 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLACONIC: Dense-Level Effectiveness for Scalable Sparse Retrieval via a Two-Phase Training Curriculum
Jan 04, 2026While dense retrieval models have become the standard for state-of-the-art information retrieval, their deployment is often constrained by high memory requirements and reliance on GPU accelerators for vector similarity search. Learned sparse retrieval offers a compelling alternative by enabling efficient search via inverted indices, yet it has historically received less attention than dense approaches. In this report, we introduce LACONIC, a family of learned sparse retrievers based on the Llama-3 architecture (1B, 3B, and 8B). We propose a streamlined two-phase training curriculum consisting of (1) weakly supervised pre-finetuning to adapt causal LLMs for bidirectional contextualization and (2) high-signal finetuning using curated hard negatives. Our results demonstrate that LACONIC effectively bridges the performance gap with dense models: the 8B variant achieves a state-of-the-art 60.2 nDCG on the MTEB Retrieval benchmark, ranking 15th on the leaderboard as of January 1, 2026, while utilizing 71\% less index memory than an equivalent dense model. By delivering high retrieval effectiveness on commodity CPU hardware with a fraction of the compute budget required by competing models, LACONIC provides a scalable and efficient solution for real-world search applications.
Reinforcing Code Generation: Improving Text-to-SQL with Execution-Based Learning
Jun 06, 2025In this work, we study the problem of code generation with a large language model (LLM), with a focus on generating SQL queries from natural language questions. We ask: Instead of using supervised fine tuning with text-code pairs, can we tune a model by having it interact with a database engine? We frame this problem as a reinforcement learning problem where the model receives execution-based feedback from the environment in the form of scalar rewards. These rewards penalize execution failures and assign positive values when a query returns a correct answer. We use the rewards within the Group Relative Policy Optimization (GRPO) framework. We use a tabular reasoning benchmark to test and evaluate our findings. We find that with only weak supervision in the form of question-answer pairs, RL-tuning improves the accuracy of model generated SQL code from 31.49 to 49.83 while reducing error percentage from 25.43% to 14.71%. This improvement allowed the model nearly match the performance performance to the larger SQLCoder-70B model. Our work demonstrates the potential of using execution-based feedback to improve symbolic reasoning capabilities of LLMs.
LLM-Symbolic Integration for Robust Temporal Tabular Reasoning
Jun 06, 2025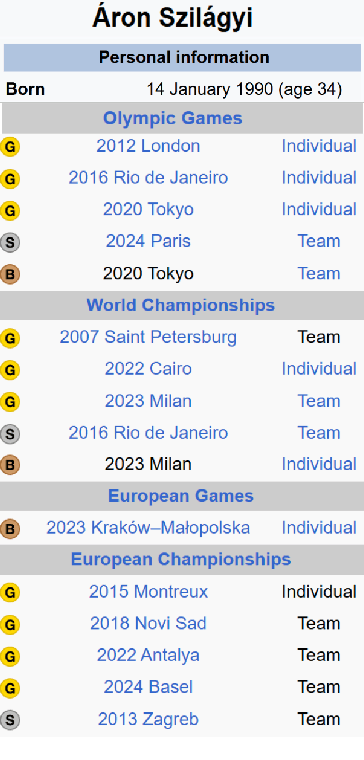
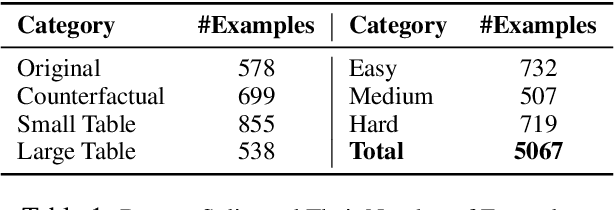
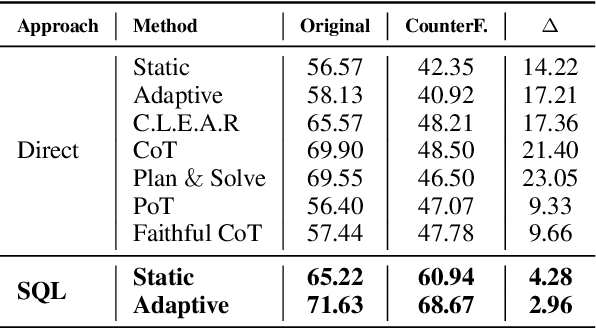
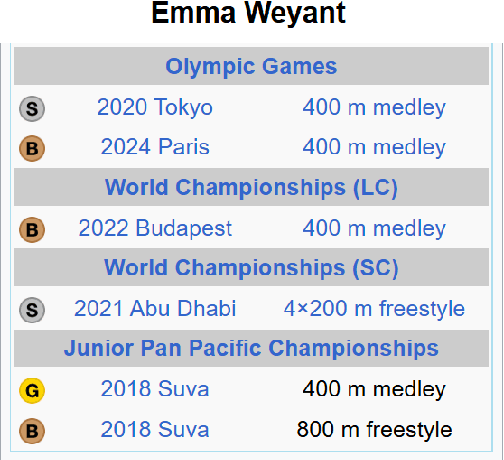
Temporal tabular question answering presents a significant challenge for Large Language Models (LLMs), requiring robust reasoning over structured data, which is a task where traditional prompting methods often fall short. These methods face challenges such as memorization, sensitivity to table size, and reduced performance on complex queries. To overcome these limitations, we introduce TempTabQA-C, a synthetic dataset designed for systematic and controlled evaluations, alongside a symbolic intermediate representation that transforms tables into database schemas. This structured approach allows LLMs to generate and execute SQL queries, enhancing generalization and mitigating biases. By incorporating adaptive few-shot prompting with contextually tailored examples, our method achieves superior robustness, scalability, and performance. Experimental results consistently highlight improvements across key challenges, setting a new benchmark for robust temporal reasoning with LLMs.
