 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFathomGPT: A Natural Language Interface for Interactively Exploring Ocean Science Data
Dec 03, 2024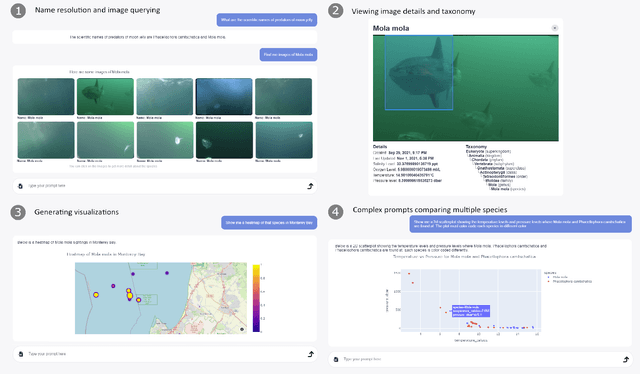

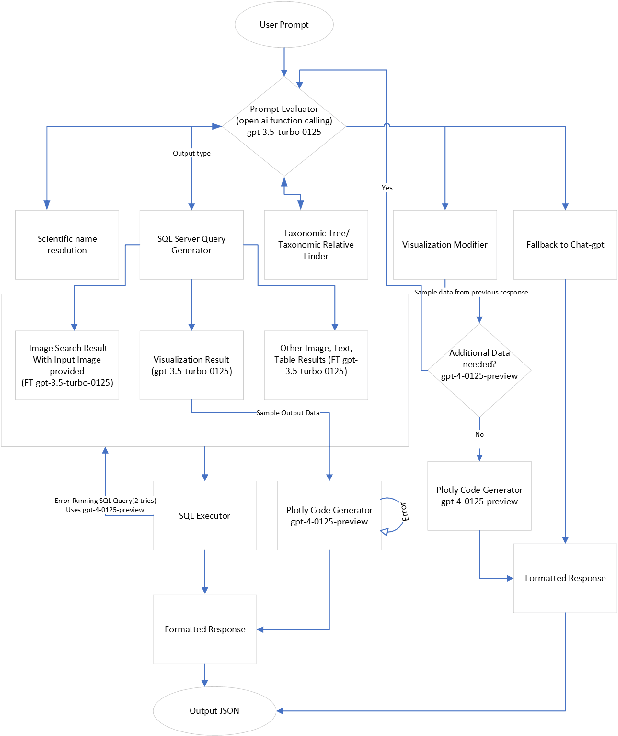

We introduce FathomGPT, an open source system for the interactive investigation of ocean science data via a natural language interface. FathomGPT was developed in close collaboration with marine scientists to enable researchers to explore and analyze the FathomNet image database. FathomGPT provides a custom information retrieval pipeline that leverages OpenAI's large language models to enable: the creation of complex queries to retrieve images, taxonomic information, and scientific measurements; mapping common names and morphological features to scientific names; generating interactive charts on demand; and searching by image or specified patterns within an image. In designing FathomGPT, particular emphasis was placed on enhancing the user's experience by facilitating free-form exploration and optimizing response times. We present an architectural overview and implementation details of FathomGPT, along with a series of ablation studies that demonstrate the effectiveness of our approach to name resolution, fine tuning, and prompt modification. We also present usage scenarios of interactive data exploration sessions and document feedback from ocean scientists and machine learning experts.
* The first two authors contributed equally to this work. Accepted to the 37th Annual ACM Symposium on User Interface Software and Technology (UIST 2024)
Monte Carlo Physarum Machine: Characteristics of Pattern Formation in Continuous Stochastic Transport Networks
Apr 04, 2022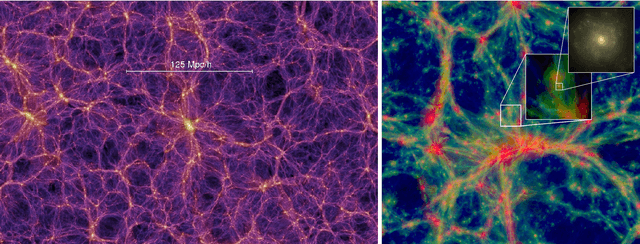

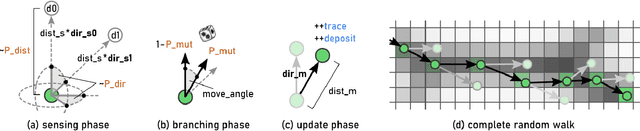
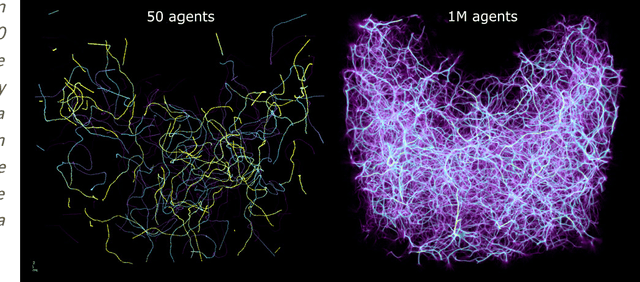
We present Monte Carlo Physarum Machine: a computational model suitable for reconstructing continuous transport networks from sparse 2D and 3D data. MCPM is a probabilistic generalization of Jones's 2010 agent-based model for simulating the growth of Physarum polycephalum slime mold. We compare MCPM to Jones's work on theoretical grounds, and describe a task-specific variant designed for reconstructing the large-scale distribution of gas and dark matter in the Universe known as the Cosmic web. To analyze the new model, we first explore MCPM's self-patterning behavior, showing a wide range of continuous network-like morphologies -- called "polyphorms" -- that the model produces from geometrically intuitive parameters. Applying MCPM to both simulated and observational cosmological datasets, we then evaluate its ability to produce consistent 3D density maps of the Cosmic web. Finally, we examine other possible tasks where MCPM could be useful, along with several examples of fitting to domain-specific data as proofs of concept.
Bio-inspired Structure Identification in Language Embeddings
Sep 15, 2020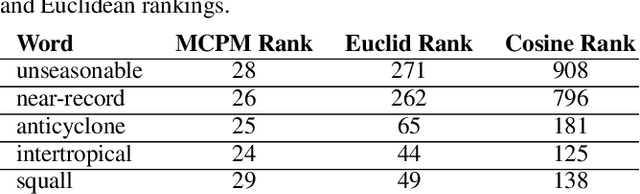
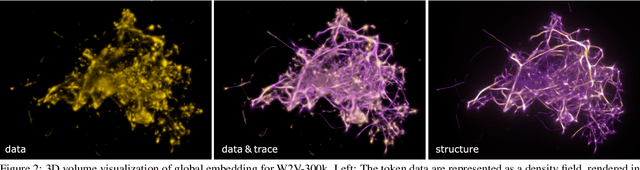

