 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching People LLM's Errors and Getting it Right
Dec 24, 2025



People use large language models (LLMs) when they should not. This is partly because they see LLMs compose poems and answer intricate questions, so they understandably, but incorrectly, assume LLMs won't stumble on basic tasks like simple arithmetic. Prior work has tried to address this by clustering instance embeddings into regions where an LLM is likely to fail and automatically describing patterns in these regions. The found failure patterns are taught to users to mitigate their overreliance. Yet, this approach has not fully succeeded. In this analysis paper, we aim to understand why. We first examine whether the negative result stems from the absence of failure patterns. We group instances in two datasets by their meta-labels and evaluate an LLM's predictions on these groups. We then define criteria to flag groups that are sizable and where the LLM is error-prone, and find meta-label groups that meet these criteria. Their meta-labels are the LLM's failure patterns that could be taught to users, so they do exist. We next test whether prompting and embedding-based approaches can surface these known failures. Without this, users cannot be taught about them to reduce their overreliance. We find mixed results across methods, which could explain the negative result. Finally, we revisit the final metric that measures teaching effectiveness. We propose to assess a user's ability to effectively use the given failure patterns to anticipate when an LLM is error-prone. A user study shows a positive effect from teaching with this metric, unlike the human-AI team accuracy. Our findings show that teaching failure patterns could be a viable approach to mitigating overreliance, but success depends on better automated failure-discovery methods and using metrics like ours.
Visual Exploration of Feature Relationships in Sparse Autoencoders with Curated Concepts
Nov 08, 2025Sparse autoencoders (SAEs) have emerged as a powerful tool for uncovering interpretable features in large language models (LLMs) through the sparse directions they learn. However, the sheer number of extracted directions makes comprehensive exploration intractable. While conventional embedding techniques such as UMAP can reveal global structure, they suffer from limitations including high-dimensional compression artifacts, overplotting, and misleading neighborhood distortions. In this work, we propose a focused exploration framework that prioritizes curated concepts and their corresponding SAE features over attempts to visualize all available features simultaneously. We present an interactive visualization system that combines topology-based visual encoding with dimensionality reduction to faithfully represent both local and global relationships among selected features. This hybrid approach enables users to investigate SAE behavior through targeted, interpretable subsets, facilitating deeper and more nuanced analysis of concept representation in latent space.
Metrics for Parametric Families of Networks
Sep 26, 2025We introduce a general framework for analyzing data modeled as parameterized families of networks. Building on a Gromov-Wasserstein variant of optimal transport, we define a family of parameterized Gromov-Wasserstein distances for comparing such parametric data, including time-varying metric spaces induced by collective motion, temporally evolving weighted social networks, and random graph models. We establish foundational properties of these distances, showing that they subsume several existing metrics in the literature, and derive theoretical approximation guarantees. In particular, we develop computationally tractable lower bounds and relate them to graph statistics commonly used in random graph theory. Furthermore, we prove that our distances can be consistently approximated in random graph and random metric space settings via empirical estimates from generative models. Finally, we demonstrate the practical utility of our framework through a series of numerical experiments.
