 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISLIX: An XAI Framework for Validating Vision Models with Slice Discovery and Analysis
May 06, 2025Real-world machine learning models require rigorous evaluation before deployment, especially in safety-critical domains like autonomous driving and surveillance. The evaluation of machine learning models often focuses on data slices, which are subsets of the data that share a set of characteristics. Data slice finding automatically identifies conditions or data subgroups where models underperform, aiding developers in mitigating performance issues. Despite its popularity and effectiveness, data slicing for vision model validation faces several challenges. First, data slicing often needs additional image metadata or visual concepts, and falls short in certain computer vision tasks, such as object detection. Second, understanding data slices is a labor-intensive and mentally demanding process that heavily relies on the expert's domain knowledge. Third, data slicing lacks a human-in-the-loop solution that allows experts to form hypothesis and test them interactively. To overcome these limitations and better support the machine learning operations lifecycle, we introduce VISLIX, a novel visual analytics framework that employs state-of-the-art foundation models to help domain experts analyze slices in computer vision models. Our approach does not require image metadata or visual concepts, automatically generates natural language insights, and allows users to test data slice hypothesis interactively. We evaluate VISLIX with an expert study and three use cases, that demonstrate the effectiveness of our tool in providing comprehensive insights for validating object detection models.
MAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification
Nov 28, 2024Extending the capabilities of Large Language Models (LLMs) with functions or tools for environment interaction has led to the emergence of the agent paradigm. In industry, training an LLM is not always feasible because of the scarcity of domain data, legal holds on proprietary customer data, rapidly changing business requirements, and the need to prototype new assistants. Agents provide an elegant solution to the above by relying on the zero-shot reasoning abilities of the underlying LLM and utilizing tools to explore and reason over customer data and respond to user requests. However, there are two concerns here: (I) acquiring large scale customer queries for agent testing is time-consuming, and (II) high reliance on the tool call sequence (or trajectory) followed by the agent to respond to user queries may lead to unexpected or incorrect behavior. To address this, we propose MAG-V, a multi-agent framework to first generate a dataset of questions that mimic customer queries; and second, reverse-engineer alternate questions from the responses for trajectory verification. Initial results indicate that our synthetic data can improve agent performance on actual customer queries. Furthermore, our trajectory verification methodology, inspired by distant supervision and using traditional machine learning (ML) models, outperforms a GPT-4o judge baseline by 11% accuracy and matches the performance of a GPT-4 judge on our constructed dataset. Overall, our approach is a step towards unifying diverse task agents into a cohesive framework for achieving an aligned objective.
