 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Exploiting Generalization in Offline Reinforcement Learning via Unseen State Augmentations
Aug 07, 2023



Offline reinforcement learning (RL) methods strike a balance between exploration and exploitation by conservative value estimation -- penalizing values of unseen states and actions. Model-free methods penalize values at all unseen actions, while model-based methods are able to further exploit unseen states via model rollouts. However, such methods are handicapped in their ability to find unseen states far away from the available offline data due to two factors -- (a) very short rollout horizons in models due to cascading model errors, and (b) model rollouts originating solely from states observed in offline data. We relax the second assumption and present a novel unseen state augmentation strategy to allow exploitation of unseen states where the learned model and value estimates generalize. Our strategy finds unseen states by value-informed perturbations of seen states followed by filtering out states with epistemic uncertainty estimates too high (high error) or too low (too similar to seen data). We observe improved performance in several offline RL tasks and find that our augmentation strategy consistently leads to overall lower average dataset Q-value estimates i.e. more conservative Q-value estimates than a baseline.
LEMMA: Learning Language-Conditioned Multi-Robot Manipulation
Aug 02, 2023
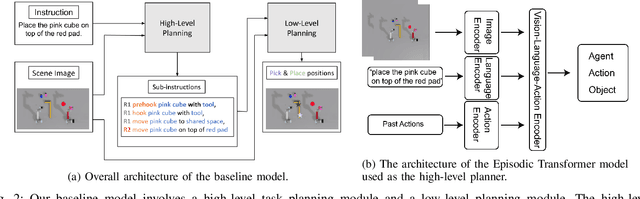


Complex manipulation tasks often require robots with complementary capabilities to collaborate. We introduce a benchmark for LanguagE-Conditioned Multi-robot MAnipulation (LEMMA) focused on task allocation and long-horizon object manipulation based on human language instructions in a tabletop setting. LEMMA features 8 types of procedurally generated tasks with varying degree of complexity, some of which require the robots to use tools and pass tools to each other. For each task, we provide 800 expert demonstrations and human instructions for training and evaluations. LEMMA poses greater challenges compared to existing benchmarks, as it requires the system to identify each manipulator's limitations and assign sub-tasks accordingly while also handling strong temporal dependencies in each task. To address these challenges, we propose a modular hierarchical planning approach as a baseline. Our results highlight the potential of LEMMA for developing future language-conditioned multi-robot systems.
Neural Architecture Search for Parameter-Efficient Fine-tuning of Large Pre-trained Language Models
May 26, 2023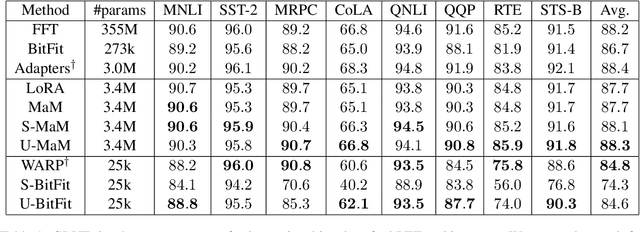
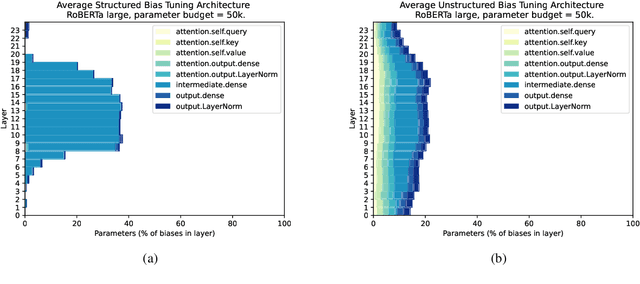
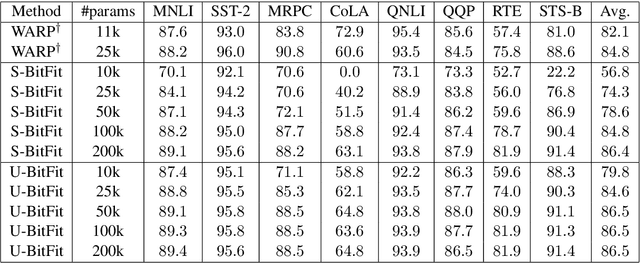
Parameter-efficient tuning (PET) methods fit pre-trained language models (PLMs) to downstream tasks by either computing a small compressed update for a subset of model parameters, or appending and fine-tuning a small number of new model parameters to the pre-trained network. Hand-designed PET architectures from the literature perform well in practice, but have the potential to be improved via automated neural architecture search (NAS). We propose an efficient NAS method for learning PET architectures via structured and unstructured pruning. We present experiments on GLUE demonstrating the effectiveness of our algorithm and discuss how PET architectural design choices affect performance in practice.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023



We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
Language-Informed Transfer Learning for Embodied Household Activities
Jan 12, 2023



For service robots to become general-purpose in everyday household environments, they need not only a large library of primitive skills, but also the ability to quickly learn novel tasks specified by users. Fine-tuning neural networks on a variety of downstream tasks has been successful in many vision and language domains, but research is still limited on transfer learning between diverse long-horizon tasks. We propose that, compared to reinforcement learning for a new household activity from scratch, home robots can benefit from transferring the value and policy networks trained for similar tasks. We evaluate this idea in the BEHAVIOR simulation benchmark which includes a large number of household activities and a set of action primitives. For easy mapping between state spaces of different tasks, we provide a text-based representation and leverage language models to produce a common embedding space. The results show that the selection of similar source activities can be informed by the semantic similarity of state and goal descriptions with the target task. We further analyze the results and discuss ways to overcome the problem of catastrophic forgetting.
GIVL: Improving Geographical Inclusivity of Vision-Language Models with Pre-Training Methods
Jan 05, 2023

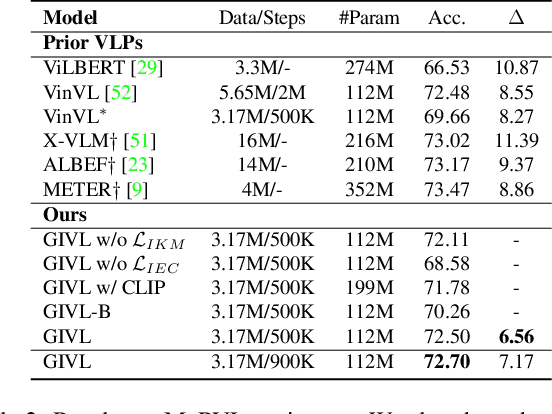

A key goal for the advancement of AI is to develop technologies that serve the needs not just of one group but of all communities regardless of their geographical region. In fact, a significant proportion of knowledge is locally shared by people from certain regions but may not apply equally in other regions because of cultural differences. If a model is unaware of regional characteristics, it may lead to performance disparity across regions and result in bias against underrepresented groups. We propose GIVL, a Geographically Inclusive Vision-and-Language Pre-trained model. There are two attributes of geo-diverse visual concepts which can help to learn geo-diverse knowledge: 1) concepts under similar categories have unique knowledge and visual characteristics, 2) concepts with similar visual features may fall in completely different categories. Motivated by the attributes, we design new pre-training objectives Image Knowledge Matching (IKM) and Image Edit Checking (IEC) to pre-train GIVL. Compared with similar-size models pre-trained with similar scale of data, GIVL achieves state-of-the-art (SOTA) and more balanced performance on geo-diverse V&L tasks.
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022



We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.