 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Optimization Unlocks Real-Time Pairwise Reranking
Nov 10, 2025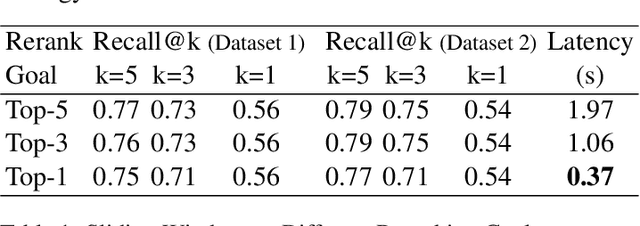



Efficiently reranking documents retrieved from information retrieval (IR) pipelines to enhance overall quality of Retrieval-Augmented Generation (RAG) system remains an important yet challenging problem. Recent studies have highlighted the importance of Large Language Models (LLMs) in reranking tasks. In particular, Pairwise Reranking Prompting (PRP) has emerged as a promising plug-and-play approach due to its usability and effectiveness. However, the inherent complexity of the algorithm, coupled with the high computational demands and latency incurred due to LLMs, raises concerns about its feasibility in real-time applications. To address these challenges, this paper presents a focused study on pairwise reranking, demonstrating that carefully applied optimization methods can significantly mitigate these issues. By implementing these methods, we achieve a remarkable latency reduction of up to 166 times, from 61.36 seconds to 0.37 seconds per query, with an insignificant drop in performance measured by Recall@k. Our study highlights the importance of design choices that were previously overlooked, such as using smaller models, limiting the reranked set, using lower precision, reducing positional bias with one-directional order inference, and restricting output tokens. These optimizations make LLM-based reranking substantially more efficient and feasible for latency-sensitive, real-world deployments.
Improving Consistency in Retrieval-Augmented Systems with Group Similarity Rewards
Oct 05, 2025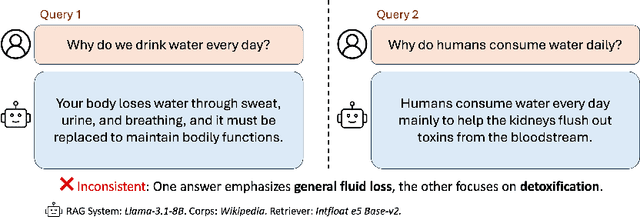
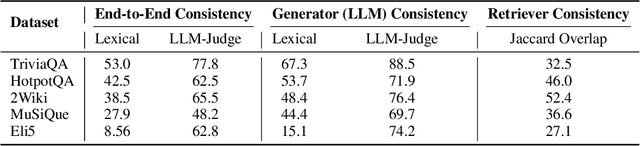
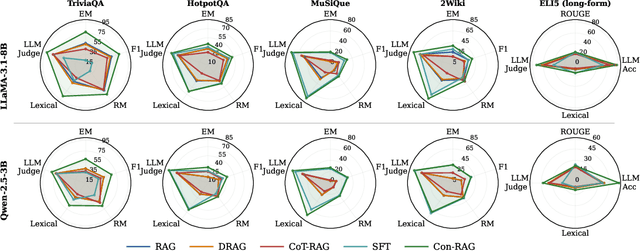
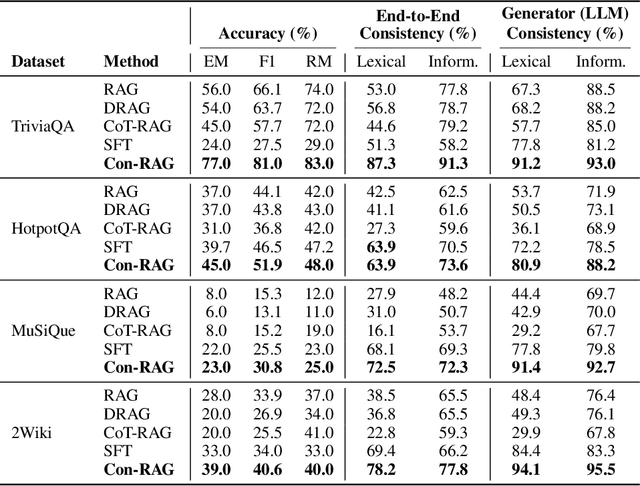
RAG systems are increasingly deployed in high-stakes domains where users expect outputs to be consistent across semantically equivalent queries. However, existing systems often exhibit significant inconsistencies due to variability in both the retriever and generator (LLM), undermining trust and reliability. In this work, we focus on information consistency, i.e., the requirement that outputs convey the same core content across semantically equivalent inputs. We introduce a principled evaluation framework that decomposes RAG consistency into retriever-level, generator-level, and end-to-end components, helping identify inconsistency sources. To improve consistency, we propose Paraphrased Set Group Relative Policy Optimization (PS-GRPO), an RL approach that leverages multiple rollouts across paraphrased set