 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Consistency in Retrieval-Augmented Systems with Group Similarity Rewards
Oct 05, 2025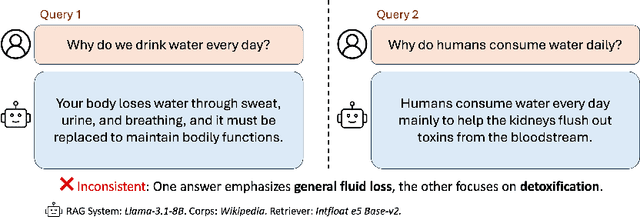
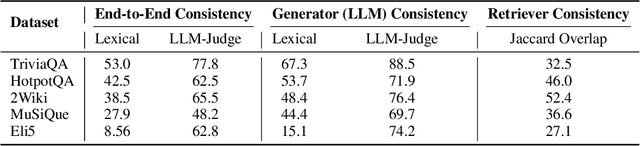
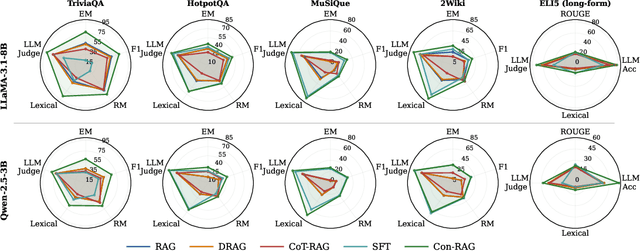
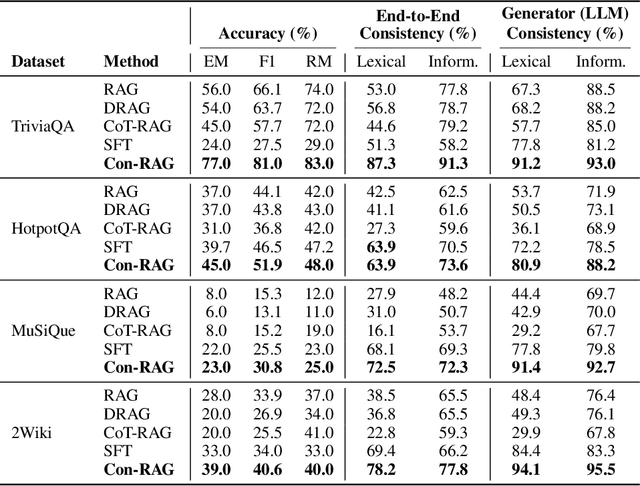
RAG systems are increasingly deployed in high-stakes domains where users expect outputs to be consistent across semantically equivalent queries. However, existing systems often exhibit significant inconsistencies due to variability in both the retriever and generator (LLM), undermining trust and reliability. In this work, we focus on information consistency, i.e., the requirement that outputs convey the same core content across semantically equivalent inputs. We introduce a principled evaluation framework that decomposes RAG consistency into retriever-level, generator-level, and end-to-end components, helping identify inconsistency sources. To improve consistency, we propose Paraphrased Set Group Relative Policy Optimization (PS-GRPO), an RL approach that leverages multiple rollouts across paraphrased set to assign group similarity rewards. We leverage PS-GRPO to achieve Information Consistent RAG (Con-RAG), training the generator to produce consistent outputs across paraphrased queries and remain robust to retrieval-induced variability. Because exact reward computation over paraphrase sets is computationally expensive, we also introduce a scalable approximation method that retains effectiveness while enabling efficient, large-scale training. Empirical evaluations across short-form, multi-hop, and long-form QA benchmarks demonstrate that Con-RAG significantly improves both consistency and accuracy over strong baselines, even in the absence of explicit ground-truth supervision. Our work provides practical solutions for evaluating and building reliable RAG systems for safety-critical deployments.