Extracting Complex Topology from Multivariate Functional Approximation: Contours, Jacobi Sets, and Ridge-Valley Graphs
Aug 11, 2025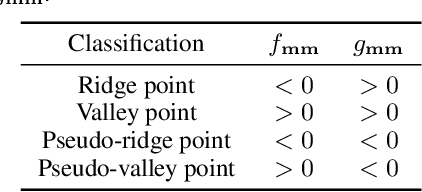
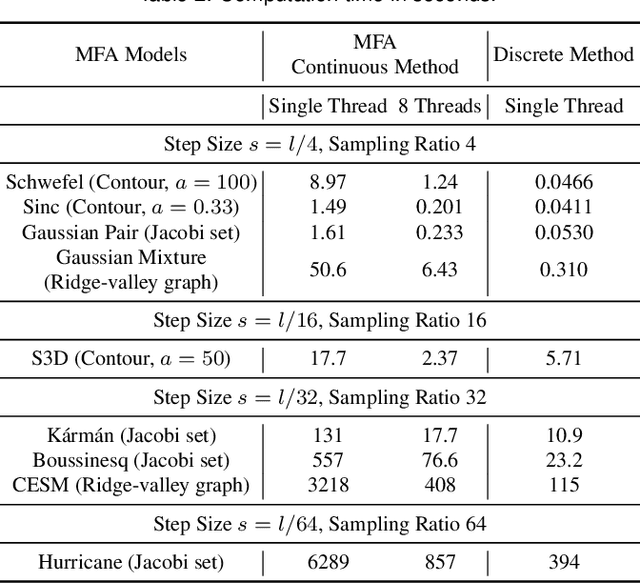
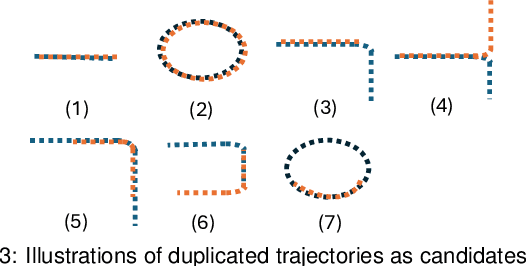
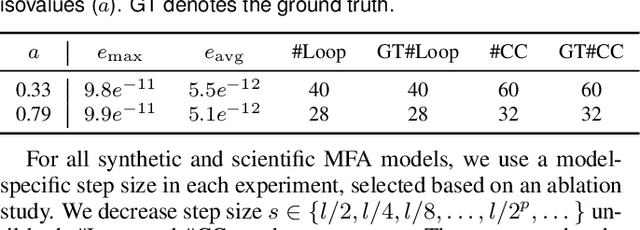
Implicit continuous models, such as functional models and implicit neural networks, are an increasingly popular method for replacing discrete data representations with continuous, high-order, and differentiable surrogates. These models offer new perspectives on the storage, transfer, and analysis of scientific data. In this paper, we introduce the first framework to directly extract complex topological features -- contours, Jacobi sets, and ridge-valley graphs -- from a type of continuous implicit model known as multivariate functional approximation (MFA). MFA replaces discrete data with continuous piecewise smooth functions. Given an MFA model as the input, our approach enables direct extraction of complex topological features from the model, without reverting to a discrete representation of the model. Our work is easily generalizable to any continuous implicit model that supports the queries of function values and high-order derivatives. Our work establishes the building blocks for performing topological data analysis and visualization on implicit continuous models.
Explainable Mapper: Charting LLM Embedding Spaces Using Perturbation-Based Explanation and Verification Agents
Jul 24, 2025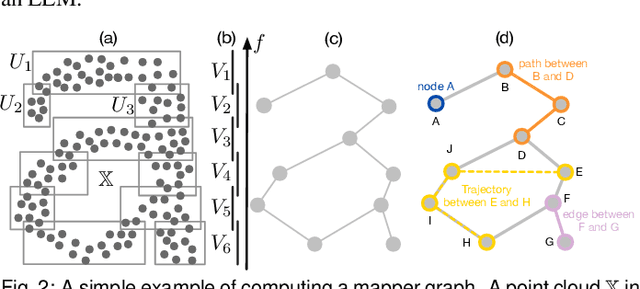
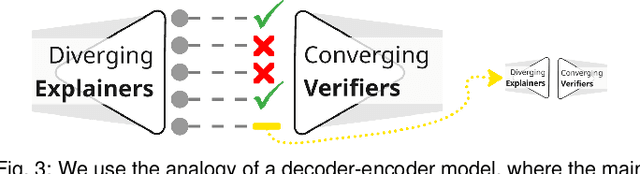
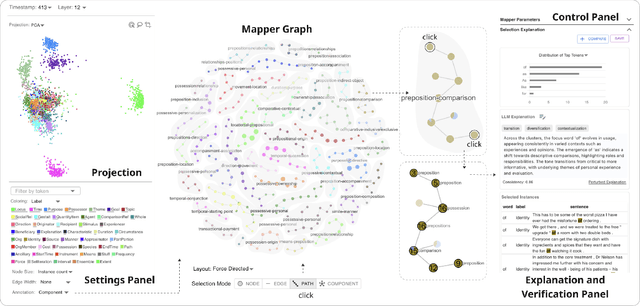
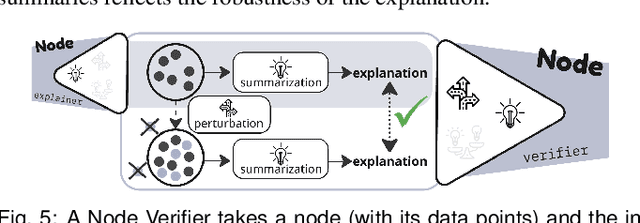
Large language models (LLMs) produce high-dimensional embeddings that capture rich semantic and syntactic relationships between words, sentences, and concepts. Investigating the topological structures of LLM embedding spaces via mapper graphs enables us to understand their underlying structures. Specifically, a mapper graph summarizes the topological structure of the embedding space, where each node represents a topological neighborhood (containing a cluster of embeddings), and an edge connects two nodes if their corresponding neighborhoods overlap. However, manually exploring these embedding spaces to uncover encoded linguistic properties requires considerable human effort. To address this challenge, we introduce a framework for semi-automatic annotation of these embedding properties. To organize the exploration process, we first define a taxonomy of explorable elements within a mapper graph such as nodes, edges, paths, components, and trajectories. The annotation of these elements is executed through two types of customizable LLM-based agents that employ perturbation techniques for scalable