 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepInv: A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
Jan 04, 2026Diffusion inversion is a task of recovering the noise of an image in a diffusion model, which is vital for controllable diffusion image editing. At present, diffusion inversion still remains a challenging task due to the lack of viable supervision signals. Thus, most existing methods resort to approximation-based solutions, which however are often at the cost of performance or efficiency. To remedy these shortcomings, we propose a novel self-supervised diffusion inversion approach in this paper, termed Deep Inversion (DeepInv). Instead of requiring ground-truth noise annotations, we introduce a self-supervised objective as well as a data augmentation strategy to generate high-quality pseudo noises from real images without manual intervention. Based on these two innovative designs, DeepInv is also equipped with an iterative and multi-scale training regime to train a parameterized inversion solver, thereby achieving the fast and accurate image-to-noise mapping. To the best of our knowledge, this is the first attempt of presenting a trainable solver to predict inversion noise step by step. The extensive experiments show that our DeepInv can achieve much better performance and inference speed than the compared methods, e.g., +40.435% SSIM than EasyInv and +9887.5% speed than ReNoise on COCO dataset. Moreover, our careful designs of trainable solvers can also provide insights to the community. Codes and model parameters will be released in https://github.com/potato-kitty/DeepInv.
Listening, Imagining \& Refining: A Heuristic Optimized ASR Correction Framework with LLMs
Sep 18, 2025Automatic Speech Recognition (ASR) systems remain prone to errors that affect downstream applications. In this paper, we propose LIR-ASR, a heuristic optimized iterative correction framework using LLMs, inspired by human auditory perception. LIR-ASR applies a "Listening-Imagining-Refining" strategy, generating phonetic variants and refining them in context. A heuristic optimization with finite state machine (FSM) is introduced to prevent the correction process from being trapped in local optima and rule-based constraints help maintain semantic fidelity. Experiments on both English and Chinese ASR outputs show that LIR-ASR achieves average reductions in CER/WER of up to 1.5 percentage points compared to baselines, demonstrating substantial accuracy gains in transcription.
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025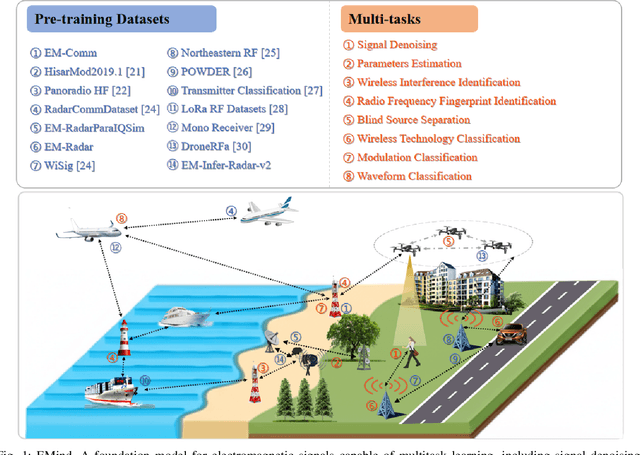
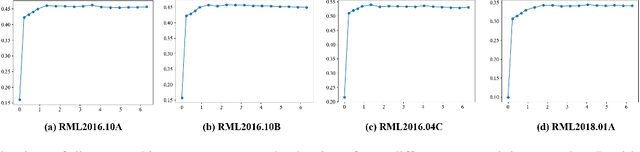
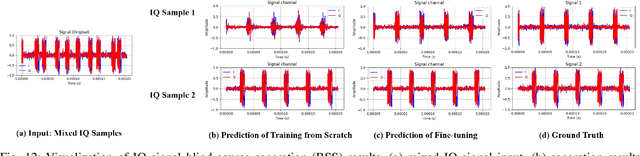
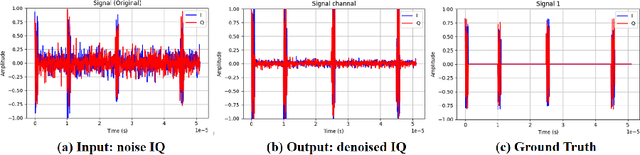
Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
FMSD-TTS: Few-shot Multi-Speaker Multi-Dialect Text-to-Speech Synthesis for Ü-Tsang, Amdo and Kham Speech Dataset Generation
May 20, 2025



Tibetan is a low-resource language with minimal parallel speech corpora spanning its three major dialects-\"U-Tsang, Amdo, and Kham-limiting progress in speech modeling. To address this issue, we propose FMSD-TTS, a few-shot, multi-speaker, multi-dialect text-to-speech framework that synthesizes parallel dialectal speech from limited reference audio and explicit dialect labels. Our method features a novel speaker-dialect fusion module and a Dialect-Specialized Dynamic Routing Network (DSDR-Net) to capture fine-grained acoustic and linguistic variations across dialects while preserving speaker identity. Extensive objective and subjective evaluations demonstrate that FMSD-TTS significantly outperforms baselines in both dialectal expressiveness and speaker similarity. We further validate the quality and utility of the synthesized speech through a challenging speech-to-speech dialect conversion task. Our contributions include: (1) a novel few-shot TTS system tailored for Tibetan multi-dialect speech synthesis, (2) the public release of a large-scale synthetic Tibetan speech corpus generated by FMSD-TTS, and (3) an open-source evaluation toolkit for standardized assessment of speaker similarity, dialect consistency, and audio quality.
