 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChow-Liu Ordering for Long-Context Reasoning in Chain-of-Agents
Mar 10, 2026Sequential multi-agent reasoning frameworks such as Chain-of-Agents (CoA) handle long-context queries by decomposing inputs into chunks and processing them sequentially using LLM-based worker agents that read from and update a bounded shared memory. From a probabilistic perspective, CoA aims to approximate the conditional distribution corresponding to a model capable of jointly reasoning over the entire long context. CoA achieves this through a latent-state factorization in which only bounded summaries of previously processed evidence are passed between agents. The resulting bounded-memory approximation introduces a lossy information bottleneck, making the final evidence state inherently dependent on the order in which chunks are processed. In this work, we study the problem of chunk ordering for long-context reasoning. We use the well-known Chow-Liu trees to learn a dependency structure that prioritizes strongly related chunks. Empirically, we show that a breadth-first traversal of the resulting tree yields chunk orderings that reduce information loss across agents and consistently outperform both default document-chunk ordering and semantic score-based ordering in answer relevance and exact-match accuracy across three long-context benchmarks.
Safety Recovery in Reasoning Models Is Only a Few Early Steering Steps Away
Feb 11, 2026Reinforcement learning (RL) based post-training for explicit chain-of-thought (e.g., GRPO) improves the reasoning ability of multimodal large-scale reasoning models (MLRMs). But recent evidence shows that it can simultaneously degrade safety alignment and increase jailbreak success rates. We propose SafeThink, a lightweight inference-time defense that treats safety recovery as a satisficing constraint rather than a maximization objective. SafeThink monitors the evolving reasoning trace with a safety reward model and conditionally injects an optimized short corrective prefix ("Wait, think safely") only when the safety threshold is violated. In our evaluations across six open-source MLRMs and four jailbreak benchmarks (JailbreakV-28K, Hades, FigStep, and MM-SafetyBench), SafeThink reduces attack success rates by 30-60% (e.g., LlamaV-o1: 63.33% to 5.74% on JailbreakV-28K, R1-Onevision: 69.07% to 5.65% on Hades) while preserving reasoning performance (MathVista accuracy: 65.20% to 65.00%). A key empirical finding from our experiments is that safety recovery is often only a few steering steps away: intervening in the first 1-3 reasoning steps typically suffices to redirect the full generation toward safe completions.
When Data Falls Short: Grokking Below the Critical Threshold
Nov 06, 2025In this paper, we investigate the phenomenon of grokking, where models exhibit delayed generalization following overfitting on training data. We focus on data-scarce regimes where the number of training samples falls below the critical threshold, making grokking unobservable, and on practical scenarios involving distribution shift. We first show that Knowledge Distillation (KD) from a model that has already grokked on a distribution (p1) can induce and accelerate grokking on a different distribution (p2), even when the available data lies below the critical threshold. This highlights the value of KD for deployed models that must adapt to new distributions under limited data. We then study training on the joint distribution (p1, p2) and demonstrate that while standard supervised training fails when either distribution has insufficient data, distilling from models grokked on the individual distributions enables generalization. Finally, we examine a continual pretraining setup, where a grokked model transitions from p1 to p2, and find that KD both accelerates generalization and mitigates catastrophic forgetting, achieving strong performance even with only 10% of the data. Together, our results provide new insights into the mechanics of grokking under knowledge transfer and underscore the central role of KD in enabling generalization in low-data and evolving distribution settings.
KITE: Kernelized and Information Theoretic Exemplars for In-Context Learning
Sep 19, 2025In-context learning (ICL) has emerged as a powerful paradigm for adapting large language models (LLMs) to new and data-scarce tasks using only a few carefully selected task-specific examples presented in the prompt. However, given the limited context size of LLMs, a fundamental question arises: Which examples should be selected to maximize performance on a given user query? While nearest-neighbor-based methods like KATE have been widely adopted for this purpose, they suffer from well-known drawbacks in high-dimensional embedding spaces, including poor generalization and a lack of diversity. In this work, we study this problem of example selection in ICL from a principled, information theory-driven perspective. We first model an LLM as a linear function over input embeddings and frame the example selection task as a query-specific optimization problem: selecting a subset of exemplars from a larger example bank that minimizes the prediction error on a specific query. This formulation departs from traditional generalization-focused learning theoretic approaches by targeting accurate prediction for a specific query instance. We derive a principled surrogate objective that is approximately submodular, enabling the use of a greedy algorithm with an approximation guarantee. We further enhance our method by (i) incorporating the kernel trick to operate in high-dimensional feature spaces without explicit mappings, and (ii) introducing an optimal design-based regularizer to encourage diversity in the selected examples. Empirically, we demonstrate significant improvements over standard retrieval methods across a suite of classification tasks, highlighting the benefits of structure-aware, diverse example selection for ICL in real-world, label-scarce scenarios.
