 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightly-supervised Representation Learning with Global Interpretability
May 29, 2018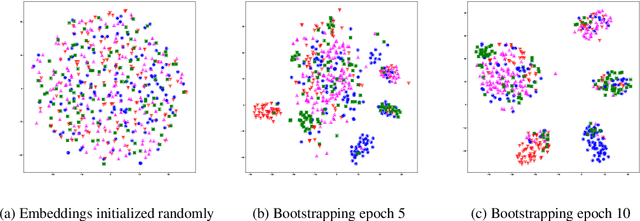
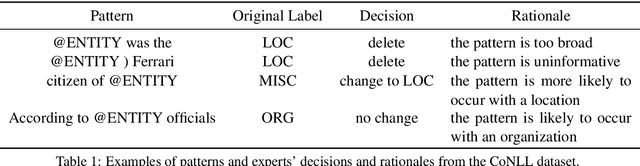
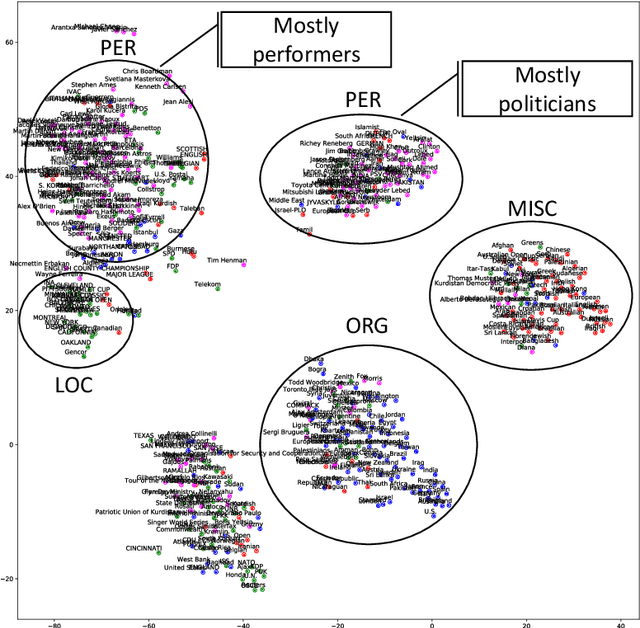
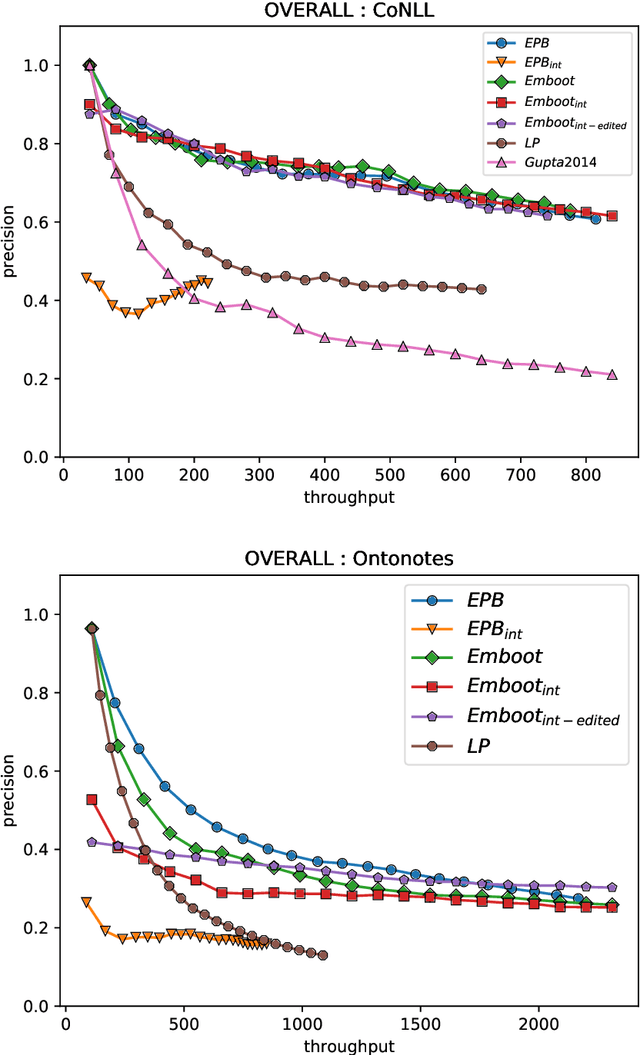
We propose a lightly-supervised approach for information extraction, in particular named entity classification, which combines the benefits of traditional bootstrapping, i.e., use of limited annotations and interpretability of extraction patterns, with the robust learning approaches proposed in representation learning. Our algorithm iteratively learns custom embeddings for both the multi-word entities to be extracted and the patterns that match them from a few example entities per category. We demonstrate that this representation-based approach outperforms three other state-of-the-art bootstrapping approaches on two datasets: CoNLL-2003 and OntoNotes. Additionally, using these embeddings, our approach outputs a globally-interpretable model consisting of a decision list, by ranking patterns based on their proximity to the average entity embedding in a given class. We show that this interpretable model performs close to our complete bootstrapping model, proving that representation learning can be used to produce interpretable models with small loss in performance.