Test-Time Scaling with Repeated Sampling Improves Multilingual Text Generation
May 28, 2025Inference-time scaling via repeated sampling has shown promise in reasoning tasks, but its effectiveness in multilingual generation remains underexplored. We evaluate this approach using perplexity- and reward-based verifiers on two multilingual benchmarks: the Aya Evaluation Suite and m-ArenaHard. Our results show consistent quality improvements, with gains exceeding 35% in some cases. While perplexity-based scoring is effective for open-ended prompts, only reward-based verifiers improve performance on tasks requiring reasoning (e.g., math, code). Our results demonstrate the broader utility of repeated sampling for multilingual text generation and underscore the importance of selecting right verifiers for the task.
Found in Translation: Measuring Multilingual LLM Consistency as Simple as Translate then Evaluate
May 28, 2025Large language models (LLMs) provide detailed and impressive responses to queries in English. However, are they really consistent at responding to the same query in other languages? The popular way of evaluating for multilingual performance of LLMs requires expensive-to-collect annotated datasets. Further, evaluating for tasks like open-ended generation, where multiple correct answers may exist, is nontrivial. Instead, we propose to evaluate the predictability of model response across different languages. In this work, we propose a framework to evaluate LLM's cross-lingual consistency based on a simple Translate then Evaluate strategy. We instantiate this evaluation framework along two dimensions of consistency: information and empathy. Our results reveal pronounced inconsistencies in popular LLM responses across thirty languages, with severe performance deficits in certain language families and scripts, underscoring critical weaknesses in their multilingual capabilities. These findings necessitate cross-lingual evaluations that are consistent along multiple dimensions. We invite practitioners to use our framework for future multilingual LLM benchmarking.
A Survey of Model Architectures in Information Retrieval
Feb 20, 2025This survey examines the evolution of model architectures in information retrieval (IR), focusing on two key aspects: backbone models for feature extraction and end-to-end system architectures for relevance estimation. The review intentionally separates architectural considerations from training methodologies to provide a focused analysis of structural innovations in IR systems.We trace the development from traditional term-based methods to modern neural approaches, particularly highlighting the impact of transformer-based models and subsequent large language models (LLMs). We conclude by discussing emerging challenges and future directions, including architectural optimizations for performance and scalability, handling of multimodal, multilingual data, and adaptation to novel application domains beyond traditional search paradigms.