TiSpell: A Semi-Masked Methodology for Tibetan Spelling Correction covering Multi-Level Error with Data Augmentation
May 14, 2025Multi-level Tibetan spelling correction addresses errors at both the character and syllable levels within a unified model. Existing methods focus mainly on single-level correction and lack effective integration of both levels. Moreover, there are no open-source datasets or augmentation methods tailored for this task in Tibetan. To tackle this, we propose a data augmentation approach using unlabeled text to generate multi-level corruptions, and introduce TiSpell, a semi-masked model capable of correcting both character- and syllable-level errors. Although syllable-level correction is more challenging due to its reliance on global context, our semi-masked strategy simplifies this process. We synthesize nine types of corruptions on clean sentences to create a robust training set. Experiments on both simulated and real-world data demonstrate that TiSpell, trained on our dataset, outperforms baseline models and matches the performance of state-of-the-art approaches, confirming its effectiveness.
SCOPE-DTI: Semi-Inductive Dataset Construction and Framework Optimization for Practical Usability Enhancement in Deep Learning-Based Drug Target Interaction Prediction
Mar 12, 2025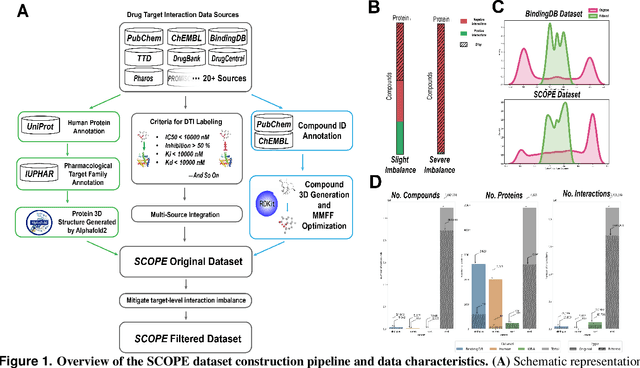
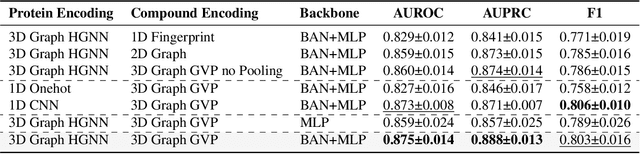
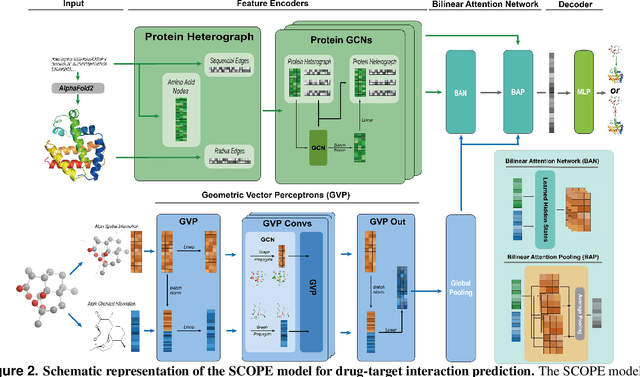
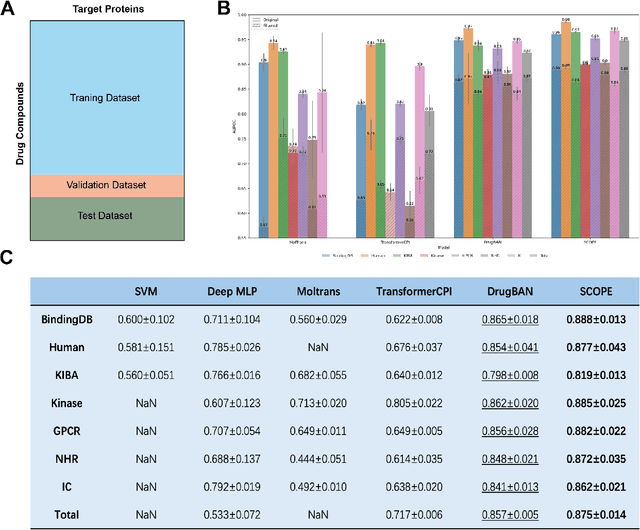
Deep learning-based drug-target interaction (DTI) prediction methods have demonstrated strong performance; however, real-world applicability remains constrained by limited data diversity and modeling complexity. To address these challenges, we propose SCOPE-DTI, a unified framework combining a large-scale, balanced semi-inductive human DTI dataset with advanced deep learning modeling. Constructed from 13 public repositories, the SCOPE dataset expands data volume by up to 100-fold compared to common benchmarks such as the Human dataset. The SCOPE model integrates three-dimensional protein and compound representations, graph neural networks, and bilinear attention mechanisms to effectively capture cross domain interaction patterns, significantly outperforming state-of-the-art methods across various DTI prediction tasks. Additionally, SCOPE-DTI provides a user-friendly interface and database. We further validate its effectiveness by experimentally identifying anticancer targets of Ginsenoside Rh1. By offering comprehensive data, advanced modeling, and accessible tools, SCOPE-DTI accelerates drug discovery research.
