 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARISE: Iterative Rule Induction and Synthetic Data Generation for Text Classification
Feb 09, 2025



We propose ARISE, a framework that iteratively induces rules and generates synthetic data for text classification. We combine synthetic data generation and automatic rule induction, via bootstrapping, to iteratively filter the generated rules and data. We induce rules via inductive generalisation of syntactic n-grams, enabling us to capture a complementary source of supervision. These rules alone lead to performance gains in both, in-context learning (ICL) and fine-tuning (FT) settings. Similarly, use of augmented data from ARISE alone improves the performance for a model, outperforming configurations that rely on complex methods like contrastive learning. Further, our extensive experiments on various datasets covering three full-shot, eight few-shot and seven multilingual variant settings demonstrate that the rules and data we generate lead to performance improvements across these diverse domains and languages.
CSSL: Contrastive Self-Supervised Learning for Dependency Parsing on Relatively Free Word Ordered and Morphologically Rich Low Resource Languages
Oct 09, 2024



Neural dependency parsing has achieved remarkable performance for low resource morphologically rich languages. It has also been well-studied that morphologically rich languages exhibit relatively free word order. This prompts a fundamental investigation: Is there a way to enhance dependency parsing performance, making the model robust to word order variations utilizing the relatively free word order nature of morphologically rich languages? In this work, we examine the robustness of graph-based parsing architectures on 7 relatively free word order languages. We focus on scrutinizing essential modifications such as data augmentation and the removal of position encoding required to adapt these architectures accordingly. To this end, we propose a contrastive self-supervised learning method to make the model robust to word order variations. Furthermore, our proposed modification demonstrates a substantial average gain of 3.03/2.95 points in 7 relatively free word order languages, as measured by the UAS/LAS Score metric when compared to the best performing baseline.
A Three-Pronged Approach to Cross-Lingual Adaptation with Multilingual LLMs
Jun 25, 2024



Low-resource languages, by its very definition, tend to be under represented in the pre-training corpora of Large Language Models. In this work, we investigate three low-resource cross-lingual approaches that enable an LLM adapt to tasks in previously unseen languages. Llama-2 is an LLM where Indic languages, among many other language families, contribute to less than $0.005\%$ of the total $2$ trillion token pre-training corpora. In this work, we experiment with the English-dominated Llama-2 for cross-lingual transfer to three Indic languages, Bengali, Hindi, and Tamil as target languages. We study three approaches for cross-lingual transfer, under ICL and fine-tuning. One, we find that adding additional supervisory signals via a dominant language in the LLM, leads to improvements, both under in-context learning and fine-tuning. Two, adapting the target languages to word reordering may be beneficial under ICL, but its impact diminishes with fine tuning. Finally, continued pre-training in one low-resource language can improve model performance for other related low-resource languages.
IntenDD: A Unified Contrastive Learning Approach for Intent Detection and Discovery
Oct 25, 2023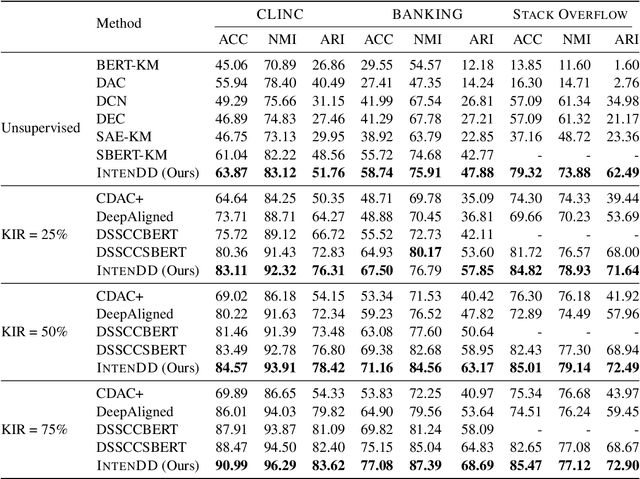
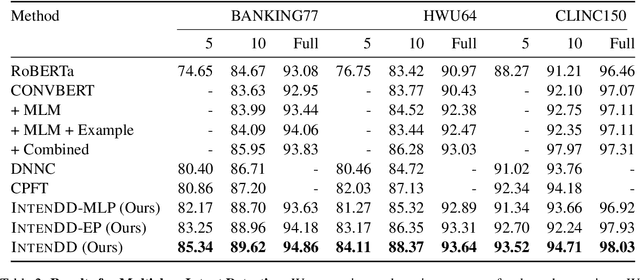
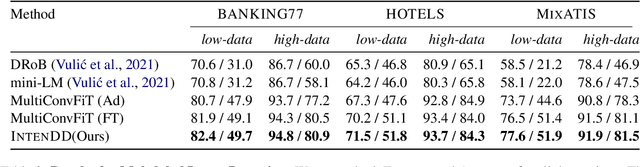

