 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAG-V: A Multi-Agent Framework for Synthetic Data Generation and Verification
Nov 28, 2024


Extending the capabilities of Large Language Models (LLMs) with functions or tools for environment interaction has led to the emergence of the agent paradigm. In industry, training an LLM is not always feasible because of the scarcity of domain data, legal holds on proprietary customer data, rapidly changing business requirements, and the need to prototype new assistants. Agents provide an elegant solution to the above by relying on the zero-shot reasoning abilities of the underlying LLM and utilizing tools to explore and reason over customer data and respond to user requests. However, there are two concerns here: (I) acquiring large scale customer queries for agent testing is time-consuming, and (II) high reliance on the tool call sequence (or trajectory) followed by the agent to respond to user queries may lead to unexpected or incorrect behavior. To address this, we propose MAG-V, a multi-agent framework to first generate a dataset of questions that mimic customer queries; and second, reverse-engineer alternate questions from the responses for trajectory verification. Initial results indicate that our synthetic data can improve agent performance on actual customer queries. Furthermore, our trajectory verification methodology, inspired by distant supervision and using traditional machine learning (ML) models, outperforms a GPT-4o judge baseline by 11% accuracy and matches the performance of a GPT-4 judge on our constructed dataset. Overall, our approach is a step towards unifying diverse task agents into a cohesive framework for achieving an aligned objective.
Towards Reasoning-Aware Explainable VQA
Nov 09, 2022The domain of joint vision-language understanding, especially in the context of reasoning in Visual Question Answering (VQA) models, has garnered significant attention in the recent past. While most of the existing VQA models focus on improving the accuracy of VQA, the way models arrive at an answer is oftentimes a black box. As a step towards making the VQA task more explainable and interpretable, our method is built upon the SOTA VQA framework by augmenting it with an end-to-end explanation generation module. In this paper, we investigate two network architectures, including Long Short-Term Memory (LSTM) and Transformer decoder, as the explanation generator. Our method generates human-readable textual explanations while maintaining SOTA VQA accuracy on the GQA-REX (77.49%) and VQA-E (71.48%) datasets. Approximately 65.16% of the generated explanations are approved by humans as valid. Roughly 60.5% of the generated explanations are valid and lead to the correct answers.
Privacy Preserving Visual Question Answering
Feb 15, 2022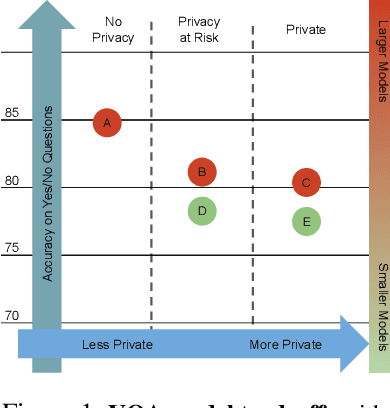