LightMotion: A Light and Tuning-free Method for Simulating Camera Motion in Video Generation
Mar 11, 2025Existing camera motion-controlled video generation methods face computational bottlenecks in fine-tuning and inference. This paper proposes LightMotion, a light and tuning-free method for simulating camera motion in video generation. Operating in the latent space, it eliminates additional fine-tuning, inpainting, and depth estimation, making it more streamlined than existing methods. The endeavors of this paper comprise: (i) The latent space permutation operation effectively simulates various camera motions like panning, zooming, and rotation. (ii) The latent space resampling strategy combines background-aware sampling and cross-frame alignment to accurately fill new perspectives while maintaining coherence across frames. (iii) Our in-depth analysis shows that the permutation and resampling cause an SNR shift in latent space, leading to poor-quality generation. To address this, we propose latent space correction, which reintroduces noise during denoising to mitigate SNR shift and enhance video generation quality. Exhaustive experiments show that our LightMotion outperforms existing methods, both quantitatively and qualitatively.
Talking to the brain: Using Large Language Models as Proxies to Model Brain Semantic Representation
Feb 26, 2025



Traditional psychological experiments utilizing naturalistic stimuli face challenges in manual annotation and ecological validity. To address this, we introduce a novel paradigm leveraging multimodal large language models (LLMs) as proxies to extract rich semantic information from naturalistic images through a Visual Question Answering (VQA) strategy for analyzing human visual semantic representation. LLM-derived representations successfully predict established neural activity patterns measured by fMRI (e.g., faces, buildings), validating its feasibility and revealing hierarchical semantic organization across cortical regions. A brain semantic network constructed from LLM-derived representations identifies meaningful clusters reflecting functional and contextual associations. This innovative methodology offers a powerful solution for investigating brain semantic organization with naturalistic stimuli, overcoming limitations of traditional annotation methods and paving the way for more ecologically valid explorations of human cognition.
