 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Dialogue Quality Measurement
Jun 25, 2024



In task-oriented conversational AI evaluation, unsupervised methods poorly correlate with human judgments, and supervised approaches lack generalization. Recent advances in large language models (LLMs) show robust zeroshot and few-shot capabilities across NLP tasks. This paper explores using LLMs for automated dialogue quality evaluation, experimenting with various configurations on public and proprietary datasets. Manipulating factors such as model size, in-context examples, and selection techniques, we examine "chain-of-thought" (CoT) reasoning and label extraction procedures. Our results show that (1) larger models yield more accurate dialogue labels; (2) algorithmic selection of in-context examples outperforms random selection; (3) CoT reasoning where an LLM is asked to provide justifications before outputting final labels improves performance; and (4) fine-tuned LLMs outperform out-of-the-box ones. Our results indicate that LLMs that are suitably fine-tuned and have sufficient reasoning capabilities can be leveraged for automated dialogue evaluation.
Two Approaches to Building Collaborative, Task-Oriented Dialog Agents through Self-Play
Sep 20, 2021
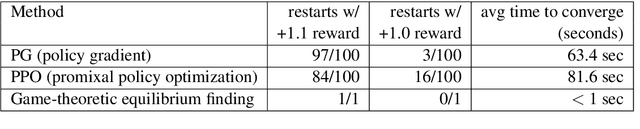
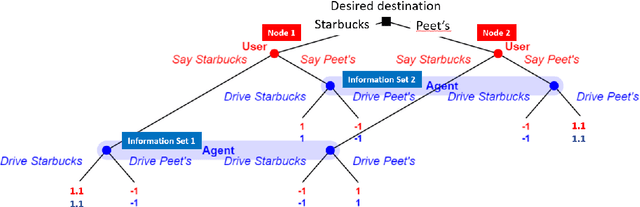
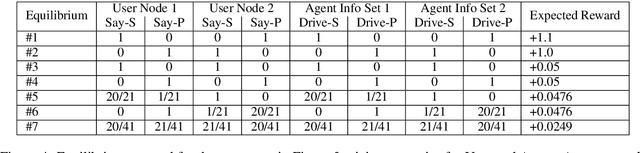