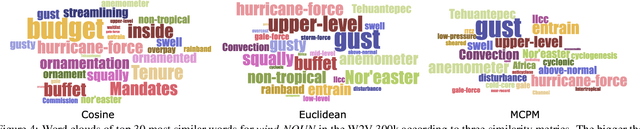
Word embeddings are a popular way to improve downstream performances in contemporary language modeling. However, the underlying geometric structure of the embedding space is not well understood. We present a series of explorations using bio-inspired methodology to traverse and visualize word embeddings, demonstrating evidence of discernible structure. Moreover, our model also produces word similarity rankings that are plausible yet very different from common similarity metrics, mainly cosine similarity and Euclidean distance. We show that our bio-inspired model can be used to investigate how different word embedding techniques result in different semantic outputs, which can emphasize or obscure particular interpretations in textual data.
Text Annotation Graphs: Annotating Complex Natural Language Phenomena
Mar 01, 2018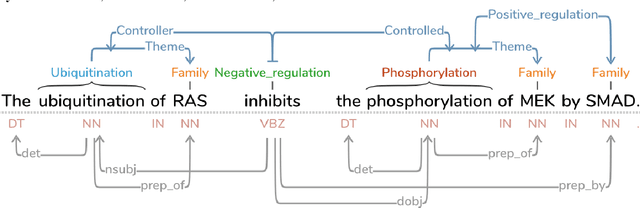
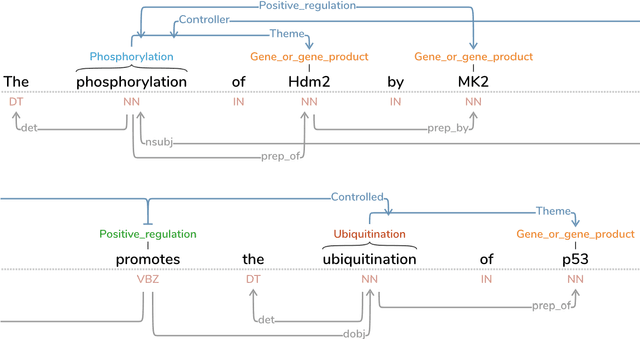
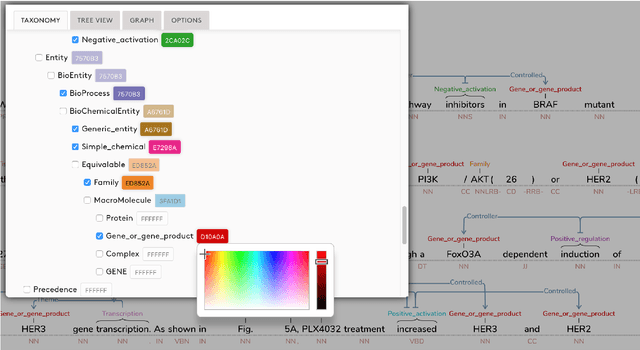
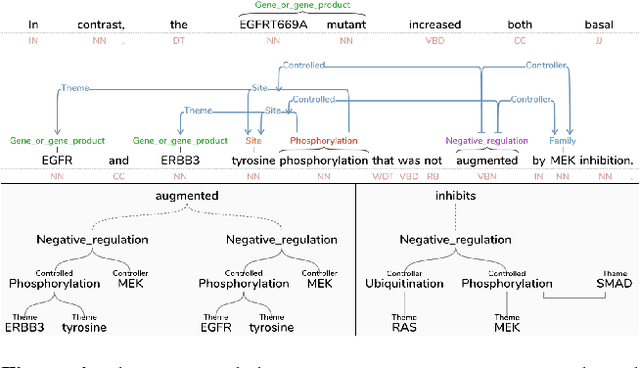
This paper introduces a new web-based software tool for annotating text, Text Annotation Graphs, or TAG. It provides functionality for representing complex relationships between words and word phrases that are not available in other software tools, including the ability to define and visualize relationships between the relationships themselves (semantic hypergraphs). Additionally, we include an approach to representing text annotations in which annotation subgraphs, or semantic summaries, are used to show relationships outside of the sequential context of the text itself. Users can use these subgraphs to quickly find similar structures within the current document or external annotated documents. Initially, TAG was developed to support information extraction tasks on a large database of biomedical articles. However, our software is flexible enough to support a wide range of annotation tasks for any domain. Examples are provided that showcase TAG's capabilities on morphological parsing and event extraction tasks. The TAG software is available at: https://github.com/ CreativeCodingLab/TextAnnotationGraphs.