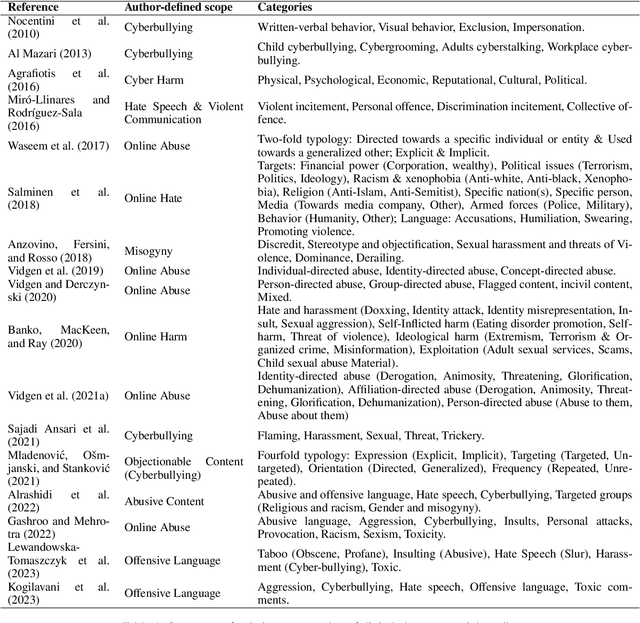
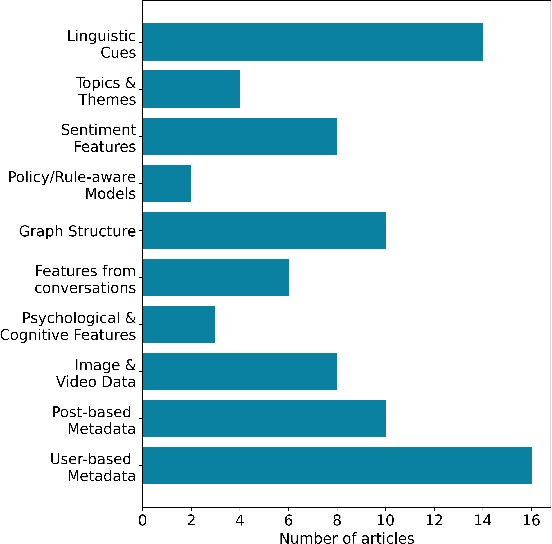
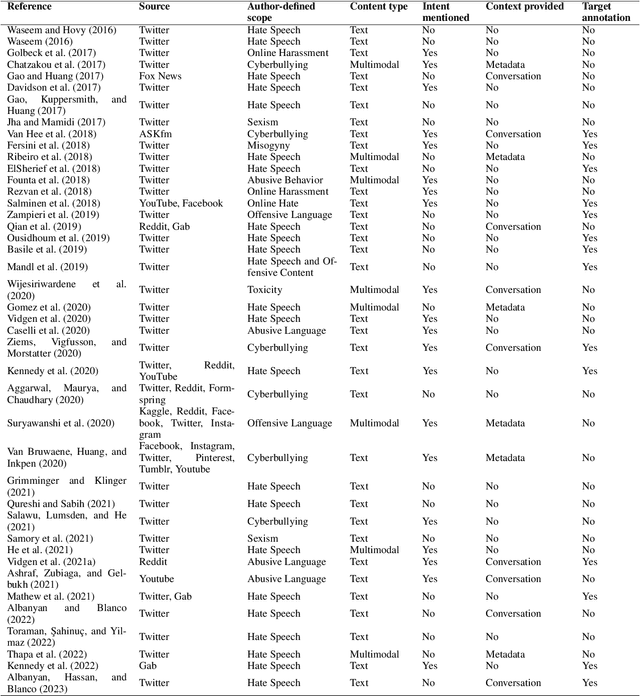
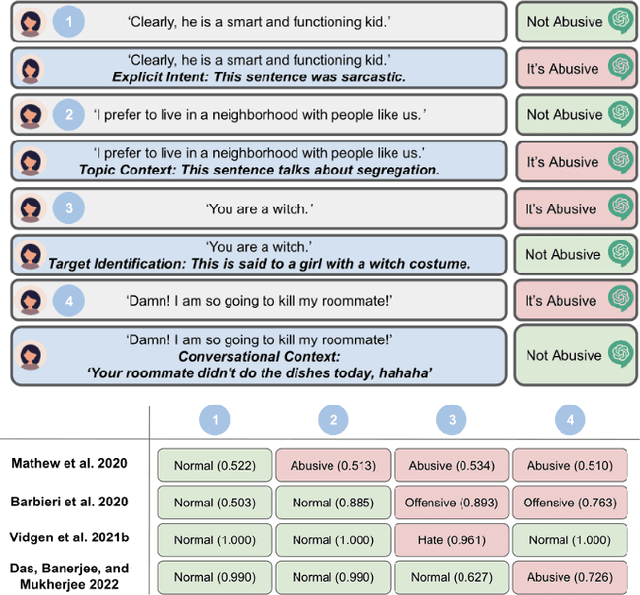
As social media has become a predominant mode of communication globally, the rise of abusive content threatens to undermine civil discourse. Recognizing the critical nature of this issue, a significant body of research has been dedicated to developing language models that can detect various types of online abuse, e.g., hate speech, cyberbullying. However, there exists a notable disconnect between platform policies, which often consider the author's intention as a criterion for content moderation, and the current capabilities of detection models, which typically lack efforts to capture intent. This paper examines the role of intent in content moderation systems. We review state of the art detection models and benchmark training datasets for online abuse to assess their awareness and ability to capture intent. We propose strategic changes to the design and development of automated detection and moderation systems to improve alignment with ethical and policy conceptualizations of abuse.
Inside the echo chamber: Linguistic underpinnings of misinformation on Twitter
Apr 24, 2024Social media users drive the spread of misinformation online by sharing posts that include erroneous information or commenting on controversial topics with unsubstantiated arguments often in earnest. Work on echo chambers has suggested that users' perspectives are reinforced through repeated interactions with like-minded peers, promoted by homophily