Text Annotation Graphs: Annotating Complex Natural Language Phenomena
Mar 01, 2018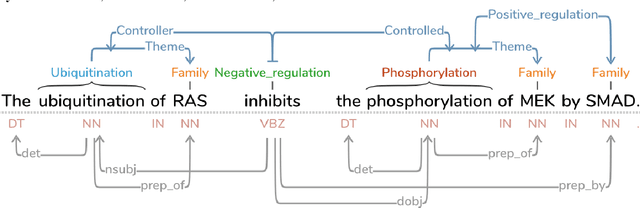
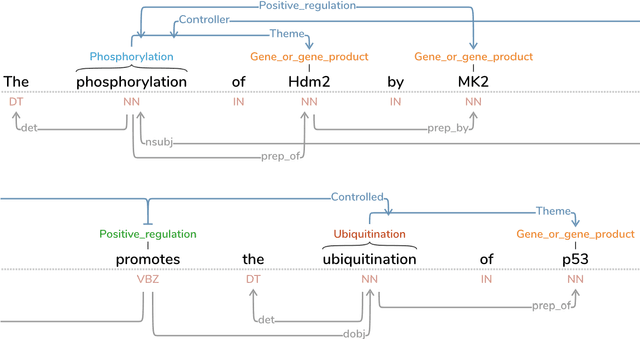
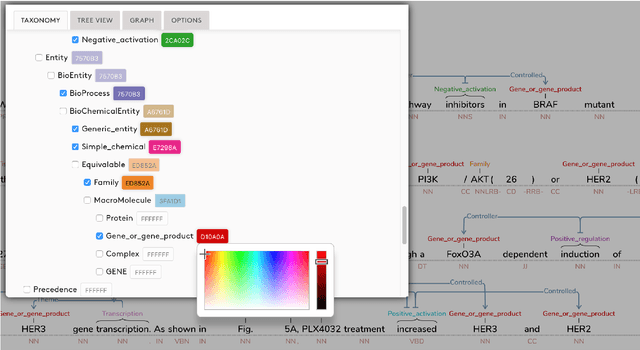
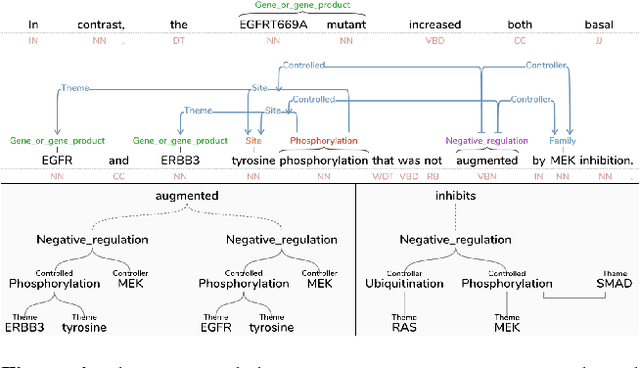
This paper introduces a new web-based software tool for annotating text, Text Annotation Graphs, or TAG. It provides functionality for representing complex relationships between words and word phrases that are not available in other software tools, including the ability to define and visualize relationships between the relationships themselves (semantic hypergraphs). Additionally, we include an approach to representing text annotations in which annotation subgraphs, or semantic summaries, are used to show relationships outside of the sequential context of the text itself. Users can use these subgraphs to quickly find similar structures within the current document or external annotated documents. Initially, TAG was developed to support information extraction tasks on a large database of biomedical articles. However, our software is flexible enough to support a wide range of annotation tasks for any domain. Examples are provided that showcase TAG's capabilities on morphological parsing and event extraction tasks. The TAG software is available at: https://github.com/ CreativeCodingLab/TextAnnotationGraphs.
Sieve-based Coreference Resolution in the Biomedical Domain
Sep 02, 2016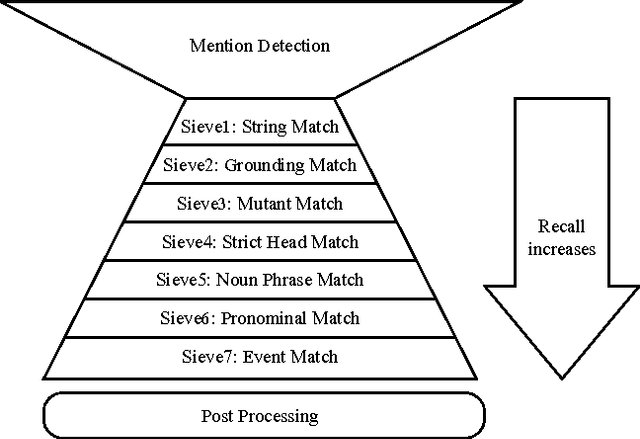



We describe challenges and advantages unique to coreference resolution in the biomedical domain, and a sieve-based architecture that leverages domain knowledge for both entity and event coreference resolution. Domain-general coreference resolution algorithms perform poorly on biomedical documents, because the cues they rely on such as gender are largely absent in this domain, and because they do not encode domain-specific knowledge such as the number and type of participants required in chemical reactions. Moreover, it is difficult to directly encode this knowledge into most coreference resolution algorithms because they are not rule-based. Our rule-based architecture uses sequentially applied hand-designed "sieves", with the output of each sieve informing and constraining subsequent sieves. This architecture provides a 3.2% increase in throughput to our Reach event extraction system with precision parallel to that of the stricter system that relies solely on syntactic patterns for extraction.
