 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARISE: Iterative Rule Induction and Synthetic Data Generation for Text Classification
Feb 09, 2025



We propose ARISE, a framework that iteratively induces rules and generates synthetic data for text classification. We combine synthetic data generation and automatic rule induction, via bootstrapping, to iteratively filter the generated rules and data. We induce rules via inductive generalisation of syntactic n-grams, enabling us to capture a complementary source of supervision. These rules alone lead to performance gains in both, in-context learning (ICL) and fine-tuning (FT) settings. Similarly, use of augmented data from ARISE alone improves the performance for a model, outperforming configurations that rely on complex methods like contrastive learning. Further, our extensive experiments on various datasets covering three full-shot, eight few-shot and seven multilingual variant settings demonstrate that the rules and data we generate lead to performance improvements across these diverse domains and languages.
Enhancing Low-Resource NMT with a Multilingual Encoder and Knowledge Distillation: A Case Study
Jul 09, 2024Neural Machine Translation (NMT) remains a formidable challenge, especially when dealing with low-resource languages. Pre-trained sequence-to-sequence (seq2seq) multi-lingual models, such as mBART-50, have demonstrated impressive performance in various low-resource NMT tasks. However, their pre-training has been confined to 50 languages, leaving out support for numerous low-resource languages, particularly those spoken in the Indian subcontinent. Expanding mBART-50's language support requires complex pre-training, risking performance decline due to catastrophic forgetting. Considering these expanding challenges, this paper explores a framework that leverages the benefits of a pre-trained language model along with knowledge distillation in a seq2seq architecture to facilitate translation for low-resource languages, including those not covered by mBART-50. The proposed framework employs a multilingual encoder-based seq2seq model as the foundational architecture and subsequently uses complementary knowledge distillation techniques to mitigate the impact of imbalanced training. Our framework is evaluated on three low-resource Indic languages in four Indic-to-Indic directions, yielding significant BLEU-4 and chrF improvements over baselines. Further, we conduct human evaluation to confirm effectiveness of our approach. Our code is publicly available at https://github.com/raypretam/Two-step-low-res-NMT.
LexGen: Domain-aware Multilingual Lexicon Generation
May 18, 2024



Lexicon or dictionary generation across domains is of significant societal importance, as it can potentially enhance information accessibility for a diverse user base while preserving language identity. Prior work in the field primarily focuses on bilingual lexical induction, which deals with word alignments using mapping-based or corpora-based approaches. Though initiated by researchers, the research associated with lexicon generation is limited, even more so with domain-specific lexicons. This task becomes particularly important in atypical medical, engineering, and other technical domains, owing to the highly infrequent usage of the terms and negligibly low data availability of technical terms in many low-resource languages. Owing to the research gap in lexicon generation, especially with a limited focus on the domain-specific area, we propose a new model to generate dictionary words for 6 Indian languages in the multi-domain setting. Our model consists of domain-specific and domain-generic layers that encode information, and these layers are invoked via a learnable routing technique. Further, we propose an approach to explicitly leverage the relatedness between these Indian languages toward coherent translation. We also release a new benchmark dataset across 6 Indian languages that span 8 diverse domains that can propel further research in domain-specific lexicon induction. We conduct both zero-shot and few-shot experiments across multiple domains to show the efficacy of our proposed model in generalizing to unseen domains and unseen languages.
FAIR: Filtering of Automatically Induced Rules
Feb 23, 2024The availability of large annotated data can be a critical bottleneck in training machine learning algorithms successfully, especially when applied to diverse domains. Weak supervision offers a promising alternative by accelerating the creation of labeled training data using domain-specific rules. However, it requires users to write a diverse set of high-quality rules to assign labels to the unlabeled data. Automatic Rule Induction (ARI) approaches circumvent this problem by automatically creating rules from features on a small labeled set and filtering a final set of rules from them. In the ARI approach, the crucial step is to filter out a set of a high-quality useful subset of rules from the large set of automatically created rules. In this paper, we propose an algorithm (Filtering of Automatically Induced Rules) to filter rules from a large number of automatically induced rules using submodular objective functions that account for the collective precision, coverage, and conflicts of the rule set. We experiment with three ARI approaches and five text classification datasets to validate the superior performance of our algorithm with respect to several semi-supervised label aggregation approaches. Further, we show that achieves statistically significant results in comparison to existing rule-filtering approaches.
EIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023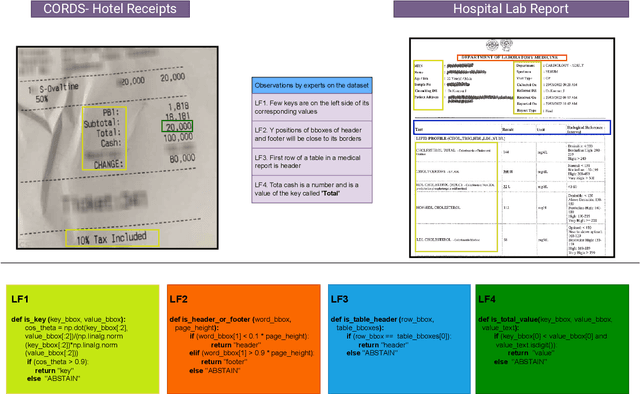



Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.
Sāmayik: A Benchmark and Dataset for English-Sanskrit Translation
May 23, 2023

Sanskrit is a low-resource language with a rich heritage. Digitized Sanskrit corpora reflective of the contemporary usage of Sanskrit, specifically that too in prose, is heavily under-represented at present. Presently, no such English-Sanskrit parallel dataset is publicly available. We release a dataset, S\={a}mayik, of more than 42,000 parallel English-Sanskrit sentences, from four different corpora that aim to bridge this gap. Moreover, we also release benchmarks adapted from existing multilingual pretrained models for Sanskrit-English translation. We include training splits from our contemporary dataset and the Sanskrit-English parallel sentences from the training split of Itih\={a}sa, a previously released classical era machine translation dataset containing Sanskrit.
A Benchmark and Dataset for Post-OCR text correction in Sanskrit
Nov 15, 2022



Sanskrit is a classical language with about 30 million extant manuscripts fit for digitisation, available in written, printed or scannedimage forms. However, it is still considered to be a low-resource language when it comes to available digital resources. In this work, we release a post-OCR text correction dataset containing around 218,000 sentences, with 1.5 million words, from 30 different books. Texts in Sanskrit are known to be diverse in terms of their linguistic and stylistic usage since Sanskrit was the 'lingua franca' for discourse in the Indian subcontinent for about 3 millennia. Keeping this in mind, we release a multi-domain dataset, from areas as diverse as astronomy, medicine and mathematics, with some of them as old as 18 centuries. Further, we release multiple strong baselines as benchmarks for the task, based on pre-trained Seq2Seq language models. We find that our best-performing model, consisting of byte level tokenization in conjunction with phonetic encoding (Byt5+SLP1), yields a 23% point increase over the OCR output in terms of word and character error rates. Moreover, we perform extensive experiments in evaluating these models on their performance and analyse common causes of mispredictions both at the graphemic and lexical levels. Our code and dataset is publicly available at https://github.com/ayushbits/pe-ocr-sanskrit.
DICTDIS: Dictionary Constrained Disambiguation for Improved NMT
Oct 13, 2022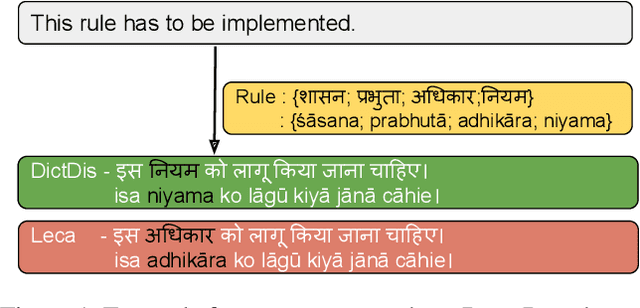
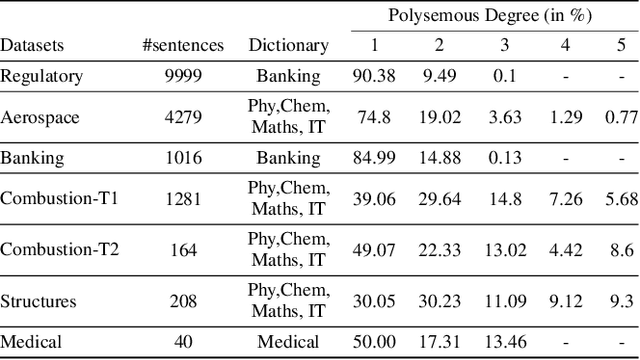