to assign group similarity rewards. We leverage PS-GRPO to achieve Information Consistent RAG (Con-RAG), training the generator to produce consistent outputs across paraphrased queries and remain robust to retrieval-induced variability. Because exact reward computation over paraphrase sets is computationally expensive, we also introduce a scalable approximation method that retains effectiveness while enabling efficient, large-scale training. Empirical evaluations across short-form, multi-hop, and long-form QA benchmarks demonstrate that Con-RAG significantly improves both consistency and accuracy over strong baselines, even in the absence of explicit ground-truth supervision. Our work provides practical solutions for evaluating and building reliable RAG systems for safety-critical deployments.
A Comparison of Independent and Joint Fine-tuning Strategies for Retrieval-Augmented Generation
Oct 02, 2025
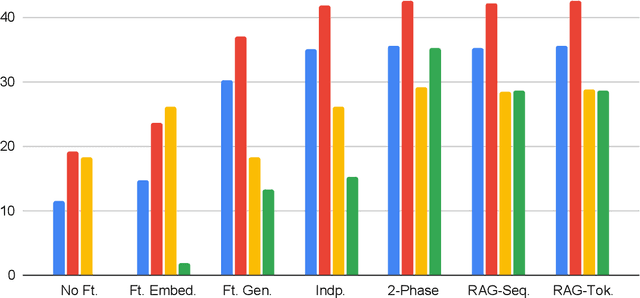


A Comparison of Independent and Joint Fine-tuning Strategies for Retrieval-Augmented Generation Download PDF Neal Gregory Lawton, Alfy Samuel, Anoop Kumar, Daben Liu Published: 20 Aug 2025, Last Modified: 17 Sept 2025EMNLP 2025 FindingsConference, Publication Chairs, AuthorsRevisionsBibTeXCC BY 4.0 Keywords: Retrieval-Augmented Generation (RAG), Large Language Models (LLMs), Fine-tuning, Question Answering, Joint fine-tuning TL;DR: We evaluate and compare strategies for fine-tuning Retrieval Augmented Generation (RAG) pipelines, including independent fine-tuning, joint fine-tuning, and two-phase fine-tuning. Abstract: Retrieval augmented generation (RAG) is a popular framework for question answering that is powered by two large language models (LLMs): an embedding model that retrieves context documents from a database that are relevant to a given question, and a generator model that uses the retrieved context to generate an answer to the question. Both the embedding and generator models can be fine-tuned to increase performance of a RAG pipeline on a new task, but multiple fine-tuning strategies exist with different costs and benefits. In this paper, we evaluate and compare several RAG fine-tuning strategies, including independent, joint, and two-phase fine-tuning. In our experiments, we observe that all of these strategies achieve about equal improvement in EM and F1 generation quality metrics, although they have significantly different computational costs. We conclude the optimal fine-tuning strategy to use depends on whether the training dataset includes context labels and whether a grid search over the learning rates for the embedding and generator models is required.