This before That: Causal Precedence in the Biomedical Domain
Jun 26, 2016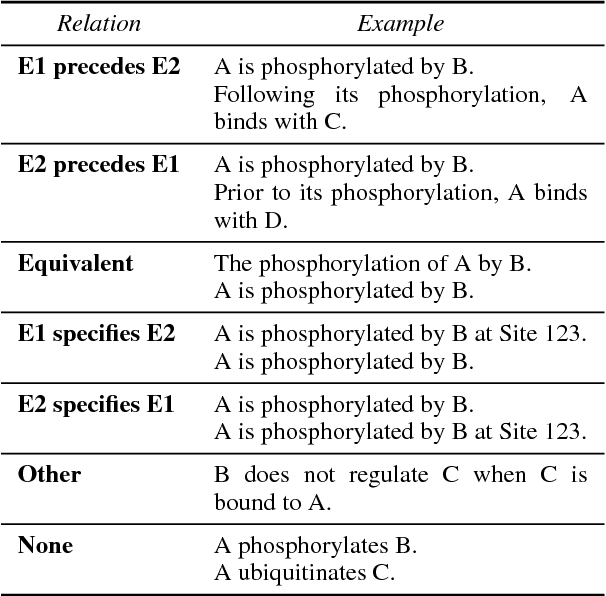
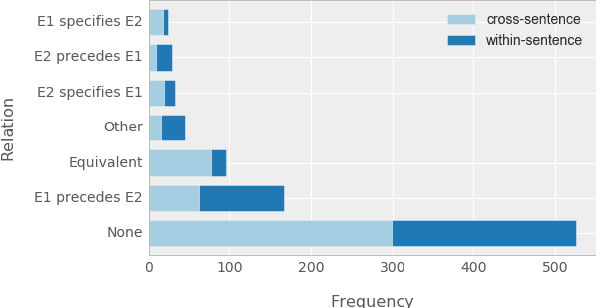
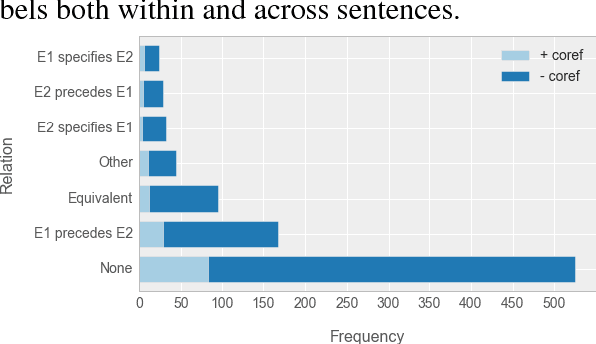
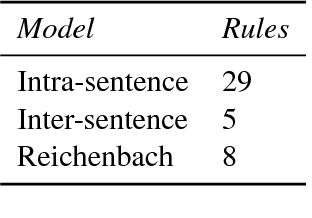
Causal precedence between biochemical interactions is crucial in the biomedical domain, because it transforms collections of individual interactions, e.g., bindings and phosphorylations, into the causal mechanisms needed to inform meaningful search and inference. Here, we analyze causal precedence in the biomedical domain as distinct from open-domain, temporal precedence. First, we describe a novel, hand-annotated text corpus of causal precedence in the biomedical domain. Second, we use this corpus to investigate a battery of models of precedence, covering rule-based, feature-based, and latent representation models. The highest-performing individual model achieved a micro F1 of 43 points, approaching the best performers on the simpler temporal-only precedence tasks. Feature-based and latent representation models each outperform the rule-based models, but their performance is complementary to one another. We apply a sieve-based architecture to capitalize on this lack of overlap, achieving a micro F1 score of 46 points.
Description of the Odin Event Extraction Framework and Rule Language
Sep 24, 2015

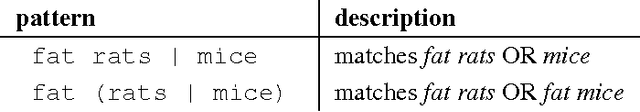

This document describes the Odin framework, which is a domain-independent platform for developing rule-based event extraction models. Odin aims to be powerful (the rule language allows the modeling of complex syntactic structures) and robust (to recover from syntactic parsing errors, syntactic patterns can be freely mixed with surface, token-based patterns), while remaining simple (some domain grammars can be up and running in minutes), and fast (Odin processes over 100 sentences/second in a real-world domain with over 200 rules). Here we include a thorough definition of the Odin rule language, together with a description of the Odin API in the Scala language, which allows one to apply these rules to arbitrary texts.