 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory-aware adaptive reduced-order models via incremental singular value decomposition
May 27, 2026Reduced-order models (ROMs) can accelerate high-dimensional dynamical simulations, but their accuracy often deteriorates when online dynamics leave the regime represented by offline training data. We develop a projection-based adaptive ROM framework based on incremental singular value decomposition (iSVD), in which occasional full-order operator evaluations provide correction snapshots for online basis updates. The intrusive ROMs considered here are fully parameterized by the basis, so each update naturally propagates to reduced operators and hyper-reduction machinery. Through its evolving singular structure, iSVD retains an encoded history of the observed dynamics and is history-aware in this sense. We study the method on three nonlinear problems of increasing complexity: the one-dimensional viscous Burgers equation, the Sod shock tube, and a stiff one-dimensional ten-species rotating detonation engine (RDE). The Burgers problem is used to analyze the method and compare iSVD with alternative basis adaptation rules, showing that history-aware updates outperform instantaneous updates and that iSVD gives the strongest overall performance. The Sod and RDE cases demonstrate that these advantages persist in more challenging compressible-flow settings. For the RDE problem, the iSVD adaptive ROM improves upon the current state-of-the-art Direct adaptive ROM baseline in both predictive accuracy and computational efficiency. A cost analysis shows that the dominant online cost comes from interacting with the full-order model to obtain correction snapshots, while the iSVD update itself is negligible. These results identify iSVD as an effective mechanism for online learning of reduced subspaces and suggest a path toward ROMs that remain predictive over horizons several orders of magnitude longer than their initial training window.
Evidence Absence Is Not Evidence Insufficiency: Diagnosing NEI Construction Artifacts in Fact Verification
May 26, 2026Evidence absence is not evidence insufficiency, but fact verification benchmarks can make them observationally similar. The Not Enough Information (NEI) label is often operationalized through different evidence conditions, and that choice silently determines what a verifier learns and what its score can hide. We introduce NEI-CAP, a construction-aware diagnostic protocol for insufficient-evidence evaluation. Each NEI example carries the construction family that produced it; NEI-CAP audits shortcut cues, validates hard cases through human adjudication, and tests whether competence transfers across constructions. We instantiate the protocol in SciFact-style scientific verification, with FEVER and HoVer as bounded external controls. Across these settings, NEI competence does not transfer reliably: models trained on shortcut-prone constructions fail to recognize semantically related insufficient evidence, and mixed-construction training narrows but does not close the gap. Fixed-claim diagnostics further show that the evidence condition shifts confidence in the reference Support/Refute label, not only NEI recall, so an aggregate NEI score can hide which problem a model has actually solved.
SURE-RAG: Sufficiency and Uncertainty-Aware Evidence Verification for Selective Retrieval-Augmented Generation
May 05, 2026Retrieval-augmented generation (RAG) grounds answers in retrieved passages, but retrieval is not verification: a passage can be topical and still fail to justify the answer. We frame this gap as evidence sufficiency verification for selective RAG answering: given a question, a candidate answer, and retrieved evidence, predict whether the evidence supports, refutes, or is insufficient, and abstain unless support is established. We present SURE-RAG, a transparent aggregation protocol built on the observation that evidence sufficiency is a set-level property: missing hops and unresolved conflicts cannot be detected by independent passage scoring. A shared pair-level claim-evidence verifier produces local relation distributions, which SURE-RAG aggregates into interpretable answer-level signals -- coverage, relation strength, disagreement, conflict, and retrieval uncertainty -- yielding a three-way decision and an auditable selective score. We evaluate on HotpotQA-RAG v3, a controlled multi-hop benchmark, under an artifact-aware protocol (shortcut baselines, counterfactual swaps, no-oracle checks, GPT-4o audits). Calibrated SURE-RAG reaches 0.9075 Macro-F1 (0.8951 +/- 0.0069), substantially above DeBERTa mean-pooling (0.6516) and a GPT-4o judge (0.7284), while matching a strong but opaque concat cross-encoder (0.8888 +/- 0.0109) with full auditability. Risk at 30% coverage drops from 0.2588 to 0.1642, a 37% reduction in unsafe answers. To deliberately probe the task boundary, we further contrast SURE-RAG with GPT-4o on HaluBench unsafe detection: the ranking reverses (0.3343 vs 0.7389 unsafe-F1), establishing that controlled sufficiency verification and natural hallucination detection are distinct problems.
