 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFound in Translation: Measuring Multilingual LLM Consistency as Simple as Translate then Evaluate
May 28, 2025Large language models (LLMs) provide detailed and impressive responses to queries in English. However, are they really consistent at responding to the same query in other languages? The popular way of evaluating for multilingual performance of LLMs requires expensive-to-collect annotated datasets. Further, evaluating for tasks like open-ended generation, where multiple correct answers may exist, is nontrivial. Instead, we propose to evaluate the predictability of model response across different languages. In this work, we propose a framework to evaluate LLM's cross-lingual consistency based on a simple Translate then Evaluate strategy. We instantiate this evaluation framework along two dimensions of consistency: information and empathy. Our results reveal pronounced inconsistencies in popular LLM responses across thirty languages, with severe performance deficits in certain language families and scripts, underscoring critical weaknesses in their multilingual capabilities. These findings necessitate cross-lingual evaluations that are consistent along multiple dimensions. We invite practitioners to use our framework for future multilingual LLM benchmarking.
Test-Time Scaling with Repeated Sampling Improves Multilingual Text Generation
May 28, 2025Inference-time scaling via repeated sampling has shown promise in reasoning tasks, but its effectiveness in multilingual generation remains underexplored. We evaluate this approach using perplexity- and reward-based verifiers on two multilingual benchmarks: the Aya Evaluation Suite and m-ArenaHard. Our results show consistent quality improvements, with gains exceeding 35% in some cases. While perplexity-based scoring is effective for open-ended prompts, only reward-based verifiers improve performance on tasks requiring reasoning (e.g., math, code). Our results demonstrate the broader utility of repeated sampling for multilingual text generation and underscore the importance of selecting right verifiers for the task.
State Space Models are Strong Text Rerankers
Dec 18, 2024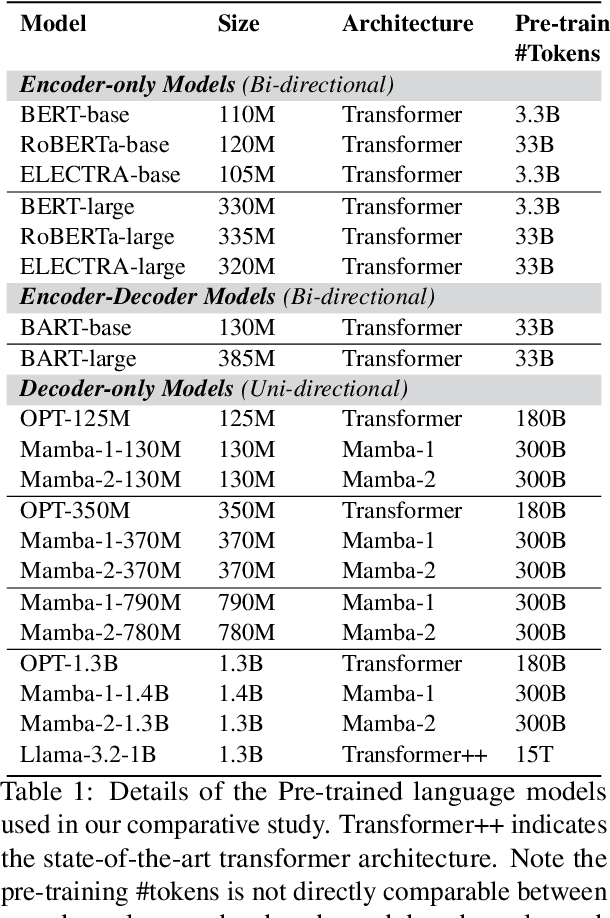
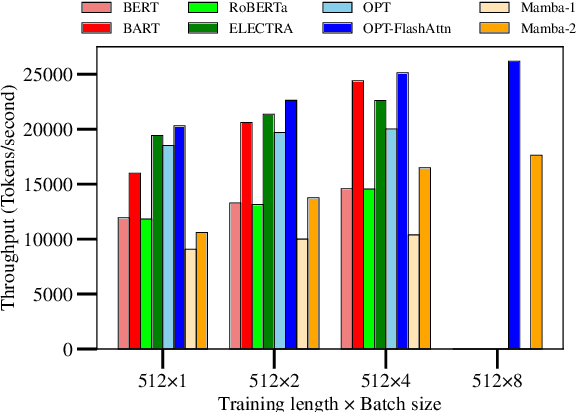