FB-RAG: Improving RAG with Forward and Backward Lookup
May 22, 2025The performance of Retrieval Augmented Generation (RAG) systems relies heavily on the retriever quality and the size of the retrieved context. A large enough context ensures that the relevant information is present in the input context for the LLM, but also incorporates irrelevant content that has been shown to confuse the models. On the other hand, a smaller context reduces the irrelevant information, but it often comes at the risk of losing important information necessary to answer the input question. This duality is especially challenging to manage for complex queries that contain little information to retrieve the relevant chunks from the full context. To address this, we present a novel framework, called FB-RAG, which enhances the RAG pipeline by relying on a combination of backward lookup (overlap with the query) and forward lookup (overlap with candidate reasons and answers) to retrieve specific context chunks that are the most relevant for answering the input query. Our evaluations on 9 datasets from two leading benchmarks show that FB-RAG consistently outperforms RAG and Long Context baselines developed recently for these benchmarks. We further show that FB-RAG can improve performance while reducing latency. We perform qualitative analysis of the strengths and shortcomings of our approach, providing specific insights to guide future work.
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
Dec 09, 2024



A key component of building safe and reliable language models is enabling the models to appropriately refuse to follow certain instructions or answer certain questions. We may want models to output refusal messages for various categories of user queries, for example, ill-posed questions, instructions for committing illegal acts, or queries which require information past the model's knowledge horizon. Engineering models that refuse to answer such questions is complicated by the fact that an individual may want their model to exhibit varying levels of sensitivity for refusing queries of various categories, and different users may want different refusal rates. The current default approach involves training multiple models with varying proportions of refusal messages from each category to achieve the desired refusal rates, which is computationally expensive and may require training a new model to accommodate each user's desired preference over refusal rates. To address these challenges, we propose refusal tokens, one such token for each refusal category or a single refusal token, which are prepended to the model's responses during training. We then show how to increase or decrease the probability of generating the refusal token for each category during inference to steer the model's refusal behavior. Refusal tokens enable controlling a single model's refusal rates without the need of any further fine-tuning, but only by selectively intervening during generation.
Leveraging LLMs for Dialogue Quality Measurement
Jun 25, 2024In task-oriented conversational AI evaluation, unsupervised methods poorly correlate with human judgments, and supervised approaches lack generalization. Recent advances in large language models (LLMs) show robust zeroshot and few-shot capabilities across NLP tasks. This paper explores using LLMs for automated dialogue quality evaluation, experimenting with various configurations on public and proprietary datasets. Manipulating factors such as model size, in-context examples, and selection techniques, we examine "chain-of-thought" (CoT) reasoning and label extraction procedures. Our results show that (1) larger models yield more accurate dialogue labels; (2) algorithmic selection of in-context examples outperforms random selection; (3) CoT reasoning where an LLM is asked to provide justifications before outputting final labels improves performance; and (4) fine-tuned LLMs outperform out-of-the-box ones. Our results indicate that LLMs that are suitably fine-tuned and have sufficient reasoning capabilities can be leveraged for automated dialogue evaluation.
Optimizing Photometric Light Curve Analysis: Evaluating Scipy's Minimize Function for Eclipse Mapping of Cataclysmic Variables
May 30, 2024



With a particular focus on Scipy's minimize function the eclipse mapping method is thoroughly researched and implemented utilizing Python and essential libraries. Many optimization techniques are used, including Sequential Least Squares Programming (SLSQP), Nelder-Mead, and Conjugate Gradient (CG). However, for the purpose of examining photometric light curves these methods seek to solve the maximum entropy equation under a chi-squared constraint. Therefore, these techniques are first evaluated on two-dimensional Gaussian data without a chi-squared restriction, and then they are used to map the accretion disc and uncover the Gaussian structure of the Cataclysmic Variable KIC 201325107. Critical analysis is performed on the code structure to find possible faults and design problems. Additionally, the analysis shows how several factors impacting computing time and image quality are included including the variance in Gaussian weighting, disc image resolution, number of data points in the light curve, and degree of constraint.