and bias in information diffusion. Building on long-standing interest in the social bases of language and linguistic underpinnings of social behavior, this work explores how conversations around misinformation are mediated through language use. We compare a number of linguistic measures, e.g., in-/out-group cues, readability, and discourse connectives, within and across topics of conversation and user communities. Our findings reveal increased presence of group identity signals and processing fluency within echo chambers during discussions of misinformation. We discuss the specific character of these broader trends across topics and examine contextual influences.
"Confidently Nonsensical?'': A Critical Survey on the Perspectives and Challenges of 'Hallucinations' in NLP
Apr 11, 2024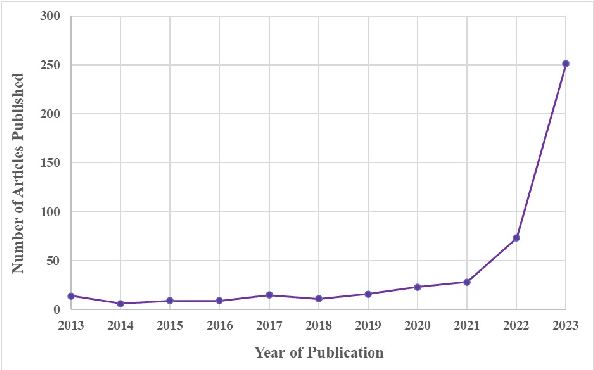


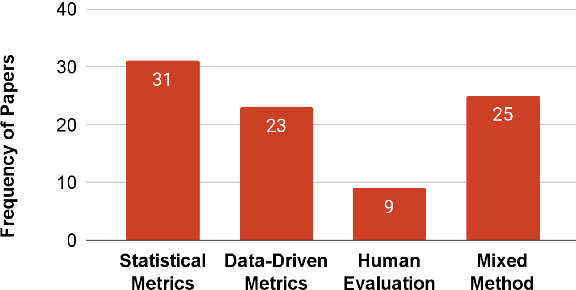
We investigate how hallucination in large language models (LLM) is characterized in peer-reviewed literature using a critical examination of 103 publications across NLP research. Through a comprehensive review of sociological and technological literature, we identify a lack of agreement with the term `hallucination.' Additionally, we conduct a survey with 171 practitioners from the field of NLP and AI to capture varying perspectives on hallucination. Our analysis underscores the necessity for explicit definitions and frameworks outlining hallucination within NLP, highlighting potential challenges, and our survey inputs provide a thematic understanding of the influence and ramifications of hallucination in society.