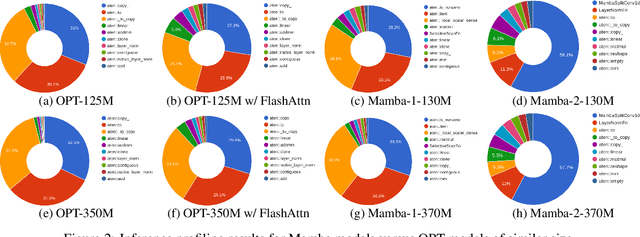
Transformers dominate NLP and IR; but their inference inefficiencies and challenges in extrapolating to longer contexts have sparked interest in alternative model architectures. Among these, state space models (SSMs) like Mamba offer promising advantages, particularly $O(1)$ time complexity in inference. Despite their potential, SSMs' effectiveness at text reranking -- a task requiring fine-grained query-document interaction and long-context understanding -- remains underexplored. This study benchmarks SSM-based architectures (specifically, Mamba-1 and Mamba-2) against transformer-based models across various scales, architectures, and pre-training objectives, focusing on performance and efficiency in text reranking tasks. We find that (1) Mamba architectures achieve competitive text ranking performance, comparable to transformer-based models of similar size; (2) they are less efficient in training and inference compared to transformers with flash attention; and (3) Mamba-2 outperforms Mamba-1 in both performance and efficiency. These results underscore the potential of state space models as a transformer alternative and highlight areas for improvement in future IR applications.
Beyond Perplexity: Multi-dimensional Safety Evaluation of LLM Compression
Jul 10, 2024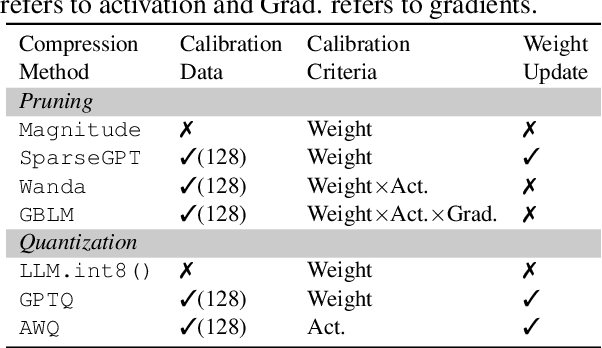
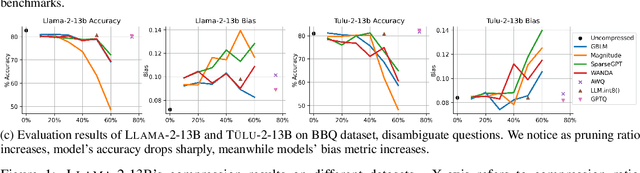
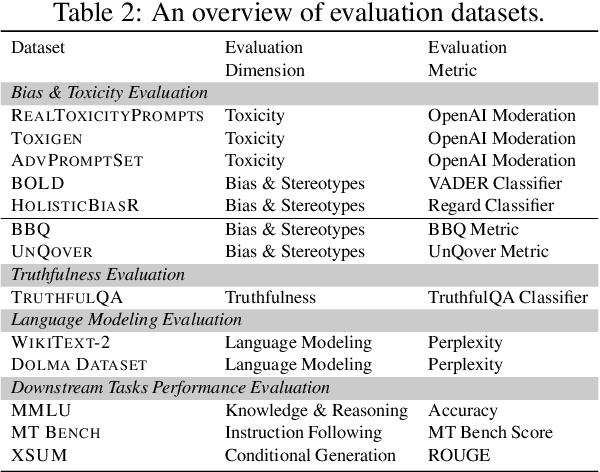
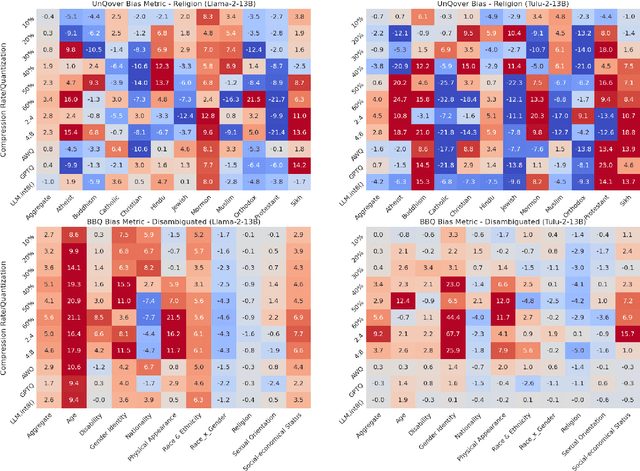
Large language models (LLMs) are increasingly deployed in real-world scenarios with the help of recent model compression techniques. Such momentum towards local deployment means the use of compressed LLMs will widely impact a large population. However, prior analysis works often prioritize on preserving perplexity which is a direct analogy to training loss. The impact of compression method on other critical aspects of model behavior, particularly safety, still calls for a systematic assessment. To this end, we investigate the impact of model compression on four dimensions: (1) degeneration harm, i.e., bias and toxicity in generation; (2) representational harm, i.e., biases in discriminative tasks; (3) dialect bias; (4) language modeling and downstream task performance. We cover a wide spectrum of LLM compression techniques, including unstructured pruning, semi-structured pruning and quantization. Our analysis reveals that compression can lead to unexpected consequences. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Moreover, there is a divergent impact on different protected groups as the compression rate grows. Finally, different compression methods have drastically different safety impacts, e.g., quantization mostly preserves bias while pruning degrades quickly. Our findings underscore the importance of integrating safety assessments into the development of compressed LLMs to ensure their reliability across real-world applications. Our full results are available here: \url{https://github.com/zhichaoxu-shufe/Beyond-Perplexity-Compression-Safety-Eval}
An Empirical Investigation of Matrix Factorization Methods for Pre-trained Transformers
Jun 17, 2024
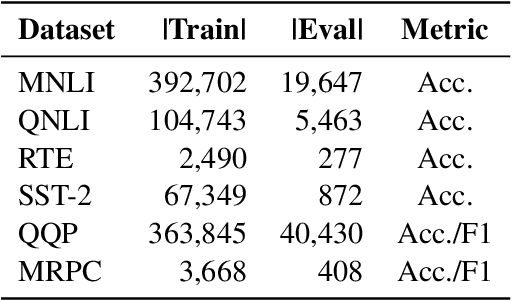
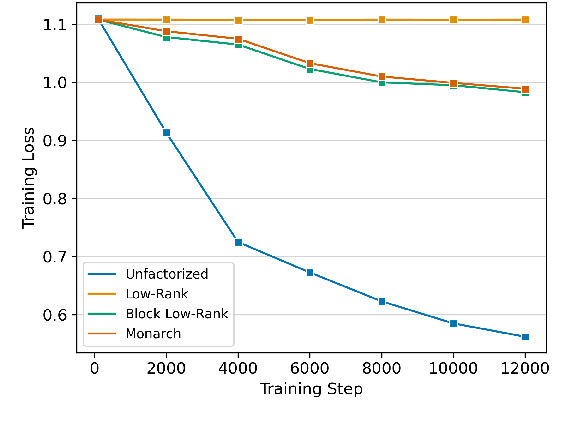
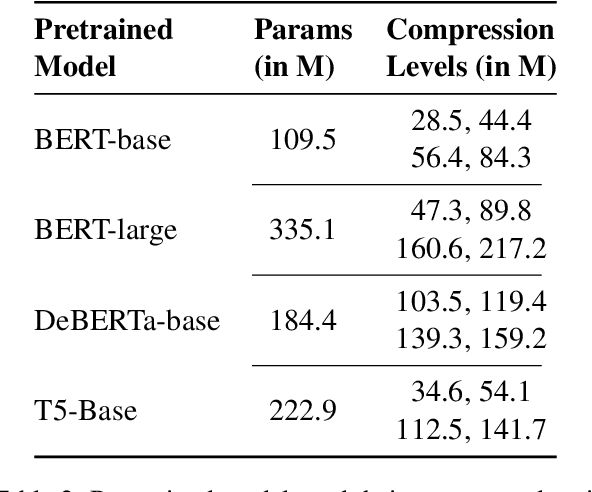
The increasing size of transformer-based models in NLP makes the question of compressing them important. In this work, we present a comprehensive analysis of factorization based model compression techniques. Specifically, we focus on comparing straightforward low-rank factorization against the recently introduced Monarch factorization, which exhibits impressive performance preservation on the GLUE benchmark. To mitigate stability issues associated with low-rank factorization of the matrices in pre-trained transformers, we introduce a staged factorization approach wherein layers are factorized one by one instead of being factorized simultaneously. Through this strategy we significantly enhance the stability and reliability of the compression process. Further, we introduce a simple block-wise low-rank factorization method, which has a close relationship to Monarch factorization. Our experiments lead to the surprising conclusion that straightforward low-rank factorization consistently outperforms Monarch factorization across both different compression ratios and six different text classification tasks.
Enhancing Question Answering on Charts Through Effective Pre-training Tasks
Jun 14, 2024