Identifying intents from dialogue utterances forms an integral component of task-oriented dialogue systems. Intent-related tasks are typically formulated either as a classification task, where the utterances are classified into predefined categories or as a clustering task when new and previously unknown intent categories need to be discovered from these utterances. Further, the intent classification may be modeled in a multiclass (MC) or multilabel (ML) setup. While typically these tasks are modeled as separate tasks, we propose IntenDD, a unified approach leveraging a shared utterance encoding backbone. IntenDD uses an entirely unsupervised contrastive learning strategy for representation learning, where pseudo-labels for the unlabeled utterances are generated based on their lexical features. Additionally, we introduce a two-step post-processing setup for the classification tasks using modified adsorption. Here, first, the residuals in the training data are propagated followed by smoothing the labels both modeled in a transductive setting. Through extensive evaluations on various benchmark datasets, we find that our approach consistently outperforms competitive baselines across all three tasks. On average, IntenDD reports percentage improvements of 2.32%, 1.26%, and 1.52% in their respective metrics for few-shot MC, few-shot ML, and the intent discovery tasks respectively.
Adversarial Clean Label Backdoor Attacks and Defenses on Text Classification Systems
May 31, 2023Clean-label (CL) attack is a form of data poisoning attack where an adversary modifies only the textual input of the training data, without requiring access to the labeling function. CL attacks are relatively unexplored in NLP, as compared to label flipping (LF) attacks, where the latter additionally requires access to the labeling function as well. While CL attacks are more resilient to data sanitization and manual relabeling methods than LF attacks, they often demand as high as ten times the poisoning budget than LF attacks. In this work, we first introduce an Adversarial Clean Label attack which can adversarially perturb in-class training examples for poisoning the training set. We then show that an adversary can significantly bring down the data requirements for a CL attack, using the aforementioned approach, to as low as 20% of the data otherwise required. We then systematically benchmark and analyze a number of defense methods, for both LF and CL attacks, some previously employed solely for LF attacks in the textual domain and others adapted from computer vision. We find that text-specific defenses greatly vary in their effectiveness depending on their properties.
Sāmayik: A Benchmark and Dataset for English-Sanskrit Translation
May 23, 2023

Sanskrit is a low-resource language with a rich heritage. Digitized Sanskrit corpora reflective of the contemporary usage of Sanskrit, specifically that too in prose, is heavily under-represented at present. Presently, no such English-Sanskrit parallel dataset is publicly available. We release a dataset, S\={a}mayik, of more than 42,000 parallel English-Sanskrit sentences, from four different corpora that aim to bridge this gap. Moreover, we also release benchmarks adapted from existing multilingual pretrained models for Sanskrit-English translation. We include training splits from our contemporary dataset and the Sanskrit-English parallel sentences from the training split of Itih\={a}sa, a previously released classical era machine translation dataset containing Sanskrit.
A Benchmark and Dataset for Post-OCR text correction in Sanskrit
Nov 15, 2022