Unveiling the Impact of Macroeconomic Policies: A Double Machine Learning Approach to Analyzing Interest Rate Effects on Financial Markets
Mar 31, 2024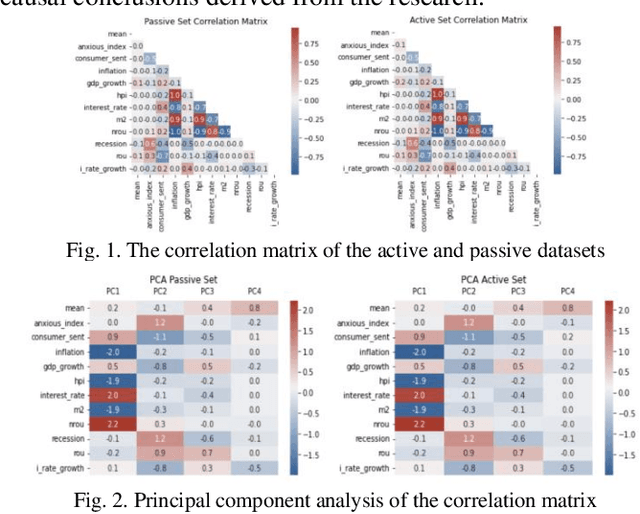
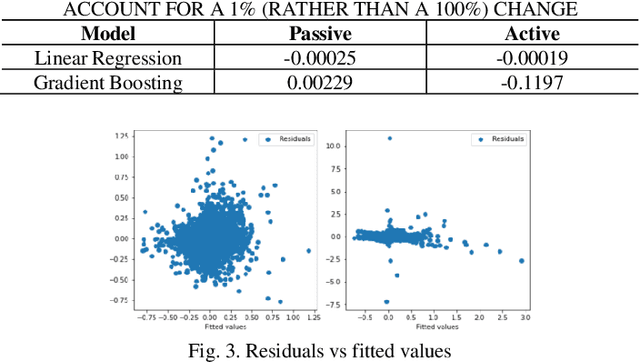
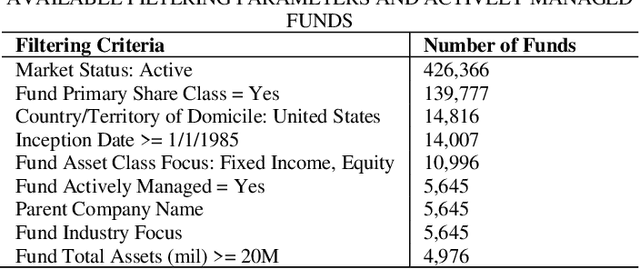
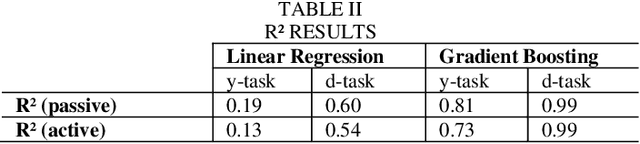
This study examines the effects of macroeconomic policies on financial markets using a novel approach that combines Machine Learning (ML) techniques and causal inference. It focuses on the effect of interest rate changes made by the US Federal Reserve System (FRS) on the returns of fixed income and equity funds between January 1986 and December 2021. The analysis makes a distinction between actively and passively managed funds, hypothesizing that the latter are less susceptible to changes in interest rates. The study contrasts gradient boosting and linear regression models using the Double Machine Learning (DML) framework, which supports a variety of statistical learning techniques. Results indicate that gradient boosting is a useful tool for predicting fund returns; for example, a 1% increase in interest rates causes an actively managed fund's return to decrease by -11.97%. This understanding of the relationship between interest rates and fund performance provides opportunities for additional research and insightful, data-driven advice for fund managers and investors