Understanding the Logic of Direct Preference Alignment through Logic
Dec 23, 2024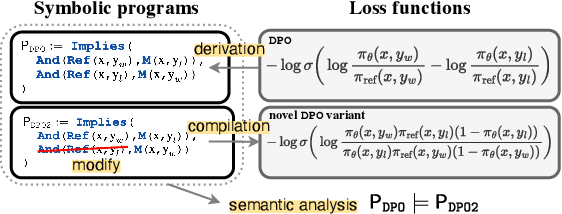


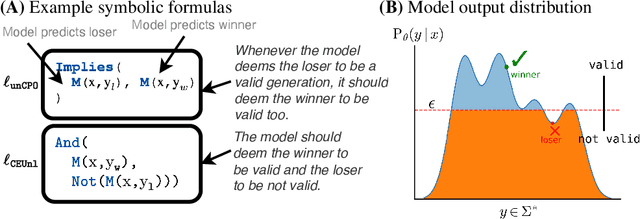
Recent direct preference alignment algorithms (DPA), such as DPO, have shown great promise in aligning large language models to human preferences. While this has motivated the development of many new variants of the original DPO loss, understanding the differences between these recent proposals, as well as developing new DPA loss functions, remains difficult given the lack of a technical and conceptual framework for reasoning about the underlying semantics of these algorithms. In this paper, we attempt to remedy this by formalizing DPA losses in terms of discrete reasoning problems. Specifically, we ask: Given an existing DPA loss, can we systematically derive a symbolic expression that characterizes its semantics? How do the semantics of two losses relate to each other? We propose a novel formalism for characterizing preference losses for single model and reference model based approaches, and identify symbolic forms for a number of commonly used DPA variants. Further, we show how this formal view of preference learning sheds new light on both the size and structure of the DPA loss landscape, making it possible to not only rigorously characterize the relationships between recent loss proposals but also to systematically explore the landscape and derive new loss functions from first principles. We hope our framework and findings will help provide useful guidance to those working on human AI alignment.
State Space Models are Strong Text Rerankers
Dec 18, 2024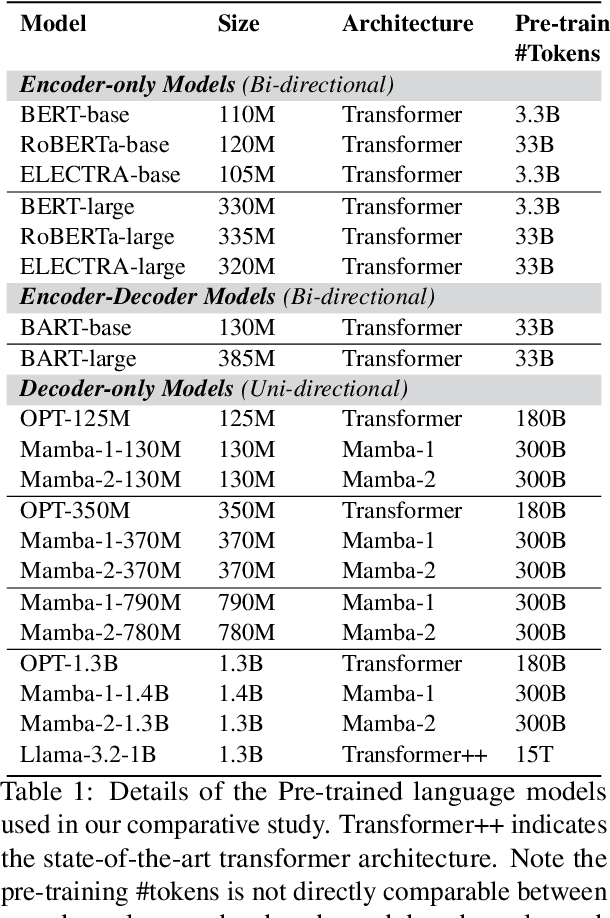
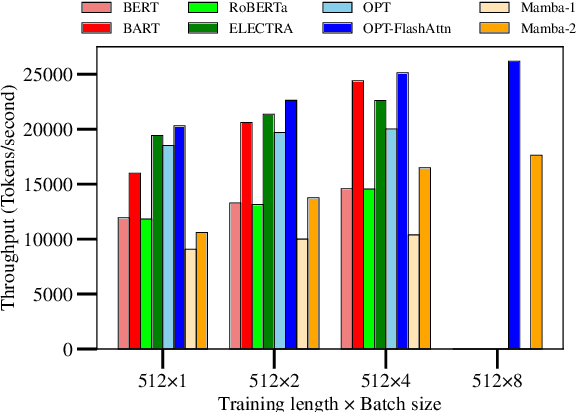

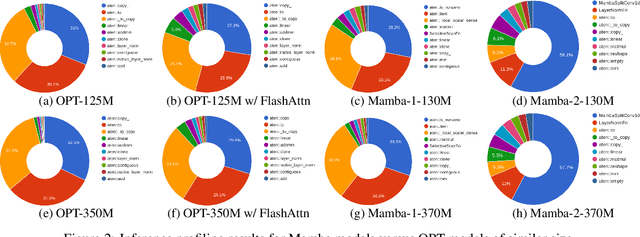
Transformers dominate NLP and IR; but their inference inefficiencies and challenges in extrapolating to longer contexts have sparked interest in alternative model architectures. Among these, state space models (SSMs) like Mamba offer promising advantages, particularly $O(1)$ time complexity in inference. Despite their potential, SSMs' effectiveness at text reranking -- a task requiring fine-grained query-document interaction and long-context understanding -- remains underexplored. This study benchmarks SSM-based architectures (specifically, Mamba-1 and Mamba-2) against transformer-based models across various scales, architectures, and pre-training objectives, focusing on performance and efficiency in text reranking tasks. We find that (1) Mamba architectures achieve competitive text ranking performance, comparable to transformer-based models of similar size; (2) they are less efficient in training and inference compared to transformers with flash attention; and (3) Mamba-2 outperforms Mamba-1 in both performance and efficiency. These results underscore the potential of state space models as a transformer alternative and highlight areas for improvement in future IR applications.
