 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Perplexity: Multi-dimensional Safety Evaluation of LLM Compression
Paper and Code
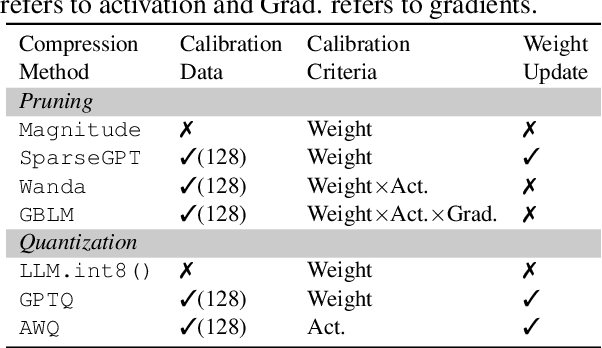
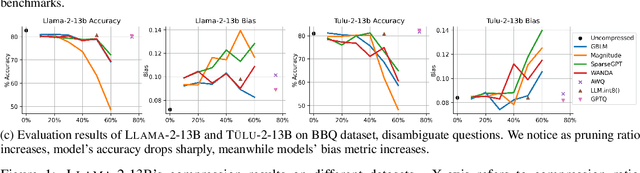
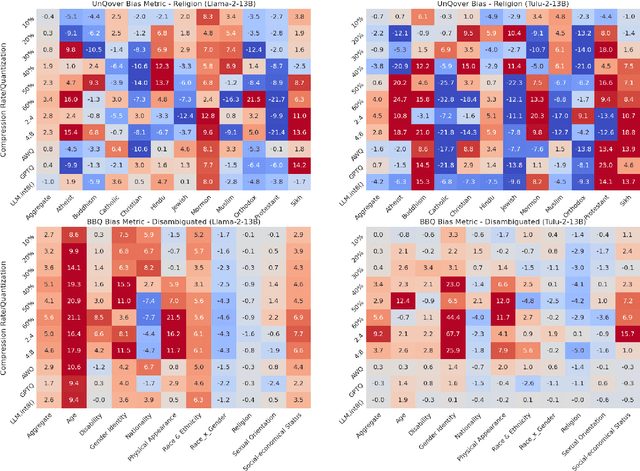
Large language models (LLMs) are increasingly deployed in real-world scenarios with the help of recent model compression techniques. Such momentum towards local deployment means the use of compressed LLMs will widely impact a large population. However, prior analysis works often prioritize on preserving perplexity which is a direct analogy to training loss. The impact of compression method on other critical aspects of model behavior, particularly safety, still calls for a systematic assessment. To this end, we investigate the impact of model compression on four dimensions: (1) degeneration harm, i.e., bias and toxicity in generation; (2) representational harm, i.e., biases in discriminative tasks; (3) dialect bias; (4) language modeling and downstream task performance. We cover a wide spectrum of LLM compression techniques, including unstructured pruning, semi-structured pruning and quantization. Our analysis reveals that compression can lead to unexpected consequences. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Moreover, there is a divergent impact on different protected groups as the compression rate grows. Finally, different compression methods have drastically different safety impacts, e.g., quantization mostly preserves bias while pruning degrades quickly. Our findings underscore the importance of integrating safety assessments into the development of compressed LLMs to ensure their reliability across real-world applications. Our full results are available here: \url{https://github.com/zhichaoxu-shufe/Beyond-Perplexity-Compression-Safety-Eval}