Sanskrit is a classical language with about 30 million extant manuscripts fit for digitisation, available in written, printed or scannedimage forms. However, it is still considered to be a low-resource language when it comes to available digital resources. In this work, we release a post-OCR text correction dataset containing around 218,000 sentences, with 1.5 million words, from 30 different books. Texts in Sanskrit are known to be diverse in terms of their linguistic and stylistic usage since Sanskrit was the 'lingua franca' for discourse in the Indian subcontinent for about 3 millennia. Keeping this in mind, we release a multi-domain dataset, from areas as diverse as astronomy, medicine and mathematics, with some of them as old as 18 centuries. Further, we release multiple strong baselines as benchmarks for the task, based on pre-trained Seq2Seq language models. We find that our best-performing model, consisting of byte level tokenization in conjunction with phonetic encoding (Byt5+SLP1), yields a 23% point increase over the OCR output in terms of word and character error rates. Moreover, we perform extensive experiments in evaluating these models on their performance and analyse common causes of mispredictions both at the graphemic and lexical levels. Our code and dataset is publicly available at https://github.com/ayushbits/pe-ocr-sanskrit.
ProoFVer: Natural Logic Theorem Proving for Fact Verification
Aug 25, 2021
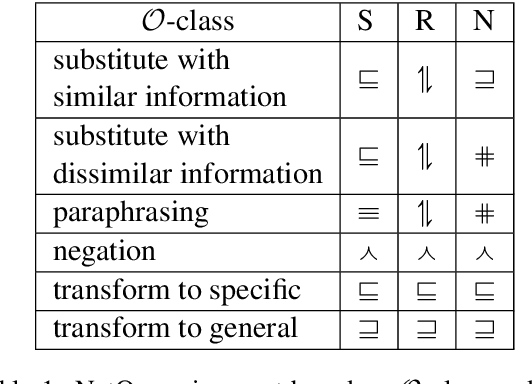

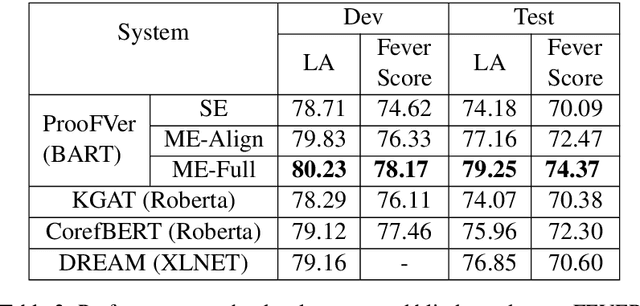
We propose ProoFVer, a proof system for fact verification using natural logic. The textual entailment model in ProoFVer is a seq2seq model generating valid natural-logic based logical inferences as its proofs. The generation of proofs makes ProoFVer an explainable system. The proof consists of iterative lexical mutations of spans in the claim with spans in a set of retrieved evidence sentences. Further, each such mutation is marked with an entailment relation using natural logic operators. The veracity of a claim is determined solely based on the sequence of natural logic relations present in the proof. By design, this makes ProoFVer a faithful by construction system that generates faithful explanations. ProoFVer outperforms existing fact-verification models, with more than two percent absolute improvements in performance and robustness. In addition to its explanations being faithful, ProoFVer also scores high on rationale extraction, with a five point absolute improvement compared to attention-based rationales in existing models. Finally, we find that humans correctly simulate ProoFVer's decisions more often using the proofs, than the decisions of an existing model that directly use the retrieved evidence for decision making.
Automatic Speech Recognition in Sanskrit: A New Speech Corpus and Modelling Insights
Jun 02, 2021
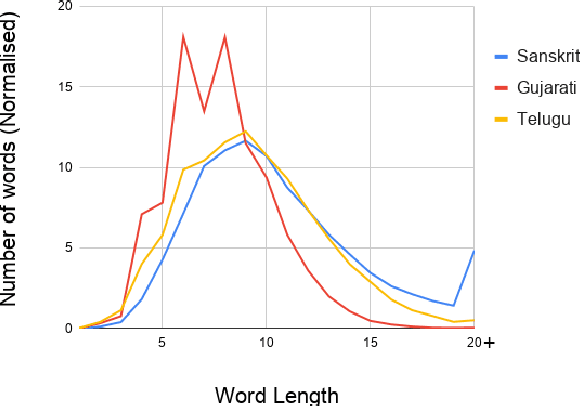