InFiConD: Interactive No-code Fine-tuning with Concept-based Knowledge Distillation
Jun 25, 2024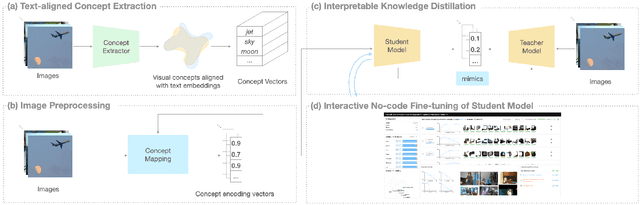
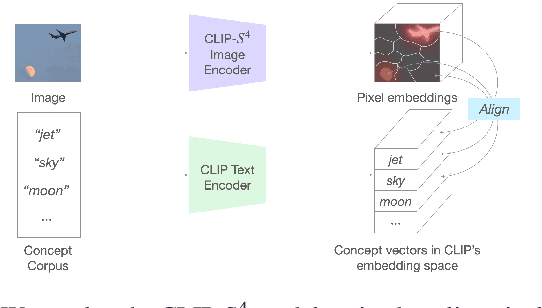
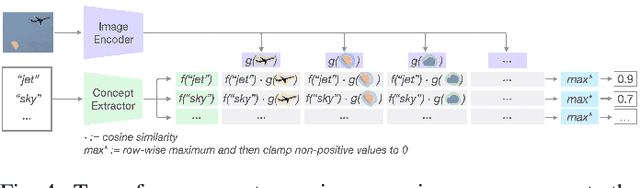
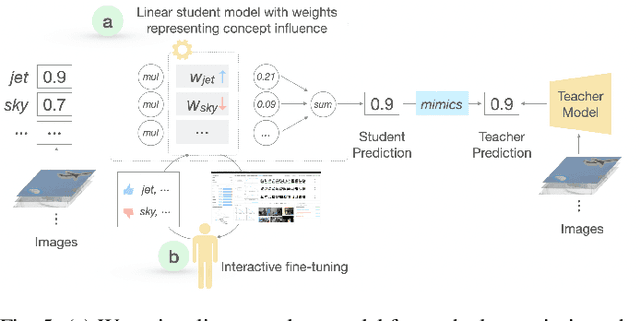
The emergence of large-scale pre-trained models has heightened their application in various downstream tasks, yet deployment is a challenge in environments with limited computational resources. Knowledge distillation has emerged as a solution in such scenarios, whereby knowledge from large teacher models is transferred into smaller student' models, but this is a non-trivial process that traditionally requires technical expertise in AI/ML. To address these challenges, this paper presents InFiConD, a novel framework that leverages visual concepts to implement the knowledge distillation process and enable subsequent no-code fine-tuning of student models. We develop a novel knowledge distillation pipeline based on extracting text-aligned visual concepts from a concept corpus using multimodal models, and construct highly interpretable linear student models based on visual concepts that mimic a teacher model in a response-based manner. InFiConD's interface allows users to interactively fine-tune the student model by manipulating concept influences directly in the user interface. We validate InFiConD via a robust usage scenario and user study. Our findings indicate that InFiConD's human-in-the-loop and visualization-driven approach enables users to effectively create and analyze student models, understand how knowledge is transferred, and efficiently perform fine-tuning operations. We discuss how this work highlights the potential of interactive and visual methods in making knowledge distillation and subsequent no-code fine-tuning more accessible and adaptable to a wider range of users with domain-specific demands.
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
A streamlined Approach to Multimodal Few-Shot Class Incremental Learning for Fine-Grained Datasets
Mar 10, 2024



Few-shot Class-Incremental Learning (FSCIL) poses the challenge of retaining prior knowledge while learning from limited new data streams, all without overfitting. The rise of Vision-Language models (VLMs) has unlocked numerous applications, leveraging their existing knowledge to fine-tune on custom data. However, training the whole model is computationally prohibitive, and VLMs while being versatile in general domains still struggle with fine-grained datasets crucial for many applications. We tackle these challenges with two proposed simple modules. The first, Session-Specific Prompts (SSP), enhances the separability of image-text embeddings across sessions. The second, Hyperbolic distance, compresses representations of image-text pairs within the same class while expanding those from different classes, leading to better representations. Experimental results demonstrate an average 10-point increase compared to baselines while requiring at least 8 times fewer trainable parameters. This improvement is further underscored on our three newly introduced fine-grained datasets.