Beyond Perplexity: Multi-dimensional Safety Evaluation of LLM Compression
Jul 10, 2024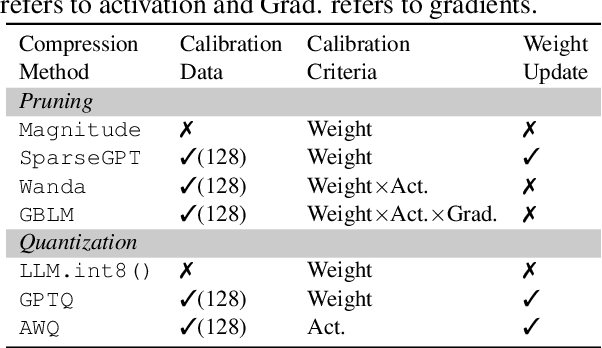
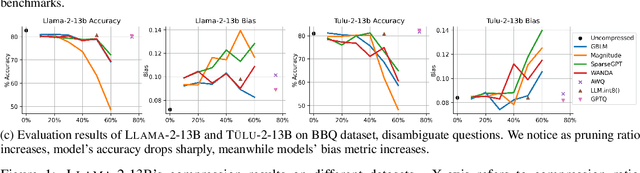
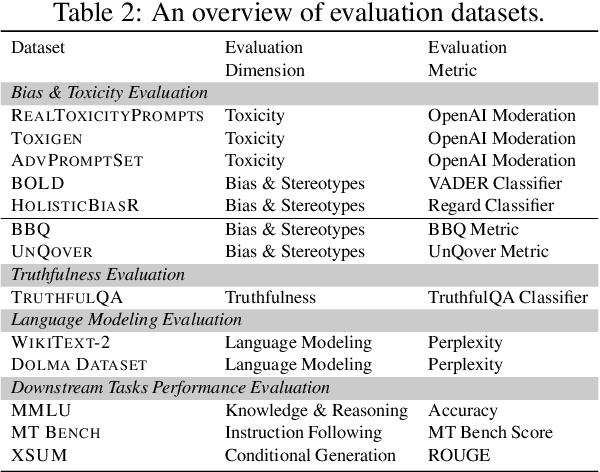
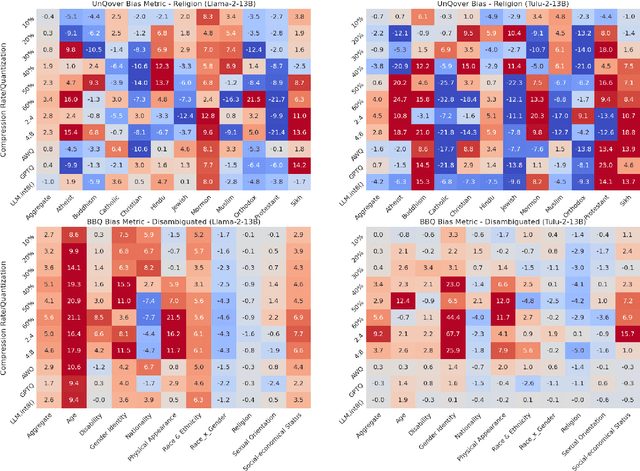
Large language models (LLMs) are increasingly deployed in real-world scenarios with the help of recent model compression techniques. Such momentum towards local deployment means the use of compressed LLMs will widely impact a large population. However, prior analysis works often prioritize on preserving perplexity which is a direct analogy to training loss. The impact of compression method on other critical aspects of model behavior, particularly safety, still calls for a systematic assessment. To this end, we investigate the impact of model compression on four dimensions: (1) degeneration harm, i.e., bias and toxicity in generation; (2) representational harm, i.e., biases in discriminative tasks; (3) dialect bias; (4) language modeling and downstream task performance. We cover a wide spectrum of LLM compression techniques, including unstructured pruning, semi-structured pruning and quantization. Our analysis reveals that compression can lead to unexpected consequences. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Although compression may unintentionally remedy LLMs' degeneration harm, it can still exacerbate on the representational harm axis. Moreover, there is a divergent impact on different protected groups as the compression rate grows. Finally, different compression methods have drastically different safety impacts, e.g., quantization mostly preserves bias while pruning