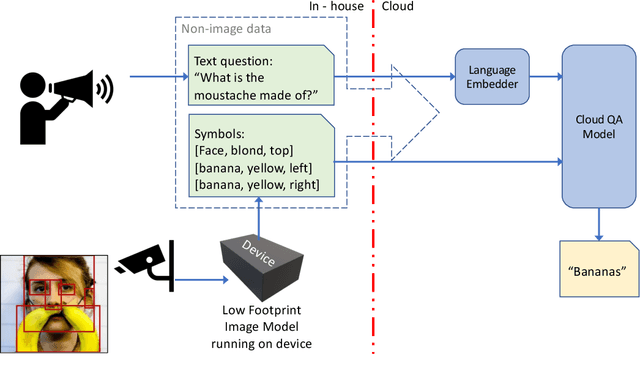

We introduce a novel privacy-preserving methodology for performing Visual Question Answering on the edge. Our method constructs a symbolic representation of the visual scene, using a low-complexity computer vision model that jointly predicts classes, attributes and predicates. This symbolic representation is non-differentiable, which means it cannot be used to recover the original image, thereby keeping the original image private. Our proposed hybrid solution uses a vision model which is more than 25 times smaller than the current state-of-the-art (SOTA) vision models, and 100 times smaller than end-to-end SOTA VQA models. We report detailed error analysis and discuss the trade-offs of using a distilled vision model and a symbolic representation of the visual scene.
Variational Inference for Category Recommendation in E-Commerce platforms
Apr 19, 2021
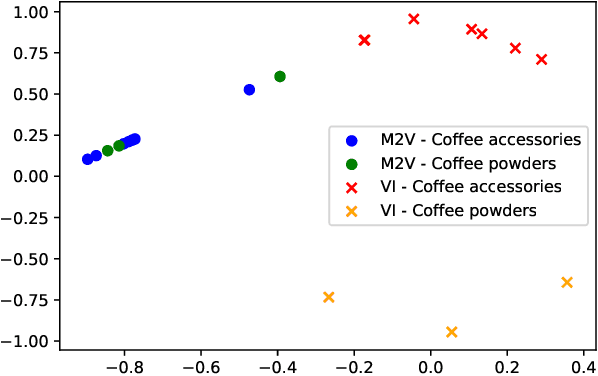
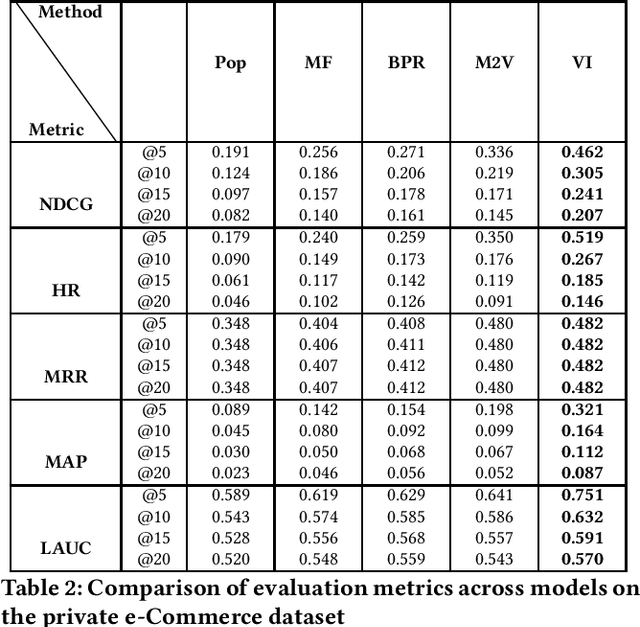