AttributionScanner: A Visual Analytics System for Metadata-Free Data-Slicing Based Model Validation
Jan 12, 2024Data slice-finding is an emerging technique for evaluating machine learning models. It works by identifying subgroups within a specified dataset that exhibit poor performance, often defined by distinct feature sets or meta-information. However, in the context of unstructured image data, data slice-finding poses two notable challenges: it requires additional metadata -- a laborious and costly requirement, and also demands non-trivial efforts for interpreting the root causes of the underperformance within data slices. To address these challenges, we introduce AttributionScanner, an innovative human-in-the-loop Visual Analytics (VA) system, designed for data-slicing-based machine learning (ML) model validation. Our approach excels in identifying interpretable data slices, employing explainable features extracted through the lens of Explainable AI (XAI) techniques, and removing the necessity for additional metadata of textual annotations or cross-model embeddings. AttributionScanner demonstrates proficiency in pinpointing critical model issues, including spurious correlations and mislabeled data. Our novel VA interface visually summarizes data slices, enabling users to gather insights into model behavior patterns effortlessly. Furthermore, our framework closes the ML Development Cycle by empowering domain experts to address model issues by using a cutting-edge neural network regularization technique. The efficacy of AttributionScanner is underscored through two prototype use cases, elucidating its substantial effectiveness in model validation for vision-centric tasks. Our approach paves the way for ML researchers and practitioners to drive interpretable model validation in a data-efficient way, ultimately leading to more reliable and accurate models.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023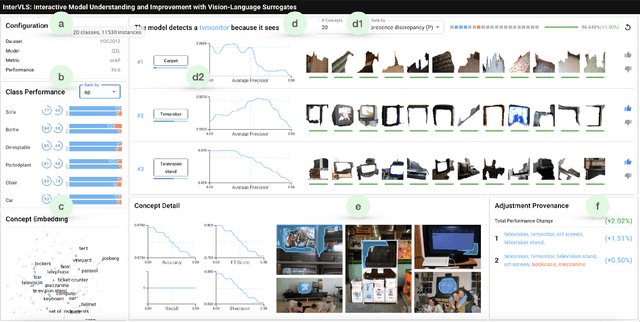
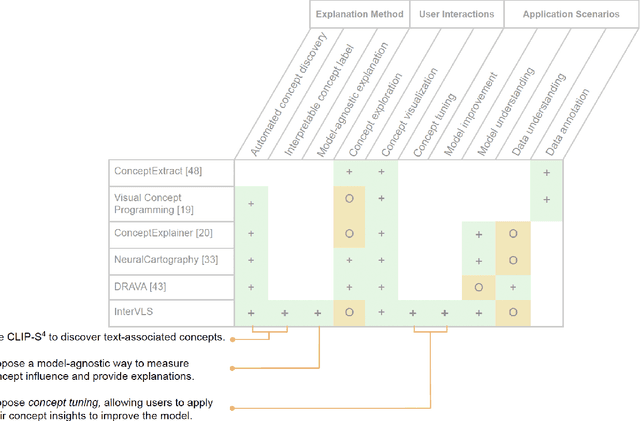
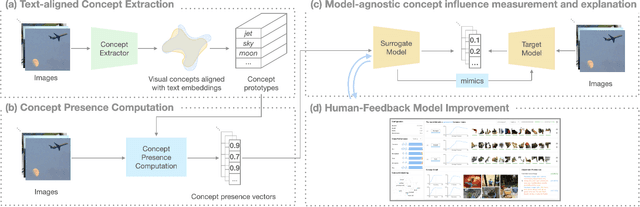
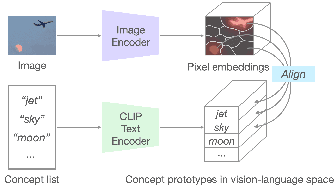
Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.
GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
Aug 01, 2023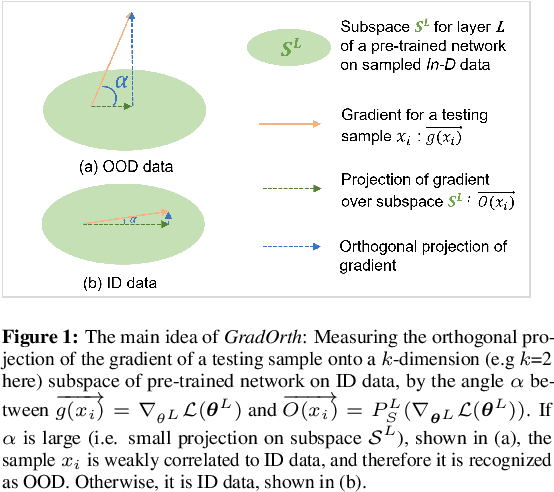
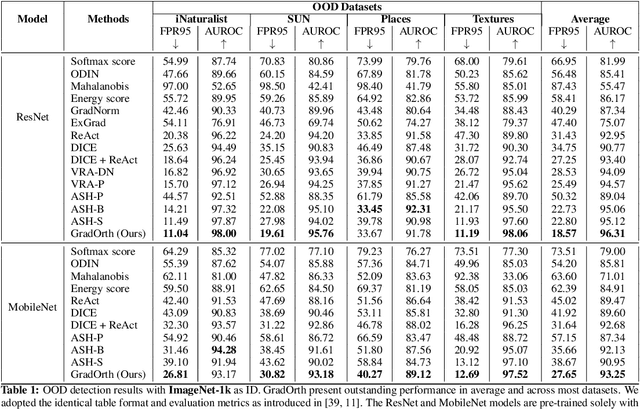

Detecting out-of-distribution (OOD) data is crucial for ensuring the safe deployment of machine learning models in real-world applications. However, existing OOD detection approaches primarily rely on the feature maps or the full gradient space information to derive OOD scores neglecting the role of most important parameters of the pre-trained network over in-distribution (ID) data. In this study, we propose a novel approach called GradOrth to facilitate OOD detection based on one intriguing observation that the important features to identify OOD data lie in the lower-rank subspace of in-distribution (ID) data. In particular, we identify OOD data by computing the norm of gradient projection on the subspaces considered important for the in-distribution data. A large orthogonal projection value (i.e. a small projection value) indicates the sample as OOD as it captures a weak correlation of the ID data. This simple yet effective method exhibits outstanding performance, showcasing a notable reduction in the average false positive rate at a 95% true positive rate (FPR95) of up to 8% when compared to the current state-of-the-art methods.
UP-DP: Unsupervised Prompt Learning for Data Pre-Selection with Vision-Language Models
Jul 20, 2023In this study, we investigate the task of data pre-selection, which aims to select instances for labeling from an unlabeled dataset through a single pass, thereby optimizing performance for undefined downstream tasks with a limited annotation budget. Previous approaches to data pre-selection relied solely on visual features extracted from foundation models, such as CLIP and BLIP-2, but largely ignored the powerfulness of text features. In this work, we argue that, with proper design, the joint feature space of both vision and text can yield a better representation for data pre-selection. To this end, we introduce UP-DP, a simple yet effective unsupervised prompt learning approach that adapts vision-language models, like BLIP-2, for data pre-selection. Specifically, with the BLIP-2 parameters frozen, we train text prompts to extract the joint features with improved representation, ensuring a diverse cluster structure that covers the entire dataset. We extensively compare our method with the state-of-the-art using seven benchmark datasets in different settings, achieving up to a performance gain of 20%. Interestingly, the prompts learned from one dataset demonstrate significant generalizability and can be applied directly to enhance the feature extraction of BLIP-2 from other datasets. To the best of our knowledge, UP-DP is the first work to incorporate unsupervised prompt learning in a vision-language model for data pre-selection.
Hyp-OW: Exploiting Hierarchical Structure Learning with Hyperbolic Distance Enhances Open World Object Detection
Jun 25, 2023Open World Object Detection (OWOD) is a challenging and realistic task that extends beyond the scope of standard Object Detection task. It involves detecting both known and unknown objects while integrating learned knowledge for future tasks. However, the level of 'unknownness' varies significantly depending on the context. For example, a tree is typically considered part of the background in a self-driving scene, but it may be significant in a household context. We argue that this external or contextual information should already be embedded within the known classes. In other words, there should be a semantic or latent structure relationship between the known and unknown items to be discovered. Motivated by this observation, we propose Hyp-OW, a method that learns and models hierarchical representation of known items through a SuperClass Regularizer. Leveraging this learned representation allows us to effectively detect unknown objects using a Similarity Distance-based Relabeling module. Extensive experiments on benchmark datasets demonstrate the effectiveness of Hyp-OW achieving improvement in both known and unknown detection (up to 6 points). These findings are particularly pronounced in our newly designed benchmark, where a strong hierarchical structure exists between known and unknown objects.