Task-oriented dialog systems are often trained on human/human dialogs, such as collected from Wizard-of-Oz interfaces. However, human/human corpora are frequently too small for supervised training to be effective. This paper investigates two approaches to training agent-bots and user-bots through self-play, in which they autonomously explore an API environment, discovering communication strategies that enable them to solve the task. We give empirical results for both reinforcement learning and game-theoretic equilibrium finding.
MeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021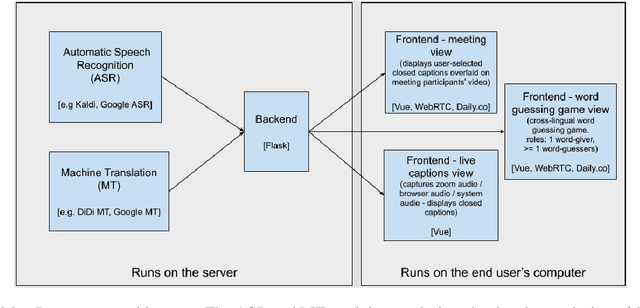

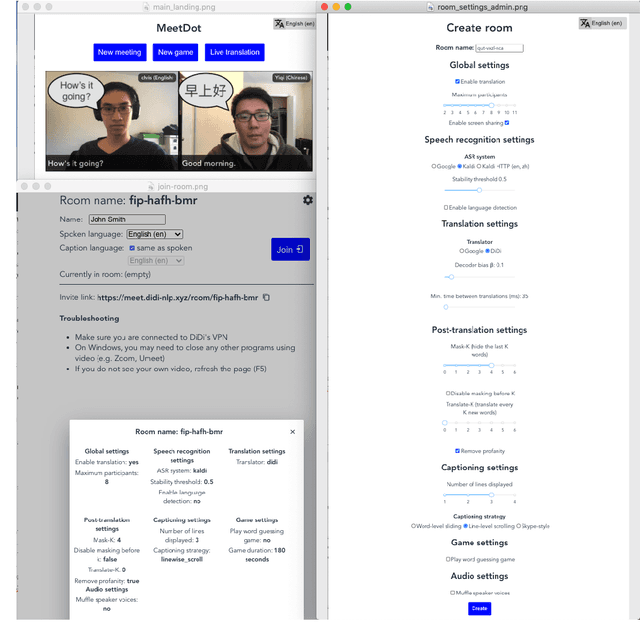
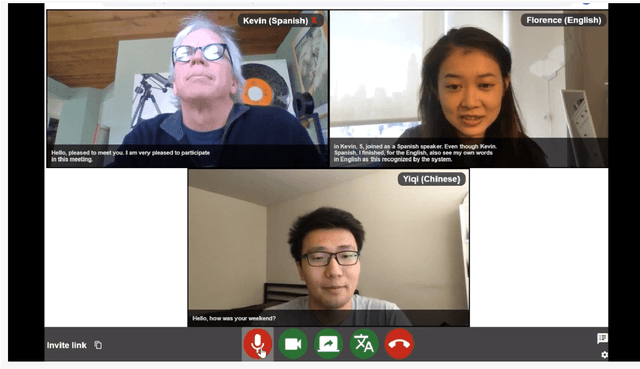
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
MEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
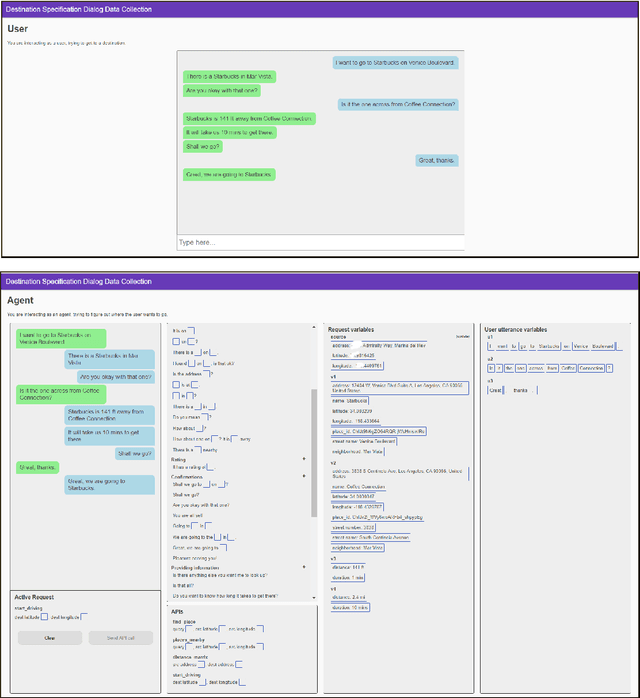


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.
Parallel Corpus Filtering via Pre-trained Language Models
May 13, 2020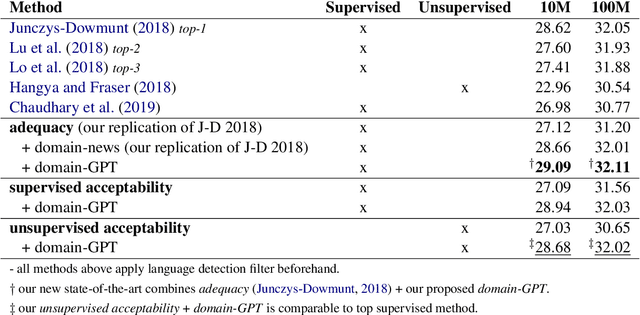
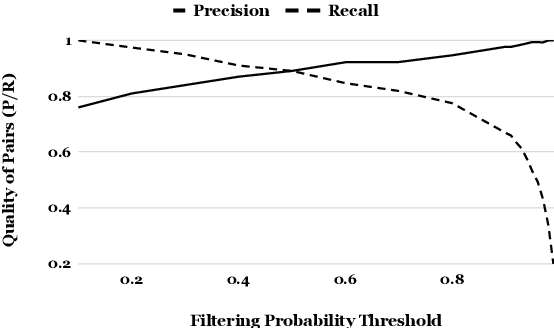
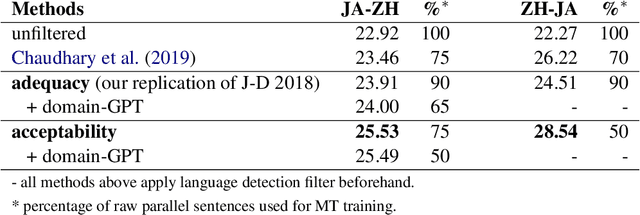
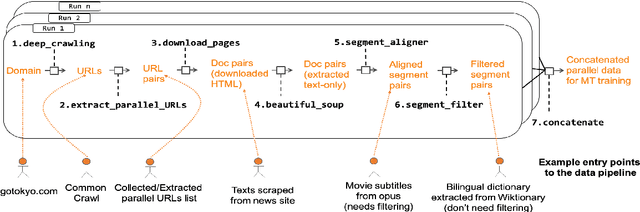
Web-crawled data provides a good source of parallel corpora for training machine translation models. It is automatically obtained, but extremely noisy, and recent work shows that neural machine translation systems are more sensitive to noise than traditional statistical machine translation methods. In this paper, we propose a novel approach to filter out noisy sentence pairs from web-crawled corpora via pre-trained language models. We measure sentence parallelism by leveraging the multilingual capability of BERT and use the Generative Pre-training (GPT) language model as a domain filter to balance data domains. We evaluate the proposed method on the WMT 2018 Parallel Corpus Filtering shared task, and