Geometry Reinforced Efficient Attention Tuning Equipped with Normals for Robust Stereo Matching
Apr 10, 2026Despite remarkable advances in image-driven stereo matching over the past decade, Synthetic-to-Realistic Zero-Shot (Syn-to-Real) generalization remains an open challenge. This suboptimal generalization performance mainly stems from cross-domain shifts and ill-posed ambiguities inherent in image textures, particularly in occluded, textureless, repetitive, and non-Lambertian (specular/transparent) regions. To improve Syn-to-Real generalization, we propose GREATEN, a framework that incorporates surface normals as domain-invariant, object-intrinsic, and discriminative geometric cues to compensate for the limitations of image textures. The proposed framework consists of three key components. First, a Gated Contextual-Geometric Fusion (GCGF) module adaptively suppresses unreliable contextual cues in image features and fuses the filtered image features with normal-driven geometric features to construct domain-invariant and discriminative contextual-geometric representations. Second, a Specular-Transparent Augmentation (STA) strategy improves the robustness of GCGF against misleading visual cues in non-Lambertian regions. Third, sparse attention designs preserve the fine-grained global feature extraction capability of GREAT-Stereo for handling occlusion and texture-related ambiguities while substantially reducing computational overhead, including Sparse Spatial (SSA), Sparse Dual-Matching (SDMA), and Simple Volume (SVA) attentions. Trained exclusively on synthetic data such as SceneFlow, GREATEN-IGEV achieves outstanding Syn-to-Real performance. Specifically, it reduces errors by 30% on ETH3D, 8.5% on the non-Lambertian Booster, and 14.1% on KITTI-2015, compared to FoundationStereo, Monster-Stereo, and DEFOM-Stereo, respectively. In addition, GREATEN-IGEV runs 19.2% faster than GREAT-IGEV and supports high-resolution (3K) inference on Middlebury with disparity ranges up to 768.
Hackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Apr 07, 2026The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Semantic-level Backdoor Attack against Text-to-Image Diffusion Models
Feb 03, 2026Text-to-image (T2I) diffusion models are widely adopted for their strong generative capabilities, yet remain vulnerable to backdoor attacks. Existing attacks typically rely on fixed textual triggers and single-entity backdoor targets, making them highly susceptible to enumeration-based input defenses and attention-consistency detection. In this work, we propose Semantic-level Backdoor Attack (SemBD), which implants backdoors at the representation level by defining triggers as continuous semantic regions rather than discrete textual patterns. Concretely, SemBD injects semantic backdoors by distillation-based editing of the key and value projection matrices in cross-attention layers, enabling diverse prompts with identical semantic compositions to reliably activate the backdoor attack. To further enhance stealthiness, SemBD incorporates a semantic regularization to prevent unintended activation under incomplete semantics, as well as multi-entity backdoor targets that avoid highly consistent cross-attention patterns. Extensive experiments demonstrate that SemBD achieves a 100% attack success rate while maintaining strong robustness against state-of-the-art input-level defenses.
Fair-Eye Net: A Fair, Trustworthy, Multimodal Integrated Glaucoma Full Chain AI System
Jan 26, 2026Glaucoma is a top cause of irreversible blindness globally, making early detection and longitudinal follow-up pivotal to preventing permanent vision loss. Current screening and progression assessment, however, rely on single tests or loosely linked examinations, introducing subjectivity and fragmented care. Limited access to high-quality imaging tools and specialist expertise further compromises consistency and equity in real-world use. To address these gaps, we developed Fair-Eye Net, a fair, reliable multimodal AI system closing the clinical loop from glaucoma screening to follow-up and risk alerting. It integrates fundus photos, OCT structural metrics, VF functional indices, and demographic factors via a dual-stream heterogeneous fusion architecture, with an uncertainty-aware hierarchical gating strategy for selective prediction and safe referral. A fairness constraint reduces missed diagnoses in disadvantaged subgroups. Experimental results show it achieved an AUC of 0.912 (96.7% specificity), cut racial false-negativity disparity by 73.4% (12.31% to 3.28%), maintained stable cross-domain performance, and enabled 3-12 months of early risk alerts (92% sensitivity, 88% specificity). Unlike post hoc fairness adjustments, Fair-Eye Net optimizes fairness as a primary goal with clinical reliability via multitask learning, offering a reproducible path for clinical translation and large-scale deployment to advance global eye health equity.