The Emotional Impact of Game Duration: A Framework for Understanding Player Emotions in Extended Gameplay Sessions
Mar 31, 2024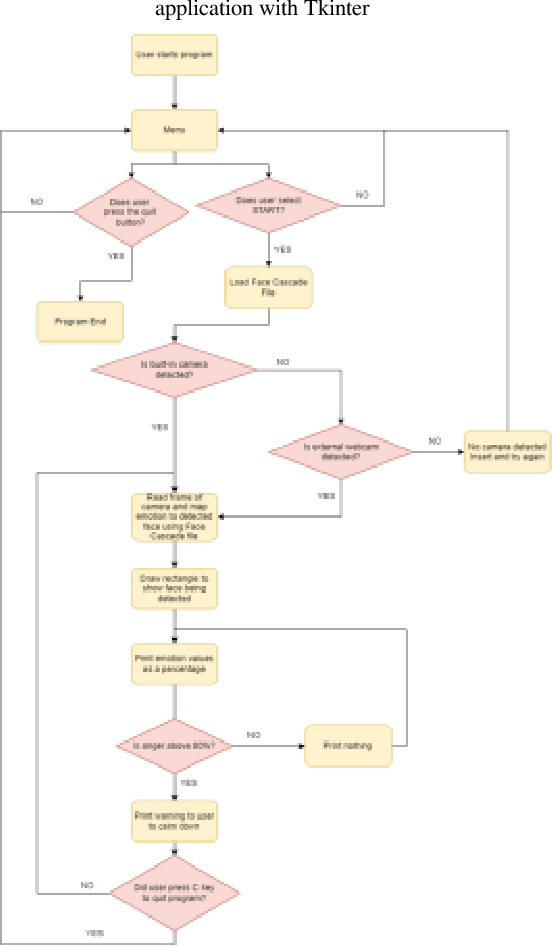
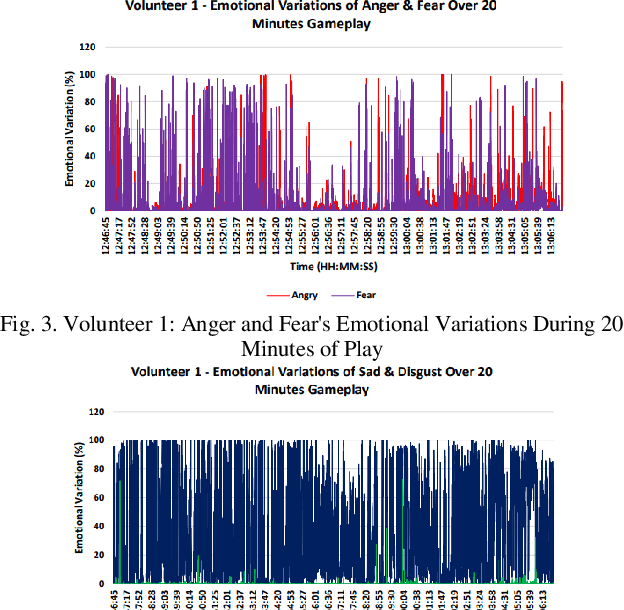
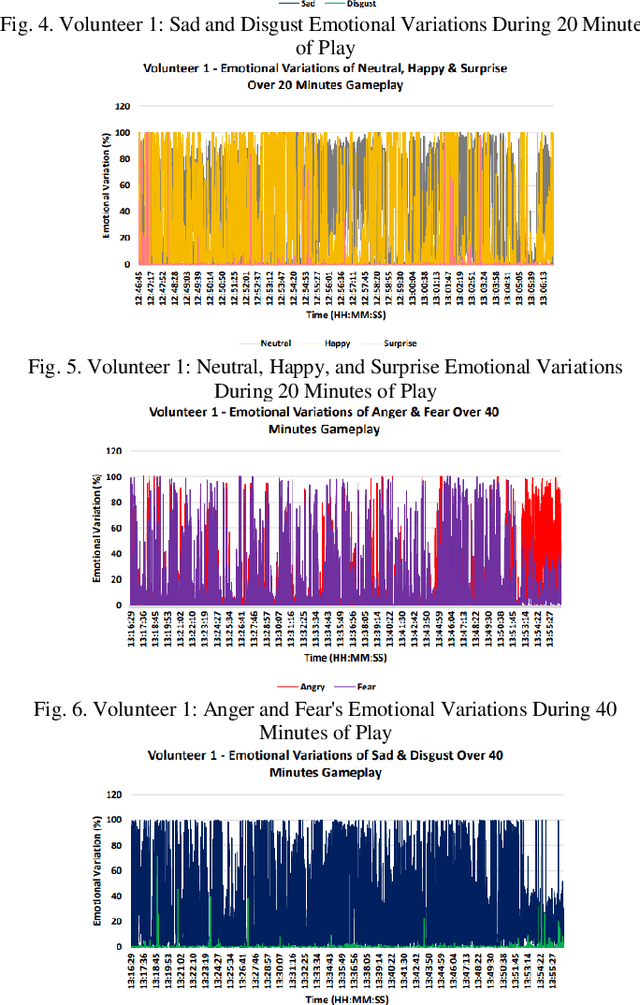
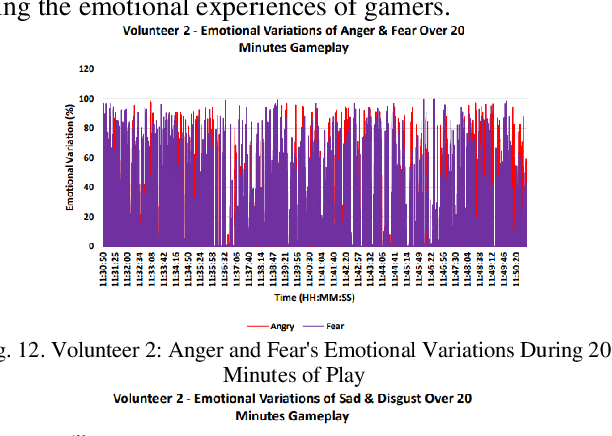
Video games have played a crucial role in entertainment since their development in the 1970s, becoming even more prominent during the lockdown period when people were looking for ways to entertain them. However, at that time, players were unaware of the significant impact that playtime could have on their feelings. This has made it challenging for designers and developers to create new games since they have to control the emotional impact that these games will take on players. Thus, the purpose of this study is to look at how a player's emotions are affected by the duration of the game. In order to achieve this goal, a framework for emotion detection is created. According to the experiment's results, the volunteers' general ability to express emotions increased from 20 to 60 minutes. In comparison to shorter gameplay sessions, the experiment found that extended gameplay sessions did significantly affect the player's emotions. According to the results, it was recommended that in order to lessen the potential emotional impact that playing computer and video games may have in the future, game producers should think about creating shorter, entertaining games.