Automatic speech recognition (ASR) in Sanskrit is interesting, owing to the various linguistic peculiarities present in the language. The Sanskrit language is lexically productive, undergoes euphonic assimilation of phones at the word boundaries and exhibits variations in spelling conventions and in pronunciations. In this work, we propose the first large scale study of automatic speech recognition (ASR) in Sanskrit, with an emphasis on the impact of unit selection in Sanskrit ASR. In this work, we release a 78 hour ASR dataset for Sanskrit, which faithfully captures several of the linguistic characteristics expressed by the language. We investigate the role of different acoustic model and language model units in ASR systems for Sanskrit. We also propose a new modelling unit, inspired by the syllable level unit selection, that captures character sequences from one vowel in the word to the next vowel. We also highlight the importance of choosing graphemic representations for Sanskrit and show the impact of this choice on word error rates (WER). Finally, we extend these insights from Sanskrit ASR for building ASR systems in two other Indic languages, Gujarati and Telugu. For both these languages, our experimental results show that the use of phonetic based graphemic representations in ASR results in performance improvements as compared to ASR systems that use native scripts.
A Little Pretraining Goes a Long Way: A Case Study on Dependency Parsing Task for Low-resource Morphologically Rich Languages
Feb 12, 2021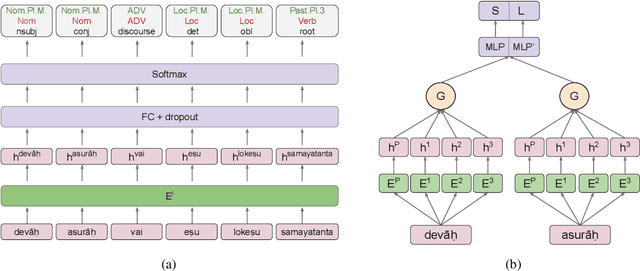
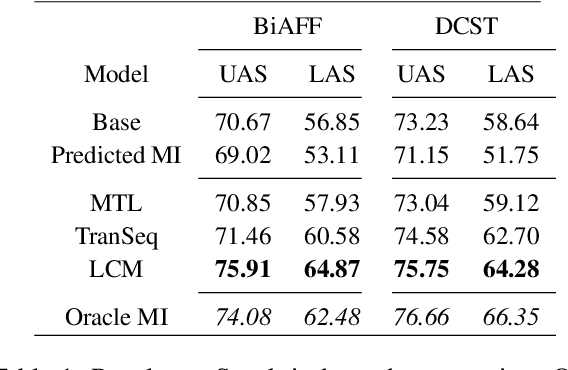
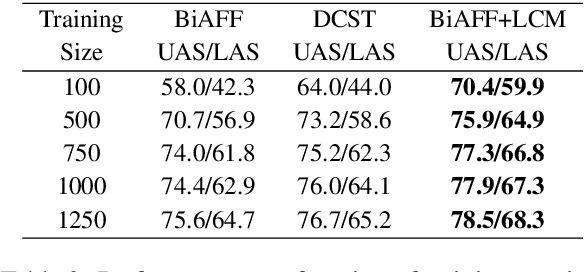

Neural dependency parsing has achieved remarkable performance for many domains and languages. The bottleneck of massive labeled data limits the effectiveness of these approaches for low resource languages. In this work, we focus on dependency parsing for morphological rich languages (MRLs) in a low-resource setting. Although morphological information is essential for the dependency parsing task, the morphological disambiguation and lack of powerful analyzers pose challenges to get this information for MRLs. To address these challenges, we propose simple auxiliary tasks for pretraining. We perform experiments on 10 MRLs in low-resource settings to measure the efficacy of our proposed pretraining method and observe an average absolute gain of 2 points (UAS) and 3.6 points (LAS). Code and data available at: https://github.com/jivnesh/LCM