MEIC-DT: Memory-Efficient Incremental Clustering for Long-Text Coreference Resolution with Dual-Threshold Constraints
Dec 31, 2025In the era of large language models (LLMs), supervised neural methods remain the state-of-the-art (SOTA) for Coreference Resolution. Yet, their full potential is underexplored, particularly in incremental clustering, which faces the critical challenge of balancing efficiency with performance for long texts. To address the limitation, we propose \textbf{MEIC-DT}, a novel dual-threshold, memory-efficient incremental clustering approach based on a lightweight Transformer. MEIC-DT features a dual-threshold constraint mechanism designed to precisely control the Transformer's input scale within a predefined memory budget. This mechanism incorporates a Statistics-Aware Eviction Strategy (\textbf{SAES}), which utilizes distinct statistical profiles from the training and inference phases for intelligent cache management. Furthermore, we introduce an Internal Regularization Policy (\textbf{IRP}) that strategically condenses clusters by selecting the most representative mentions, thereby preserving semantic integrity. Extensive experiments on common benchmarks demonstrate that MEIC-DT achieves highly competitive coreference performance under stringent memory constraints.
From Retrieval to Reasoning: A Framework for Cyber Threat Intelligence NER with Explicit and Adaptive Instructions
Dec 22, 2025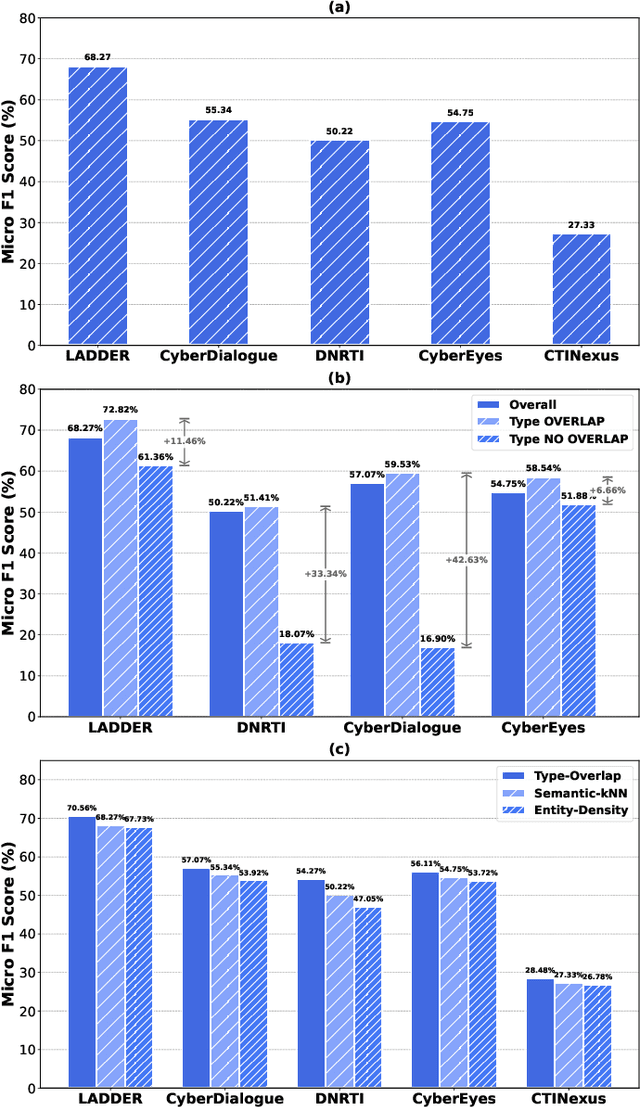
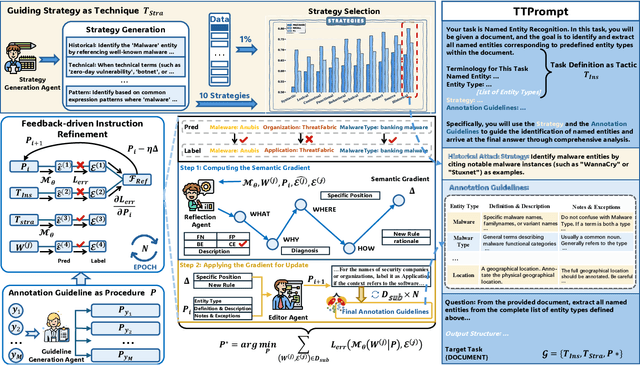
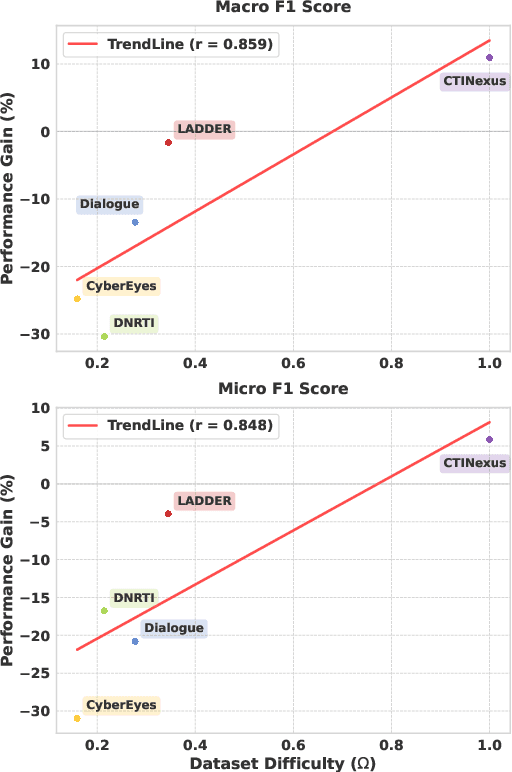
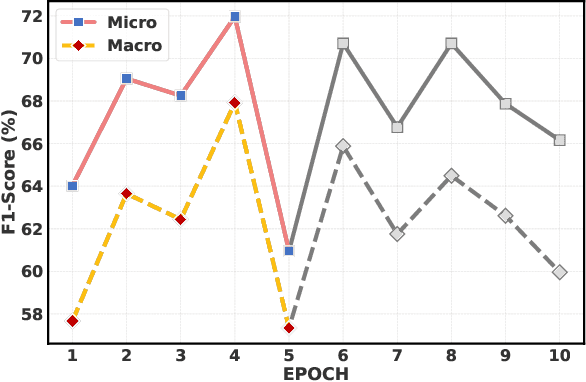
The automation of Cyber Threat Intelligence (CTI) relies heavily on Named Entity Recognition (NER) to extract critical entities from unstructured text. Currently, Large Language Models (LLMs) primarily address this task through retrieval-based In-Context Learning (ICL). This paper analyzes this mainstream paradigm, revealing a fundamental flaw: its success stems not from global semantic similarity but largely from the incidental overlap of entity types within retrieved examples. This exposes the limitations of relying on unreliable implicit induction. To address this, we propose TTPrompt, a framework shifting from