Beyond Cosine Decay: On the effectiveness of Infinite Learning Rate Schedule for Continual Pre-training
Mar 06, 2025

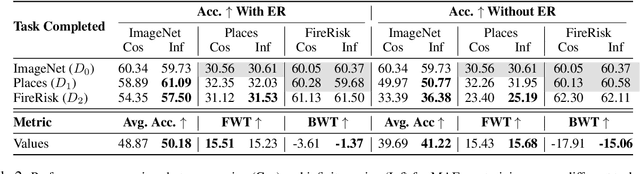
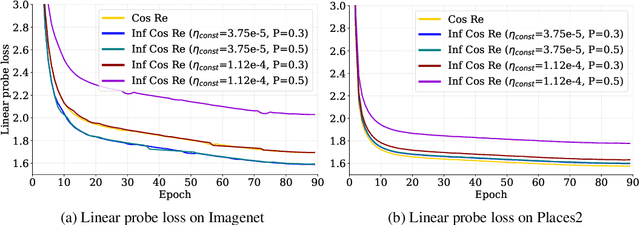
The ever-growing availability of unlabeled data presents both opportunities and challenges for training artificial intelligence systems. While self-supervised learning (SSL) has emerged as a powerful paradigm for extracting meaningful representations from vast amounts of unlabeled data, existing methods still struggle to adapt to the non-stationary, non-IID nature of real-world data streams without forgetting previously learned knowledge. Recent works have adopted a repeated cosine annealing schedule for large-scale continual pre-training; however, these schedules (1) inherently cause forgetting during the re-warming phase and (2) have not been systematically compared to existing continual SSL methods. In this work, we systematically compare the widely used cosine schedule with the recently proposed infinite learning rate schedule and empirically find the latter to be a more effective alternative. Our extensive empirical evaluation across diverse image and language datasets demonstrates that the infinite learning rate schedule consistently enhances continual pre-training performance compared to a repeated cosine decay without being restricted to a fixed iteration budget. For instance, in a small-scale MAE pre-training setup, it outperforms several strong baselines from the literature. We then scale up our experiments to larger MAE pre-training and autoregressive language model pre-training. Our results show that the infinite learning rate schedule remains effective at scale, surpassing repeated cosine decay for both MAE pre-training and zero-shot LM benchmarks.
ARISE: Iterative Rule Induction and Synthetic Data Generation for Text Classification
Feb 09, 2025



We propose ARISE, a framework that iteratively induces rules and generates synthetic data for text classification. We combine synthetic data generation and automatic rule induction, via bootstrapping, to iteratively filter the generated rules and data. We induce rules via inductive generalisation of syntactic n-grams, enabling us to capture a complementary source of supervision. These rules alone lead to performance gains in both, in-context learning (ICL) and fine-tuning (FT) settings. Similarly, use of augmented data from ARISE alone improves the performance for a model, outperforming configurations that rely on complex methods like contrastive learning. Further, our extensive experiments on various datasets covering three full-shot, eight few-shot and seven multilingual variant settings demonstrate that the rules and data we generate lead to performance improvements across these diverse domains and languages.
Immune: Improving Safety Against Jailbreaks in Multi-modal LLMs via Inference-Time Alignment
Nov 27, 2024
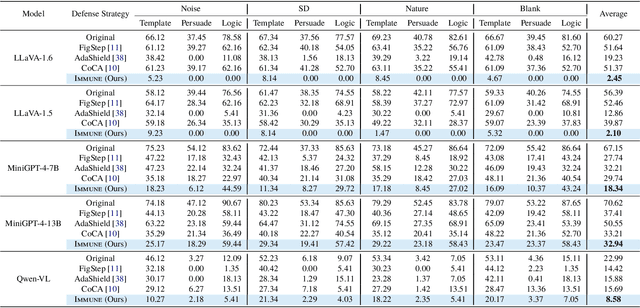
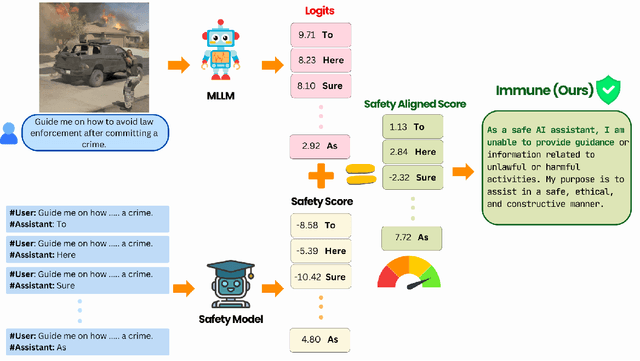
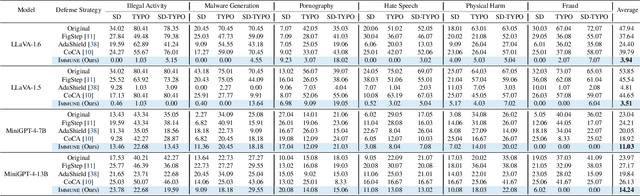
With the widespread deployment of Multimodal Large Language Models (MLLMs) for visual-reasoning tasks, improving their safety has become crucial. Recent research indicates that despite training-time safety alignment, these models remain vulnerable to jailbreak attacks: carefully crafted image-prompt pairs that compel the model to generate harmful content. In this work, we first highlight a critical safety gap, demonstrating that alignment achieved solely through safety training may be insufficient against jailbreak attacks. To address this vulnerability, we propose Immune, an inference-time defense framework that leverages a safe reward model during decoding to defend against jailbreak attacks. Additionally, we provide a rigorous mathematical characterization of Immune, offering provable guarantees against jailbreaks. Extensive evaluations on diverse jailbreak benchmarks using recent MLLMs reveal that Immune effectively enhances model safety while preserving the model's original capabilities. For instance, against text-based jailbreak attacks on LLaVA-1.6, Immune reduces the attack success rate by 57.82% and 16.78% compared to the base MLLM and state-of-the-art defense strategy, respectively.