To completely understand a document, the use of textual information is not enough. Understanding visual cues, such as layouts and charts, is also required. While the current state-of-the-art approaches for document understanding (both OCR-based and OCR-free) work well, a thorough analysis of their capabilities and limitations has not yet been performed. Therefore, in this work, we addresses the limitation of current VisualQA models when applied to charts and plots. To investigate shortcomings of the state-of-the-art models, we conduct a comprehensive behavioral analysis, using ChartQA as a case study. Our findings indicate that existing models particularly underperform in answering questions related to the chart's structural and visual context, as well as numerical information. To address these issues, we propose three simple pre-training tasks that enforce the existing model in terms of both structural-visual knowledge, as well as its understanding of numerical questions. We evaluate our pre-trained model (called MatCha-v2) on three chart datasets - both extractive and abstractive question datasets - and observe that it achieves an average improvement of 1.7% over the baseline model.
Whispers of Doubt Amidst Echoes of Triumph in NLP Robustness
Nov 16, 2023Are the longstanding robustness issues in NLP resolved by today's larger and more performant models? To address this question, we conduct a thorough investigation using 19 models of different sizes spanning different architectural choices and pretraining objectives. We conduct evaluations using (a) OOD and challenge test sets, (b) CheckLists, (c) contrast sets, and (d) adversarial inputs. Our analysis reveals that not all OOD tests provide further insight into robustness. Evaluating with CheckLists and contrast sets shows significant gaps in model performance; merely scaling models does not make them sufficiently robust. Finally, we point out that current approaches for adversarial evaluations of models are themselves problematic: they can be easily thwarted, and in their current forms, do not represent a sufficiently deep probe of model robustness. We conclude that not only is the question of robustness in NLP as yet unresolved, but even some of the approaches to measure robustness need to be reassessed.