implicit induction to explicit instruction. TTPrompt maps the core concepts of CTI's Tactics, Techniques, and Procedures (TTPs) into an instruction hierarchy: formulating task definitions as Tactics, guiding strategies as Techniques, and annotation guidelines as Procedures. Furthermore, to handle the adaptability challenge of static guidelines, we introduce Feedback-driven Instruction Refinement (FIR). FIR enables LLMs to self-refine guidelines by learning from errors on minimal labeled data, adapting to distinct annotation dialects. Experiments on five CTI NER benchmarks demonstrate that TTPrompt consistently surpasses retrieval-based baselines. Notably, with refinement on just 1% of training data, it rivals models fine-tuned on the full dataset. For instance, on LADDER, its Micro F1 of 71.96% approaches the fine-tuned baseline, and on the complex CTINexus, its Macro F1 exceeds the fine-tuned ACLM model by 10.91%.
Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges
Oct 22, 2025Tibetan, one of the major low-resource languages in Asia, presents unique linguistic and sociocultural characteristics that pose both challenges and opportunities for AI research. Despite increasing interest in developing AI systems for underrepresented languages, Tibetan has received limited attention due to a lack of accessible data resources, standardized benchmarks, and dedicated tools. This paper provides a comprehensive survey of the current state of Tibetan AI in the AI domain, covering textual and speech data resources, NLP tasks, machine translation, speech recognition, and recent developments in LLMs. We systematically categorize existing datasets and tools, evaluate methods used across different tasks, and compare performance where possible. We also identify persistent bottlenecks such as data sparsity, orthographic variation, and the lack of unified evaluation metrics. Additionally, we discuss the potential of cross-lingual transfer, multi-modal learning, and community-driven resource creation. This survey aims to serve as a foundational reference for future work on Tibetan AI research and encourages collaborative efforts to build an inclusive and sustainable AI ecosystem for low-resource languages.