Stroke-based Cyclic Amplifier: Image Super-Resolution at Arbitrary Ultra-Large Scales
Jun 12, 2025



Prior Arbitrary-Scale Image Super-Resolution (ASISR) methods often experience a significant performance decline when the upsampling factor exceeds the range covered by the training data, introducing substantial blurring. To address this issue, we propose a unified model, Stroke-based Cyclic Amplifier (SbCA), for ultra-large upsampling tasks. The key of SbCA is the stroke vector amplifier, which decomposes the image into a series of strokes represented as vector graphics for magnification. Then, the detail completion module also restores missing details, ensuring high-fidelity image reconstruction. Our cyclic strategy achieves ultra-large upsampling by iteratively refining details with this unified SbCA model, trained only once for all, while keeping sub-scales within the training range. Our approach effectively addresses the distribution drift issue and eliminates artifacts, noise and blurring, producing high-quality, high-resolution super-resolved images. Experimental validations on both synthetic and real-world datasets demonstrate that our approach significantly outperforms existing methods in ultra-large upsampling tasks (e.g. $\times100$), delivering visual quality far superior to state-of-the-art techniques.
Leveraging LLMs for Dialogue Quality Measurement
Jun 25, 2024



In task-oriented conversational AI evaluation, unsupervised methods poorly correlate with human judgments, and supervised approaches lack generalization. Recent advances in large language models (LLMs) show robust zeroshot and few-shot capabilities across NLP tasks. This paper explores using LLMs for automated dialogue quality evaluation, experimenting with various configurations on public and proprietary datasets. Manipulating factors such as model size, in-context examples, and selection techniques, we examine "chain-of-thought" (CoT) reasoning and label extraction procedures. Our results show that (1) larger models yield more accurate dialogue labels; (2) algorithmic selection of in-context examples outperforms random selection; (3) CoT reasoning where an LLM is asked to provide justifications before outputting final labels improves performance; and (4) fine-tuned LLMs outperform out-of-the-box ones. Our results indicate that LLMs that are suitably fine-tuned and have sufficient reasoning capabilities can be leveraged for automated dialogue evaluation.
Self-supervised Photographic Image Layout Representation Learning
Mar 06, 2024In the domain of image layout representation learning, the critical process of translating image layouts into succinct vector forms is increasingly significant across diverse applications, such as image retrieval, manipulation, and generation. Most approaches in this area heavily rely on costly labeled datasets and notably lack in adapting their modeling and learning methods to the specific nuances of photographic image layouts. This shortfall makes the learning process for photographic image layouts suboptimal. In our research, we directly address these challenges. We innovate by defining basic layout primitives that encapsulate various levels of layout information and by mapping these, along with their interconnections, onto a heterogeneous graph structure. This graph is meticulously engineered to capture the intricate layout information within the pixel domain explicitly. Advancing further, we introduce novel pretext tasks coupled with customized loss functions, strategically designed for effective self-supervised learning of these layout graphs. Building on this foundation, we develop an autoencoder-based network architecture skilled in compressing these heterogeneous layout graphs into precise, dimensionally-reduced layout representations. Additionally, we introduce the LODB dataset, which features a broader range of layout categories and richer semantics, serving as a comprehensive benchmark for evaluating the effectiveness of layout representation learning methods. Our extensive experimentation on this dataset demonstrates the superior performance of our approach in the realm of photographic image layout representation learning.
An End-to-End Neural Network for Image Cropping by Learning Composition from Aesthetic Photos
Aug 07, 2019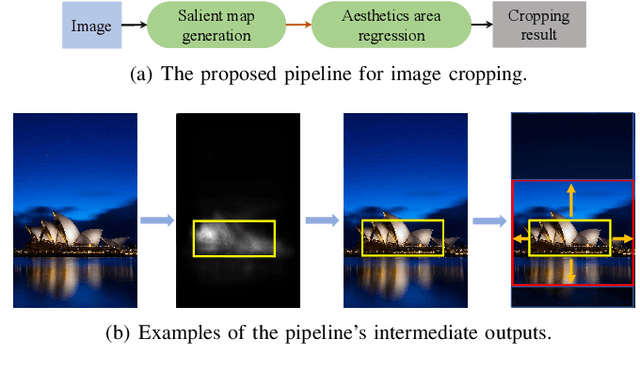
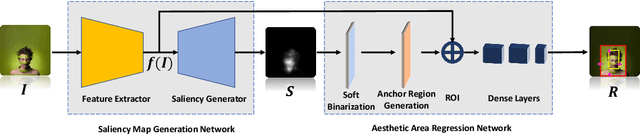
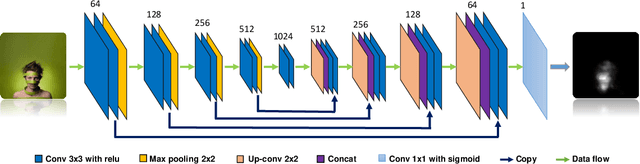

As one of the fundamental techniques for image editing, image cropping discards unrelevant contents and remains the pleasing portions of the image to enhance the overall composition and achieve better visual/aesthetic perception. In this paper, we primarily focus on improving the accuracy of automatic image cropping, and on further exploring its potential in public datasets with high efficiency. From this respect, we propose a deep learning based framework to learn the objects composition from photos with high aesthetic qualities, where an anchor region is detected through a convolutional neural network (CNN) with the Gaussian kernel to maintain the interested objects' integrity. This initial detected anchor area is then fed into a light weighted regression network to obtain the final cropping result. Unlike the conventional methods that multiple candidates are proposed and evaluated iteratively, only a single anchor region is produced in our model, which is mapped to the final output directly. Thus, low computational resources are required for the proposed approach. The experimental results on the public datasets show that both cropping accuracy and efficiency achieve the state-ofthe-art performances.