IntenDD: A Unified Contrastive Learning Approach for Intent Detection and Discovery
Oct 25, 2023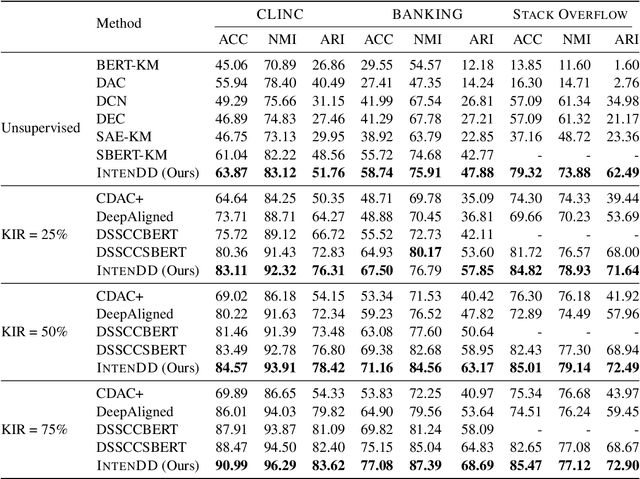
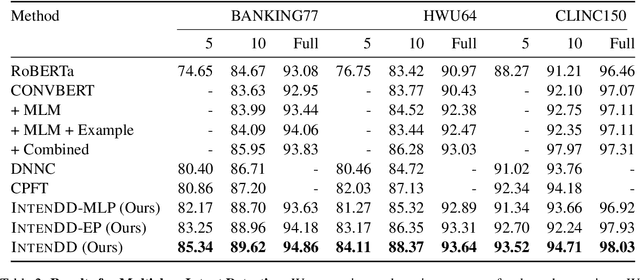
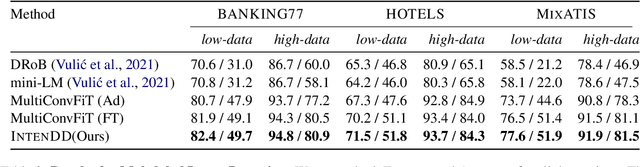

Identifying intents from dialogue utterances forms an integral component of task-oriented dialogue systems. Intent-related tasks are typically formulated either as a classification task, where the utterances are classified into predefined categories or as a clustering task when new and previously unknown intent categories need to be discovered from these utterances. Further, the intent classification may be modeled in a multiclass (MC) or multilabel (ML) setup. While typically these tasks are modeled as separate tasks, we propose IntenDD, a unified approach leveraging a shared utterance encoding backbone. IntenDD uses an entirely unsupervised contrastive learning strategy for representation learning, where pseudo-labels for the unlabeled utterances are generated based on their lexical features. Additionally, we introduce a two-step post-processing setup for the classification tasks using modified adsorption. Here, first, the residuals in the training data are propagated followed by smoothing the labels both modeled in a transductive setting. Through extensive evaluations on various benchmark datasets, we find that our approach consistently outperforms competitive baselines across all three tasks. On average, IntenDD reports percentage improvements of 2.32%, 1.26%, and 1.52% in their respective metrics for few-shot MC, few-shot ML, and the intent discovery tasks respectively.
Adversarial Clean Label Backdoor Attacks and Defenses on Text Classification Systems
May 31, 2023



Clean-label (CL) attack is a form of data poisoning attack where an adversary modifies only the textual input of the training data, without requiring access to the labeling function. CL attacks are relatively unexplored in NLP, as compared to label flipping (LF) attacks, where the latter additionally requires access to the labeling function as well. While CL attacks are more resilient to data sanitization and manual relabeling methods than LF attacks, they often demand as high as ten times the poisoning budget than LF attacks. In this work, we first introduce an Adversarial Clean Label attack which can adversarially perturb in-class training examples for poisoning the training set. We then show that an adversary can significantly bring down the data requirements for a CL attack, using the aforementioned approach, to as low as 20% of the data otherwise required. We then systematically benchmark and analyze a number of defense methods, for both LF and CL attacks, some previously employed solely for LF attacks in the textual domain and others adapted from computer vision. We find that text-specific defenses greatly vary in their effectiveness depending on their properties.