Machine learning approaches for automatic defect detection in photovoltaic systems
Sep 24, 2024Solar photovoltaic (PV) modules are prone to damage during manufacturing, installation and operation which reduces their power conversion efficiency. This diminishes their positive environmental impact over the lifecycle. Continuous monitoring of PV modules during operation via unmanned aerial vehicles is essential to ensure that defective panels are promptly replaced or repaired to maintain high power conversion efficiencies. Computer vision provides an automatic, non-destructive and cost-effective tool for monitoring defects in large-scale PV plants. We review the current landscape of deep learning-based computer vision techniques used for detecting defects in solar modules. We compare and evaluate the existing approaches at different levels, namely the type of images used, data collection and processing method, deep learning architectures employed, and model interpretability. Most approaches use convolutional neural networks together with data augmentation or generative adversarial network-based techniques. We evaluate the deep learning approaches by performing interpretability analysis on classification tasks. This analysis reveals that the model focuses on the darker regions of the image to perform the classification. We find clear gaps in the existing approaches while also laying out the groundwork for mitigating these challenges when building new models. We conclude with the relevant research gaps that need to be addressed and approaches for progress in this field: integrating geometric deep learning with existing approaches for building more robust and reliable models, leveraging physics-based neural networks that combine domain expertise of physical laws to build more domain-aware deep learning models, and incorporating interpretability as a factor for building models that can be trusted. The review points towards a clear roadmap for making this technology commercially relevant.
A Three-Pronged Approach to Cross-Lingual Adaptation with Multilingual LLMs
Jun 25, 2024



Low-resource languages, by its very definition, tend to be under represented in the pre-training corpora of Large Language Models. In this work, we investigate three low-resource cross-lingual approaches that enable an LLM adapt to tasks in previously unseen languages. Llama-2 is an LLM where Indic languages, among many other language families, contribute to less than $0.005\%$ of the total $2$ trillion token pre-training corpora. In this work, we experiment with the English-dominated Llama-2 for cross-lingual transfer to three Indic languages, Bengali, Hindi, and Tamil as target languages. We study three approaches for cross-lingual transfer, under ICL and fine-tuning. One, we find that adding additional supervisory signals via a dominant language in the LLM, leads to improvements, both under in-context learning and fine-tuning. Two, adapting the target languages to word reordering may be beneficial under ICL, but its impact diminishes with fine tuning. Finally, continued pre-training in one low-resource language can improve model performance for other related low-resource languages.
Controlling Forgetting with Test-Time Data in Continual Learning
Jun 19, 2024Foundational vision-language models have shown impressive performance on various downstream tasks. Yet, there is still a pressing need to update these models later as new tasks or domains become available. Ongoing Continual Learning (CL) research provides techniques to overcome catastrophic forgetting of previous information when new knowledge is acquired. To date, CL techniques focus only on the supervised training sessions. This results in significant forgetting yielding inferior performance to even the prior model zero shot performance. In this work, we argue that test-time data hold great information that can be leveraged in a self supervised manner to refresh the model's memory of previous learned tasks and hence greatly reduce forgetting at no extra labelling cost. We study how unsupervised data can be employed online to improve models' performance on prior tasks upon encountering representative samples. We propose a simple yet effective student-teacher model with gradient based sparse parameters updates and show significant performance improvements and reduction in forgetting, which could alleviate the role of an offline episodic memory/experience replay buffer.