and automated analysis. These agents help to explore and explain the characteristics of mapper elements and verify the robustness of the generated explanations. We instantiate the framework within a visual analytics workspace and demonstrate its effectiveness through case studies. In particular, we replicate findings from prior research on BERT's embedding properties across various layers of its architecture and provide further observations into the linguistic properties of topological neighborhoods.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025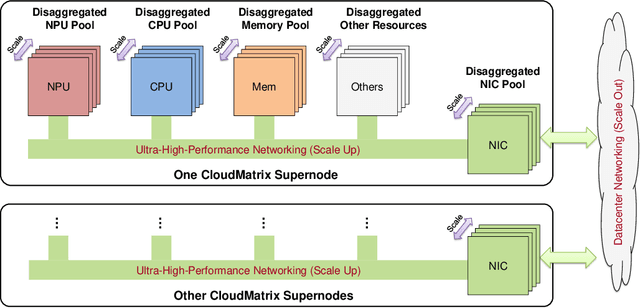
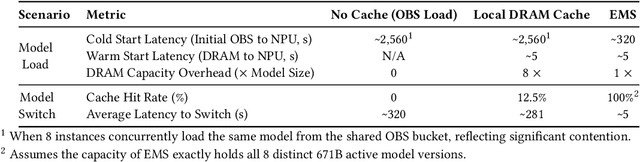
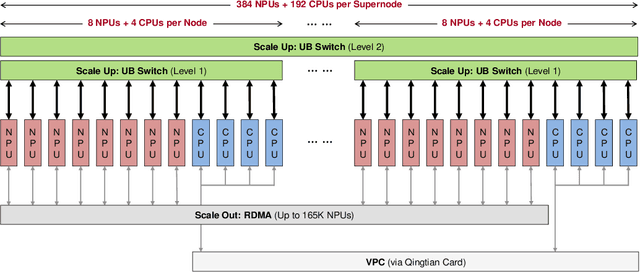
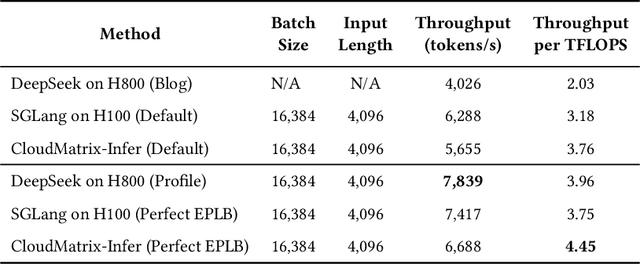
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
ChannelExplorer: Exploring Class Separability Through Activation Channel Visualization
May 06, 2025Deep neural networks (DNNs) achieve state-of-the-art performance in many vision tasks, yet understanding their internal behavior remains challenging, particularly how different layers and activation channels contribute to class separability. We introduce ChannelExplorer, an interactive visual analytics tool for analyzing image-based outputs across model layers, emphasizing data-driven insights over architecture analysis for exploring class separability. ChannelExplorer summarizes activations across layers and visualizes them using three primary coordinated views: a Scatterplot View to reveal inter- and intra-class confusion, a Jaccard Similarity View to quantify activation overlap, and a Heatmap View to inspect activation channel patterns. Our technique supports diverse model architectures, including CNNs, GANs, ResNet and Stable Diffusion models. We demonstrate the capabilities of ChannelExplorer through four use-case scenarios: (1) generating class hierarchy in ImageNet, (2) finding mislabeled images, (3) identifying activation channel contributions, and(4) locating latent states' position in Stable Diffusion model. Finally, we evaluate the tool with expert users.
VISLIX: An XAI Framework for Validating Vision Models with Slice Discovery and Analysis
May 06, 2025Real-world machine learning models require rigorous evaluation before deployment, especially in safety-critical domains like autonomous driving and surveillance. The evaluation of machine learning models often focuses on data slices, which are subsets of the data that share a set of characteristics. Data slice finding automatically identifies conditions or data subgroups where models underperform, aiding developers in mitigating performance issues. Despite its popularity and effectiveness, data slicing for vision model validation faces several challenges. First, data slicing often needs additional image