Category recommendation for users on an e-Commerce platform is an important task as it dictates the flow of traffic through the website. It is therefore important to surface precise and diverse category recommendations to aid the users' journey through the platform and to help them discover new groups of items. An often understated part in category recommendation is users' proclivity to repeat purchases. The structure of this temporal behavior can be harvested for better category recommendations and in this work, we attempt to harness this through variational inference. Further, to enhance the variational inference based optimization, we initialize the optimizer at better starting points through the well known Metapath2Vec algorithm. We demonstrate our results on two real-world datasets and show that our model outperforms standard baseline methods.
On Variational Inference for User Modeling in Attribute-Driven Collaborative Filtering
Dec 02, 2020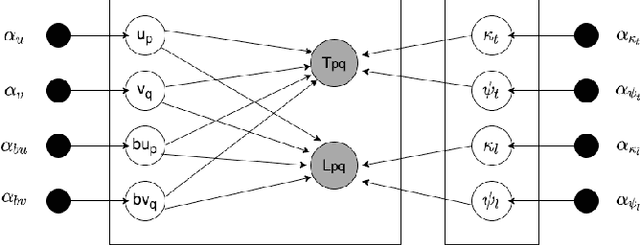
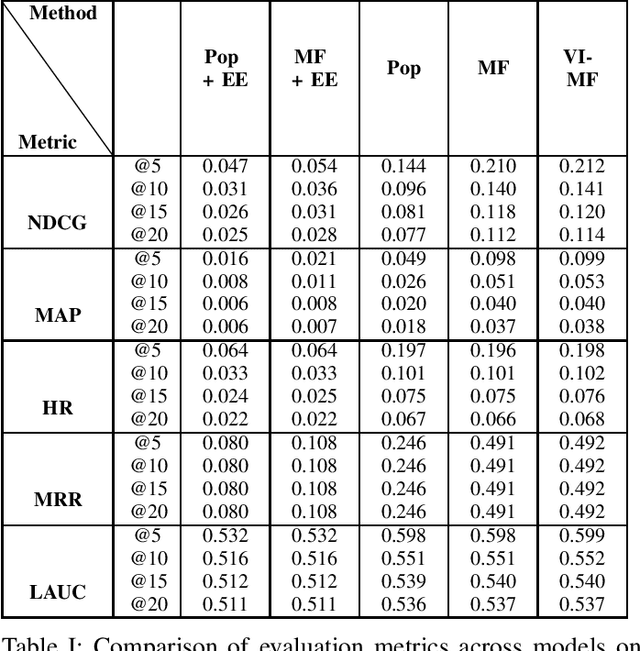
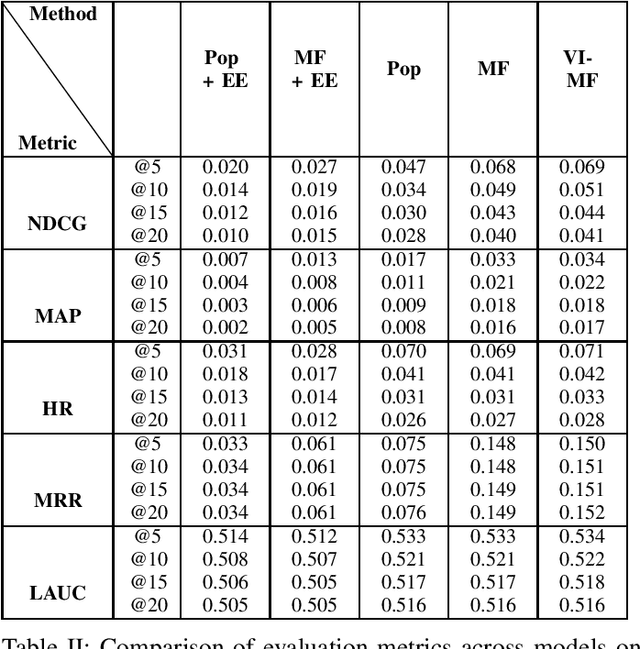
Recommender Systems have become an integral part of online e-Commerce platforms, driving customer engagement and revenue. Most popular recommender systems attempt to learn from users' past engagement data to understand behavioral traits of users and use that to predict future behavior. In this work, we present an approach to use causal inference to learn user-attribute affinities through temporal contexts. We formulate this objective as a Probabilistic Machine Learning problem and apply a variational inference based method to estimate the model parameters. We demonstrate the performance of the proposed method on the next attribute prediction task on two real world datasets and show that it outperforms standard baseline methods.
EDUQA: Educational Domain Question Answering System using Conceptual Network Mapping
Nov 12, 2019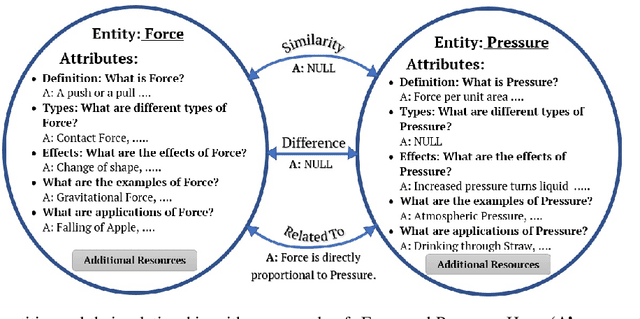

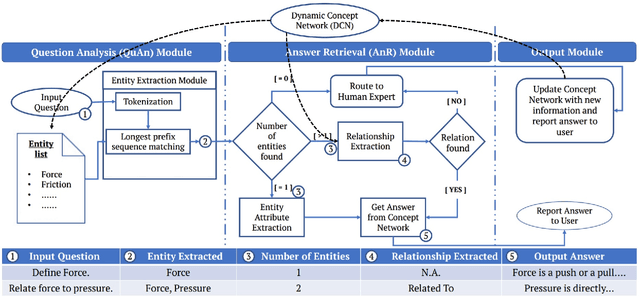

Most of the existing question answering models can be largely compiled into two categories: i) open domain question answering models that answer generic questions and use large-scale knowledge base along with the targeted web-corpus retrieval and ii) closed domain question answering models that address focused questioning area and use complex deep learning models. Both the above models derive answers through textual comprehension methods. Due to their inability to capture the pedagogical meaning of textual content, these models are not appropriately suited to the educational field for pedagogy. In this paper, we propose an on-the-fly conceptual network model that incorporates educational semantics. The proposed model preserves correlations between conceptual entities by applying intelligent indexing algorithms on the concept network so as to improve answer generation. This model can be utilized for building interactive conversational agents for aiding classroom learning.
* Published in the 44th International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2019