Prompt Perturbation Consistency Learning for Robust Language Models
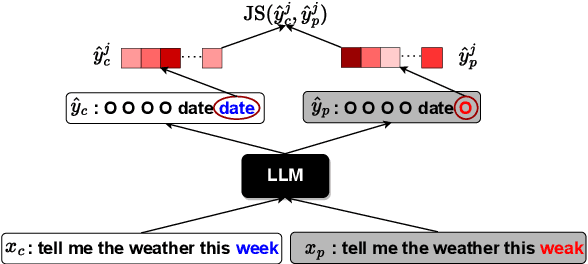
Feb 24, 2024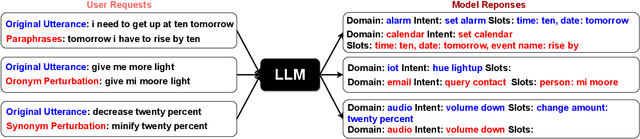


Large language models (LLMs) have demonstrated impressive performance on a number of natural language processing tasks, such as question answering and text summarization. However, their performance on sequence labeling tasks such as intent classification and slot filling (IC-SF), which is a central component in personal assistant systems, lags significantly behind discriminative models. Furthermore, there is a lack of substantive research on the robustness of LLMs to various perturbations in the input prompts. The contributions of this paper are three-fold. First, we show that fine-tuning sufficiently large LLMs can produce IC-SF performance comparable to discriminative models. Next, we systematically analyze the performance deterioration of those fine-tuned models due to three distinct yet relevant types of input perturbations - oronyms, synonyms, and paraphrasing. Finally, we propose an efficient mitigation approach, Prompt Perturbation Consistency Learning (PPCL), which works by regularizing the divergence between losses from clean and perturbed samples. Our experiments demonstrate that PPCL can recover on average 59% and 69% of the performance drop for IC and SF tasks, respectively. Furthermore, PPCL beats the data augmentation approach while using ten times fewer augmented data samples.