on our own web-crawled Japanese-Chinese parallel corpus. Our method significantly outperforms baselines and achieves a new state-of-the-art. In an unsupervised setting, our method achieves comparable performance to the top-1 supervised method. We also evaluate on a web-crawled Japanese-Chinese parallel corpus that we make publicly available.
Lightly-supervised Representation Learning with Global Interpretability
May 29, 2018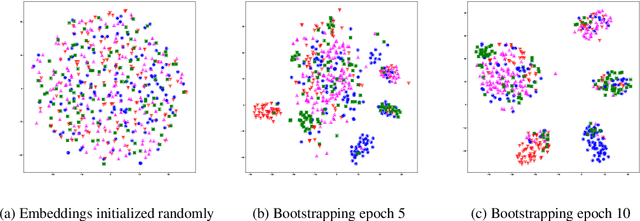
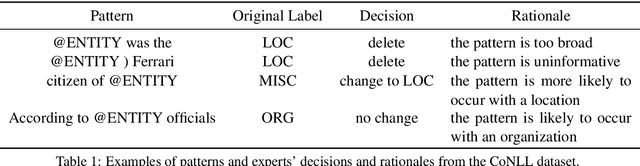
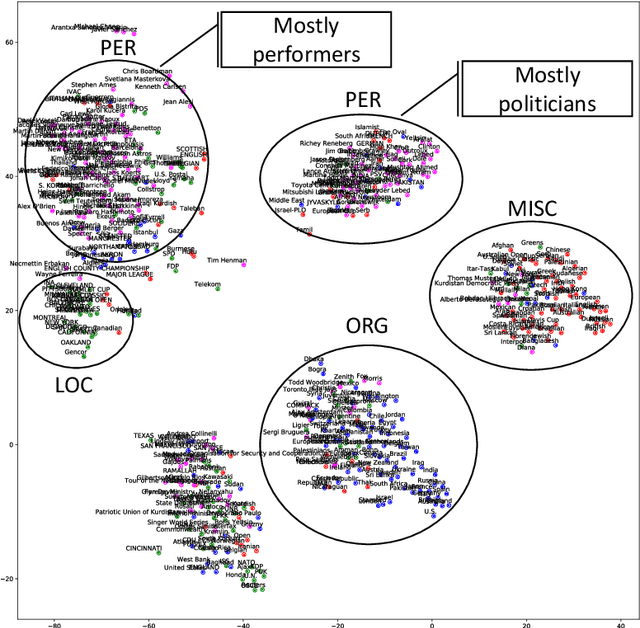
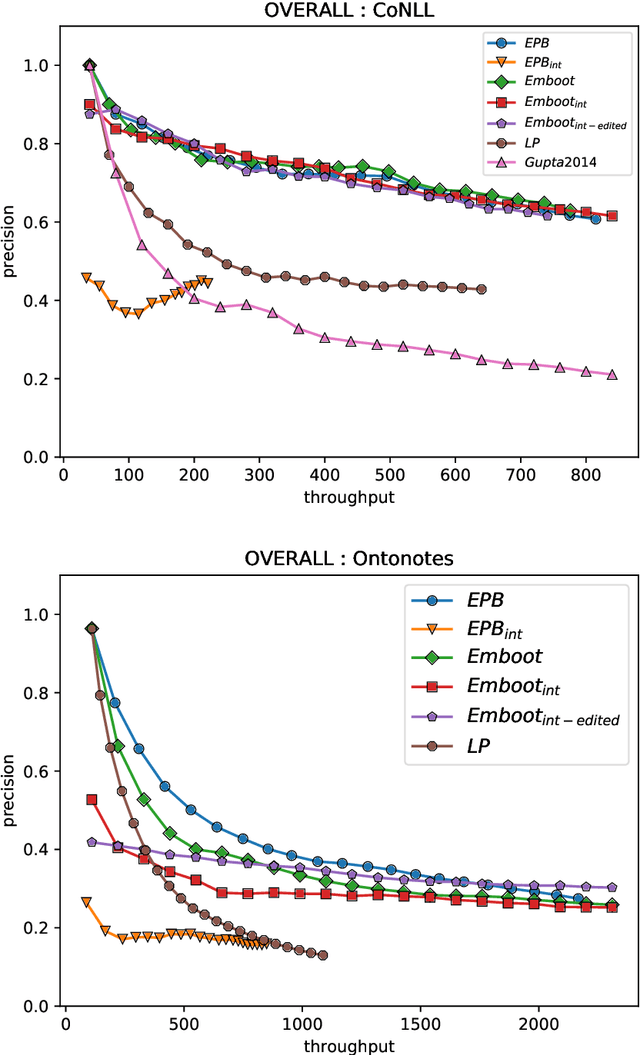
We propose a lightly-supervised approach for information extraction, in particular named entity classification, which combines the benefits of traditional bootstrapping, i.e., use of limited annotations and interpretability of extraction patterns, with the robust learning approaches proposed in representation learning. Our algorithm iteratively learns custom embeddings for both the multi-word entities to be extracted and the patterns that match them from a few example entities per category. We demonstrate that this representation-based approach outperforms three other state-of-the-art bootstrapping approaches on two datasets: CoNLL-2003 and OntoNotes. Additionally, using these embeddings, our approach outputs a globally-interpretable model consisting of a decision list, by ranking patterns based on their proximity to the average entity embedding in a given class. We show that this interpretable model performs close to our complete bootstrapping model, proving that representation learning can be used to produce interpretable models with small loss in performance.