Exploring Trust and Risk during Online Bartering Interactions
Nov 27, 2023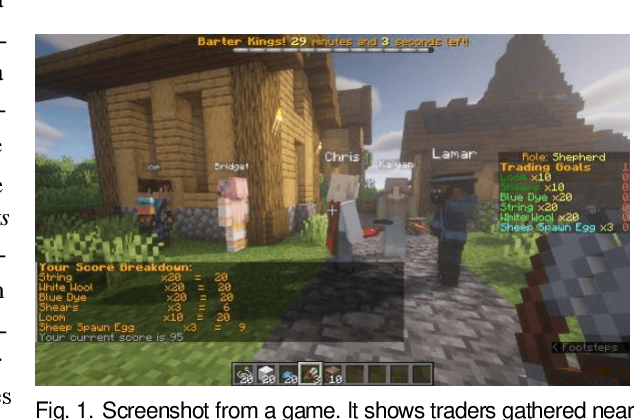
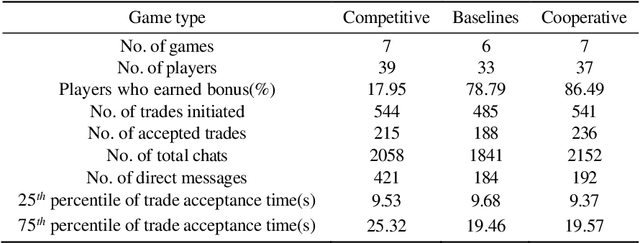
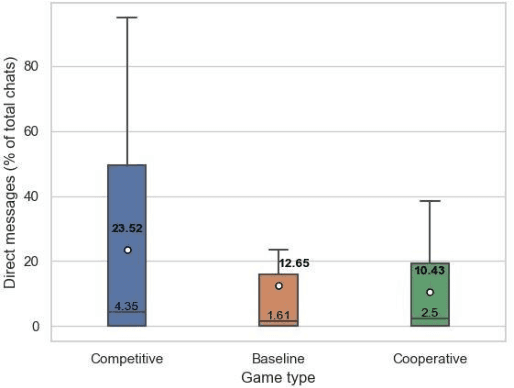
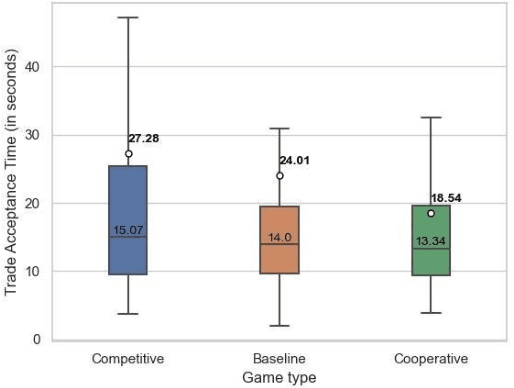
This paper investigates how risk influences the way people barter. We used Minecraft to create an experimental environment in which people bartered to earn a monetary bonus. Our findings reveal that subjects exhibit risk-aversion to competitive bartering environments and deliberate over their trades longer when compared to cooperative environments. These initial experiments lay groundwork for development of agents capable of strategically trading with human counterparts in different environments.
Can Large Language Models Discern Evidence for Scientific Hypotheses? Case Studies in the Social Sciences
Sep 07, 2023



Hypothesis formulation and testing are central to empirical research. A strong hypothesis is a best guess based on existing evidence and informed by a comprehensive view of relevant literature. However, with exponential increase in the number of scientific articles published annually, manual aggregation and synthesis of evidence related to a given hypothesis is a challenge. Our work explores the ability of current large language models (LLMs) to discern evidence in support or refute of specific hypotheses based on the text of scientific abstracts. We share a novel dataset for the task of scientific hypothesis evidencing using community-driven annotations of studies in the social sciences. We compare the performance of LLMs to several state-of-the-art benchmarks and highlight opportunities for future research in this area. The dataset is available at https://github.com/Sai90000/ScientificHypothesisEvidencing.git