Domain-specific neural machine translation (NMT) systems (e.g., in educational applications) are socially significant with the potential to help make information accessible to a diverse set of users in multilingual societies. It is desirable that such NMT systems be lexically constrained and draw from domain-specific dictionaries. Dictionaries could present multiple candidate translations for a source words/phrases on account of the polysemous nature of words. The onus is then on the NMT model to choose the contextually most appropriate candidate. Prior work has largely ignored this problem and focused on the single candidate setting where the target word or phrase is replaced by a single constraint. In this work we present DICTDIS, a lexically constrained NMT system that disambiguates between multiple candidate translations derived from dictionaries. We achieve this by augmenting training data with multiple dictionary candidates to actively encourage disambiguation during training. We demonstrate the utility of DICTDIS via extensive experiments on English-Hindi sentences in a variety of domains including news, finance, medicine and engineering. We obtain superior disambiguation performance on all domains with improved fluency in some domains of up to 4 BLEU points, when compared with existing approaches for lexically constrained and unconstrained NMT.
UDAAN - Machine Learning based Post-Editing tool for Document Translation
Mar 03, 2022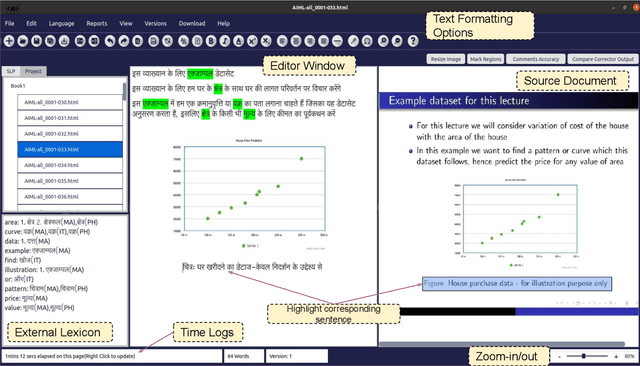
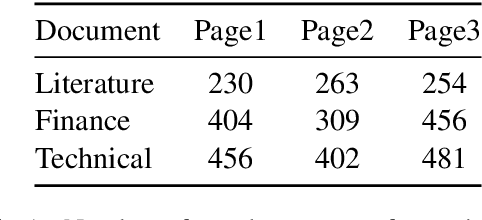
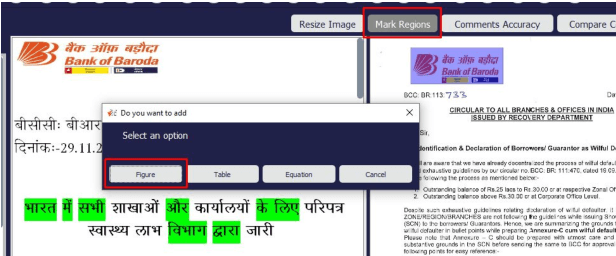
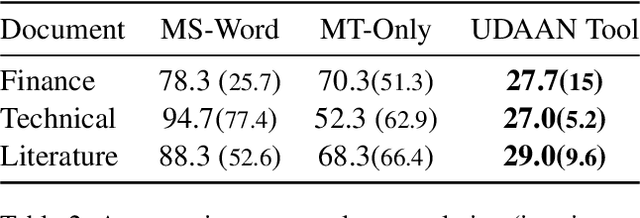
We introduce UDAAN, an open-source post-editing tool that can reduce manual editing efforts to quickly produce publishable-standard documents in different languages. UDAAN has an end-to-end Machine Translation (MT) plus post-editing pipeline wherein users can upload a document to obtain raw MT output. Further, users can edit the raw translations using our tool. UDAAN offers several advantages: a) Domain-aware, vocabulary-based lexical constrained MT. b) source-target and target-target lexicon suggestions for users. Replacements are based on the source and target texts lexicon alignment. c) Suggestions for translations are based on logs created during user interaction. d) Source-target sentence alignment visualisation that reduces the cognitive load of users during editing. e) Translated outputs from our tool are available in multiple formats: docs, latex, and PDF. Although we limit our experiments to English-to-Hindi translation for the current study, our tool is independent of the source and target languages. Experimental results based on the usage of the tools and users feedback show that our tool speeds up the translation time approximately by a factor of three compared to the baseline method of translating documents from scratch.
Error Correction in ASR using Sequence-to-Sequence Models
Feb 02, 2022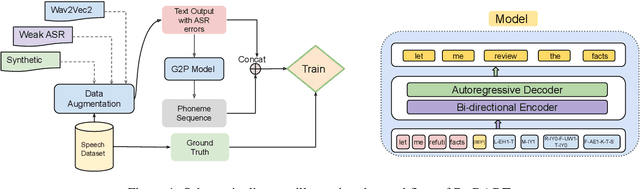


Post-editing in Automatic Speech Recognition (ASR) entails automatically correcting common and systematic errors produced by the ASR system. The outputs of an ASR system are largely prone to phonetic and spelling errors. In this paper, we propose to use a powerful pre-trained sequence-to-sequence model, BART, further adaptively trained to serve as a denoising model, to correct errors of such types. The adaptive training is performed on an augmented dataset obtained by synthetically inducing errors as well as by incorporating actual errors from an existing ASR system. We also propose a simple approach to rescore the outputs using word level alignments. Experimental results on accented speech data demonstrate that our strategy effectively rectifies a significant number of ASR errors and produces improved WER results when compared against a competitive baseline.