Learning Discriminative Relational Features for Sequence Labeling
May 07, 2017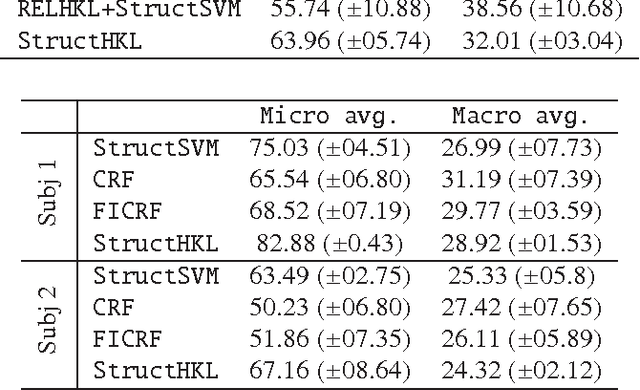
Discovering relational structure between input features in sequence labeling models has shown to improve their accuracy in several problem settings. However, the search space of relational features is exponential in the number of basic input features. Consequently, approaches that learn relational features, tend to follow a greedy search strategy. In this paper, we study the possibility of optimally learning and applying discriminative relational features for sequence labeling. For learning features derived from inputs at a particular sequence position, we propose a Hierarchical Kernels-based approach (referred to as Hierarchical Kernel Learning for Structured Output Spaces - StructHKL). This approach optimally and efficiently explores the hierarchical structure of the feature space for problems with structured output spaces such as sequence labeling. Since the StructHKL approach has limitations in learning complex relational features derived from inputs at relative positions, we propose two solutions to learn relational features namely, (i) enumerating simple component features of complex relational features and discovering their compositions using StructHKL and (ii) leveraging relational kernels, that compute the similarity between instances implicitly, in the sequence labeling problem. We perform extensive empirical evaluation on publicly available datasets and record our observations on settings in which certain approaches are effective.