FathomGPT: A Natural Language Interface for Interactively Exploring Ocean Science Data
Dec 03, 2024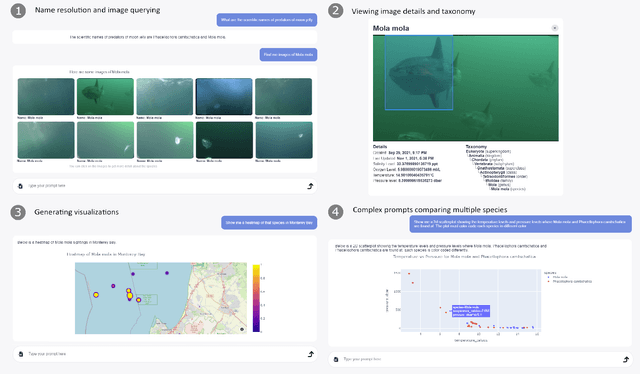

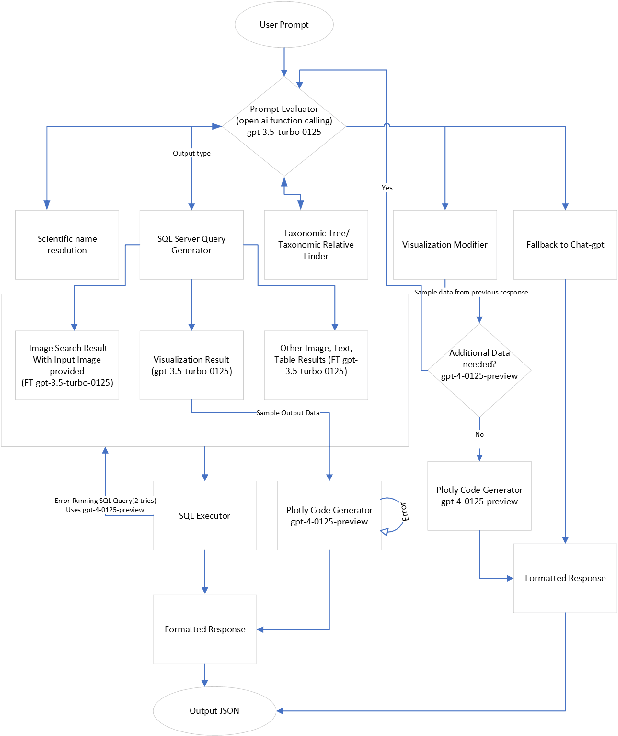

We introduce FathomGPT, an open source system for the interactive investigation of ocean science data via a natural language interface. FathomGPT was developed in close collaboration with marine scientists to enable researchers to explore and analyze the FathomNet image database. FathomGPT provides a custom information retrieval pipeline that leverages OpenAI's large language models to enable: the creation of complex queries to retrieve images, taxonomic information, and scientific measurements; mapping common names and morphological features to scientific names; generating interactive charts on demand; and searching by image or specified patterns within an image. In designing FathomGPT, particular emphasis was placed on enhancing the user's experience by facilitating free-form exploration and optimizing response times. We present an architectural overview and implementation details of FathomGPT, along with a series of ablation studies that demonstrate the effectiveness of our approach to name resolution, fine tuning, and prompt modification. We also present usage scenarios of interactive data exploration sessions and document feedback from ocean scientists and machine learning experts.
* The first two authors contributed equally to this work. Accepted to the 37th Annual ACM Symposium on User Interface Software and Technology (UIST 2024)
EasyInv: Toward Fast and Better DDIM Inversion
Aug 09, 2024



This paper introduces EasyInv, an easy yet novel approach that significantly advances the field of DDIM Inversion by addressing the inherent inefficiencies and performance limitations of traditional iterative optimization methods. At the core of our EasyInv is a refined strategy for approximating inversion noise, which is pivotal for enhancing the accuracy and reliability of the inversion process. By prioritizing the initial latent state, which encapsulates rich information about the original images, EasyInv steers clear of the iterative refinement of noise items. Instead, we introduce a methodical aggregation of the latent state from the preceding time step with the current state, effectively increasing the influence of the initial latent state and mitigating the impact of noise. We illustrate that EasyInv is capable of delivering results that are either on par with or exceed those of the conventional DDIM Inversion approach, especially under conditions where the model's precision is limited or computational resources are scarce. Concurrently, our EasyInv offers an approximate threefold enhancement regarding inference efficiency over off-the-shelf iterative optimization techniques.