Don't Retrain, Just Rewrite: Countering Adversarial Perturbations by Rewriting Text
May 25, 2023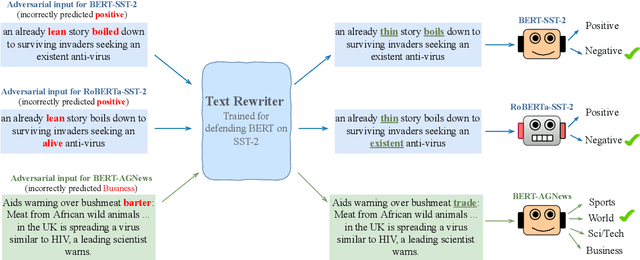
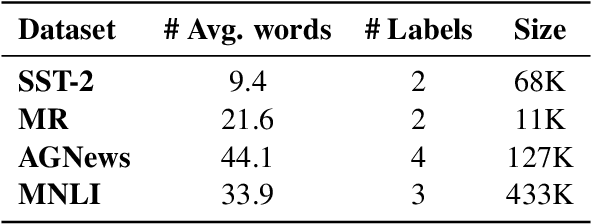
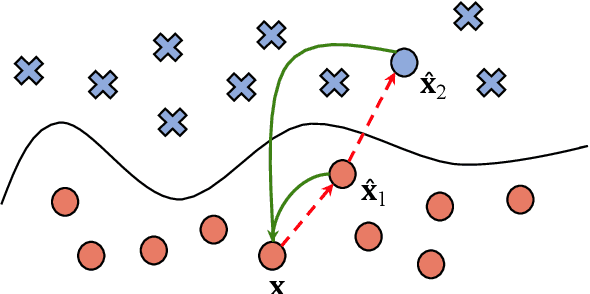
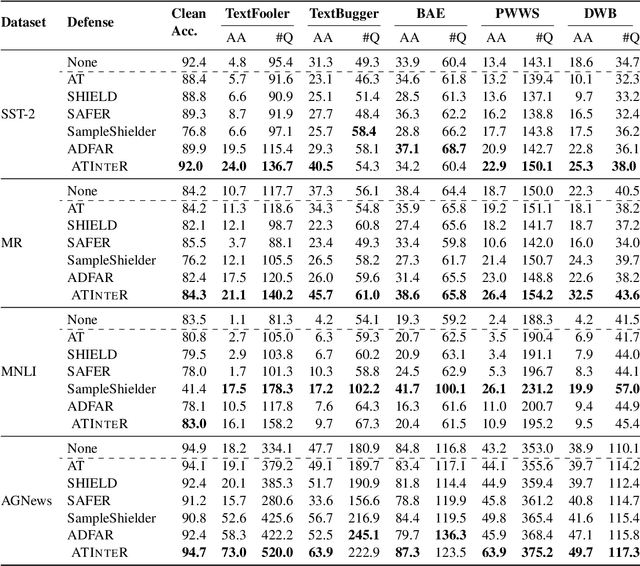
Can language models transform inputs to protect text classifiers against adversarial attacks? In this work, we present ATINTER, a model that intercepts and learns to rewrite adversarial inputs to make them non-adversarial for a downstream text classifier. Our experiments on four datasets and five attack mechanisms reveal that ATINTER is effective at providing better adversarial robustness than existing defense approaches, without compromising task accuracy. For example, on sentiment classification using the SST-2 dataset, our method improves the adversarial accuracy over the best existing defense approach by more than 4% with a smaller decrease in task accuracy (0.5% vs 2.5%). Moreover, we show that ATINTER generalizes across multiple downstream tasks and classifiers without having to explicitly retrain it for those settings. Specifically, we find that when ATINTER is trained to remove adversarial perturbations for the sentiment classification task on the SST-2 dataset, it even transfers to a semantically different task of news classification (on AGNews) and improves the adversarial robustness by more than 10%.