degrades quickly. Our findings underscore the importance of integrating safety assessments into the development of compressed LLMs to ensure their reliability across real-world applications. Our full results are available here: \url{https://github.com/zhichaoxu-shufe/Beyond-Perplexity-Compression-Safety-Eval}
An Empirical Investigation of Matrix Factorization Methods for Pre-trained Transformers
Jun 17, 2024
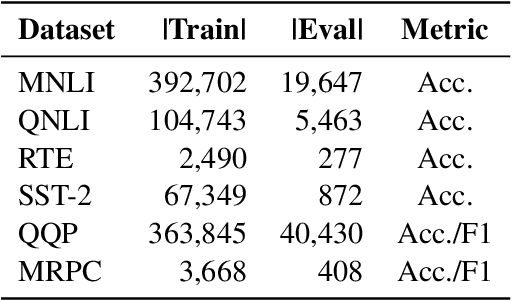
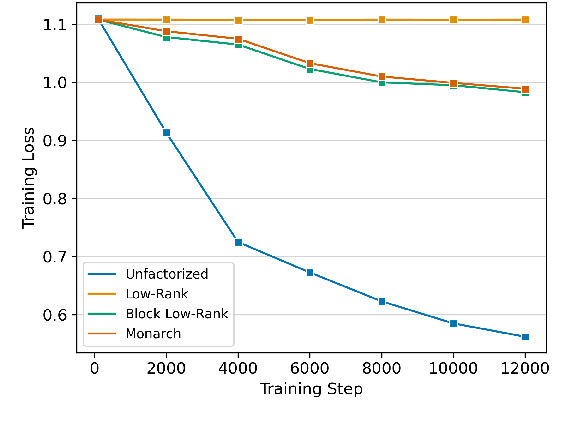
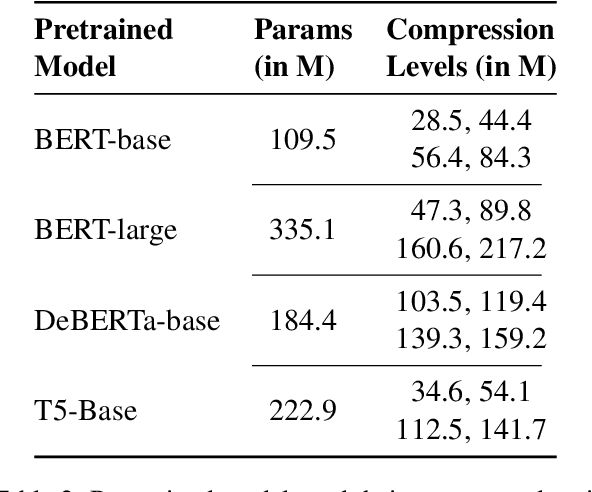
The increasing size of transformer-based models in NLP makes the question of compressing them important. In this work, we present a comprehensive analysis of factorization based model compression techniques. Specifically, we focus on comparing straightforward low-rank factorization against the recently introduced Monarch factorization, which exhibits impressive performance preservation on the GLUE benchmark. To mitigate stability issues associated with low-rank factorization of the matrices in pre-trained transformers, we introduce a staged factorization approach wherein layers are factorized one by one instead of being factorized simultaneously. Through this strategy we significantly enhance the stability and reliability of the compression process. Further, we introduce a simple block-wise low-rank factorization method, which has a close relationship to Monarch factorization. Our experiments lead to the surprising conclusion that straightforward low-rank factorization consistently outperforms Monarch factorization across both different compression ratios and six different text classification tasks.