metadata or visual concepts, and falls short in certain computer vision tasks, such as object detection. Second, understanding data slices is a labor-intensive and mentally demanding process that heavily relies on the expert's domain knowledge. Third, data slicing lacks a human-in-the-loop solution that allows experts to form hypothesis and test them interactively. To overcome these limitations and better support the machine learning operations lifecycle, we introduce VISLIX, a novel visual analytics framework that employs state-of-the-art foundation models to help domain experts analyze slices in computer vision models. Our approach does not require image metadata or visual concepts, automatically generates natural language insights, and allows users to test data slice hypothesis interactively. We evaluate VISLIX with an expert study and three use cases, that demonstrate the effectiveness of our tool in providing comprehensive insights for validating object detection models.
A Survey of Model Architectures in Information Retrieval
Feb 20, 2025This survey examines the evolution of model architectures in information retrieval (IR), focusing on two key aspects: backbone models for feature extraction and end-to-end system architectures for relevance estimation. The review intentionally separates architectural considerations from training methodologies to provide a focused analysis of structural innovations in IR systems.We trace the development from traditional term-based methods to modern neural approaches, particularly highlighting the impact of transformer-based models and subsequent large language models (LLMs). We conclude by discussing emerging challenges and future directions, including architectural optimizations for performance and scalability, handling of multimodal, multilingual data, and adaptation to novel application domains beyond traditional search paradigms.
Point Cloud Upsampling as Statistical Shape Model for Pelvic
Jan 28, 2025



We propose a novel framework that integrates medical image segmentation and point cloud upsampling for accurate shape reconstruction of pelvic models. Using the SAM-Med3D model for segmentation and a point cloud upsampling network trained on the MedShapeNet dataset, our method transforms sparse medical imaging data into high-resolution 3D bone models. This framework leverages prior knowledge of anatomical shapes, achieving smoother and more complete reconstructions. Quantitative evaluations using metrics such as Chamfer Distance etc, demonstrate the effectiveness of the point cloud upsampling in pelvic model. Our approach offers potential applications in reconstructing other skeletal structures, providing a robust solution for medical image analysis and statistical shape modeling.