Finding More Relevance: Propagating Similarity on Markov Random Field for Image Retrieval
Dec 26, 2013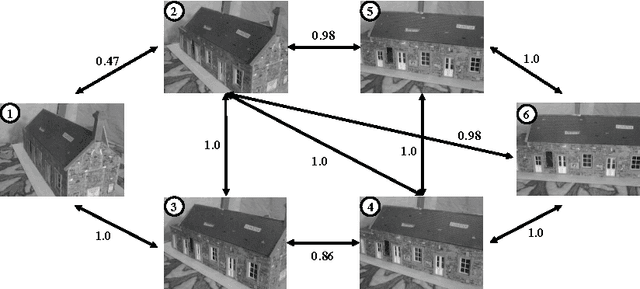
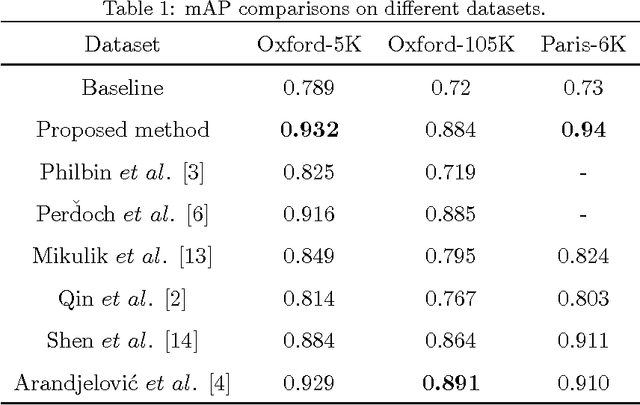
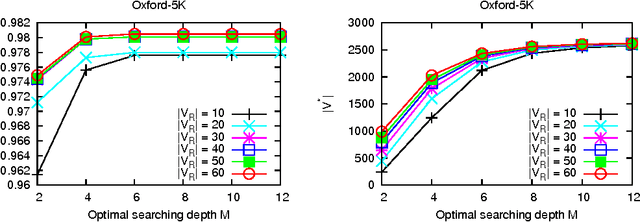
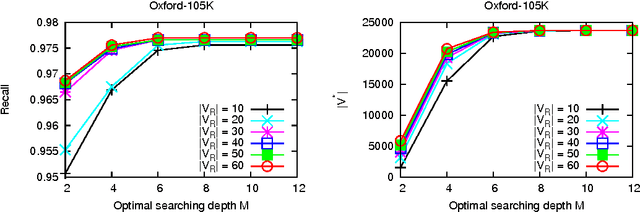
To effectively retrieve objects from large corpus with high accuracy is a challenge task. In this paper, we propose a method that propagates visual feature level similarities on a Markov random field (MRF) to obtain a high level correspondence in image space for image pairs. The proposed correspondence between image pair reflects not only the similarity of low-level visual features but also the relations built through other images in the database and it can be easily integrated into the existing bag-of-visual-words(BoW) based systems to reduce the missing rate. We evaluate our method on the standard Oxford-5K, Oxford-105K and Paris-6K dataset. The experiment results show that the proposed method significantly improves the retrieval accuracy on three datasets and exceeds the current state-of-the-art retrieval performance.