Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search for Parameter-Efficient Fine-tuning of Large Pre-trained Language Models
Paper and Code
May 26, 2023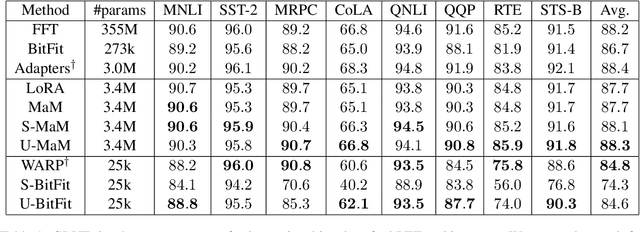
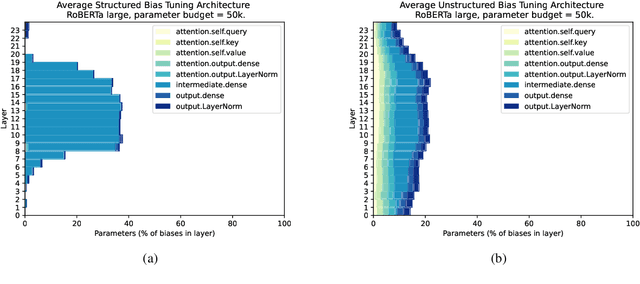
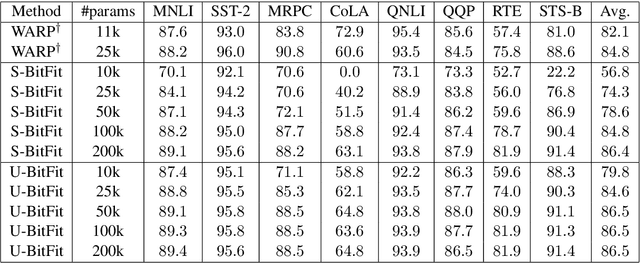
Parameter-efficient tuning (PET) methods fit pre-trained language models (PLMs) to downstream tasks by either computing a small compressed update for a subset of model parameters, or appending and fine-tuning a small number of new model parameters to the pre-trained network. Hand-designed PET architectures from the literature perform well in practice, but have the potential to be improved via automated neural architecture search (NAS). We propose an efficient NAS method for learning PET architectures via structured and unstructured pruning. We present experiments on GLUE demonstrating the effectiveness of our algorithm and discuss how PET architectural design choices affect performance in practice.
* 8 pages, 3 figures, ACL 2023
View paper on