 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-stream Spatio-Temporal GCN-Transformer Network for 3D Human Pose Estimation
Apr 20, 20263D human pose estimation is a classic and important research direction in the field of computer vision. In recent years, Transformer-based methods have made significant progress in lifting 2D to 3D human pose estimation. However, these methods primarily focus on modeling global temporal and spatial relationships, neglecting local skeletal relationships and the information interaction between different channels. Therefore, we have proposed a novel method,the Dual-stream Spatio-temporal GCN-Transformer Network (MixTGFormer). This method models the spatial and temporal relationships of human skeletons simultaneously through two parallel channels, achieving effective fusion of global and local features. The core of MixTGFormer is composed of stacked Mixformers. Specifically, the Mixformer includes the Mixformer Block and the Squeeze-and-Excitation Layer ( SE Layer). It first extracts and fuses various information of human skeletons through two parallel Mixformer Blocks with different modes. Then, it further supplements the fused information through the SE Layer. The Mixformer Block integrates Graph Convolutional Networks (GCN) into the Transformer, enhancing both local and global information utilization. Additionally, we further implement its temporal and spatial forms to extract both spatial and temporal relationships. We extensively evaluated our model on two benchmark datasets (Human3.6M and MPI-INF-3DHP). The experimental results showed that, compared to other methods, our MixTGFormer achieved state-of-the-art results, with P1 errors of 37.6mm and 15.7mm on these datasets, respectively.
Credential Leakage in LLM Agent Skills: A Large-Scale Empirical Study
Apr 03, 2026Third-party skills extend LLM agents with powerful capabilities but often handle sensitive credentials in privileged environments, making leakage risks poorly understood. We present the first large-scale empirical study of this problem, analyzing 17,022 skills (sampled from 170,226 on SkillsMP) using static analysis, sandbox testing, and manual inspection. We identify 520 vulnerable skills with 1,708 issues and derive a taxonomy of 10 leakage patterns (4 accidental and 6 adversarial). We find that (1) leakage is fundamentally cross-modal: 76.3% require joint analysis of code and natural language, while 3.1% arise purely from prompt injection; (2) debug logging is the primary vector, with print and console.log causing 73.5% of leaks due to stdout exposure to LLMs; and (3) leaked credentials are both exploitable (89.6% without privileges) and persistent, as forks retain secrets even after upstream fixes. After disclosure, all malicious skills were removed and 91.6% of hardcoded credentials were fixed. We release our dataset, taxonomy, and detection pipeline to support future research.
EBS-CFL: Efficient and Byzantine-robust Secure Clustered Federated Learning
Jun 16, 2025Despite federated learning (FL)'s potential in collaborative learning, its performance has deteriorated due to the data heterogeneity of distributed users. Recently, clustered federated learning (CFL) has emerged to address this challenge by partitioning users into clusters according to their similarity. However, CFL faces difficulties in training when users are unwilling to share their cluster identities due to privacy concerns. To address these issues, we present an innovative Efficient and Robust Secure Aggregation scheme for CFL, dubbed EBS-CFL. The proposed EBS-CFL supports effectively training CFL while maintaining users' cluster identity confidentially. Moreover, it detects potential poisonous attacks without compromising individual client gradients by discarding negatively correlated gradients and aggregating positively correlated ones using a weighted approach. The server also authenticates correct gradient encoding by clients. EBS-CFL has high efficiency with client-side overhead O(ml + m^2) for communication and O(m^2l) for computation, where m is the number of cluster identities, and l is the gradient size. When m = 1, EBS-CFL's computational efficiency of client is at least O(log n) times better than comparison schemes, where n is the number of clients.In addition, we validate the scheme through extensive experiments. Finally, we theoretically prove the scheme's security.
* Accepted by AAAI 25
Learning Unpaired Image Dehazing with Physics-based Rehazy Generation
Jun 15, 2025
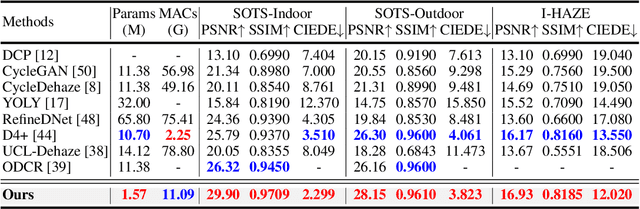
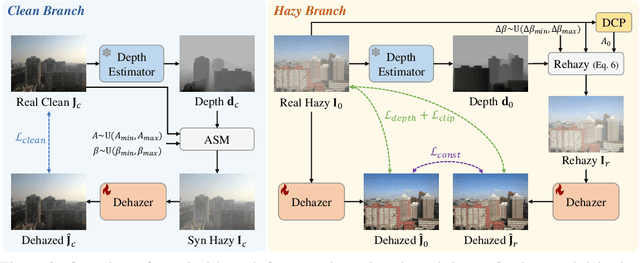
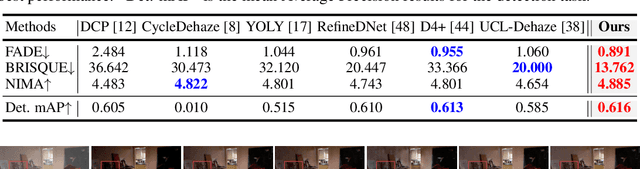
Overfitting to synthetic training pairs remains a critical challenge in image dehazing, leading to poor generalization capability to real-world scenarios. To address this issue, existing approaches utilize unpaired realistic data for training, employing CycleGAN or contrastive learning frameworks. Despite their progress, these methods often suffer from training instability, resulting in limited dehazing performance. In this paper, we propose a novel training strategy for unpaired image dehazing, termed Rehazy, to improve both dehazing performance and training stability. This strategy explores the consistency of the underlying clean images across hazy images and utilizes hazy-rehazy pairs for effective learning of real haze characteristics. To favorably construct hazy-rehazy pairs, we develop a physics-based rehazy generation pipeline, which is theoretically validated to reliably produce high-quality rehazy images. Additionally, leveraging the rehazy strategy, we introduce a dual-branch framework for dehazing network training, where a clean branch provides a basic dehazing capability in a synthetic manner, and a hazy branch enhances the generalization ability with hazy-rehazy pairs. Moreover, we design a new dehazing network within these branches to improve the efficiency, which progressively restores clean scenes from coarse to fine. Extensive experiments on four benchmarks demonstrate the superior performance of our approach, exceeding the previous state-of-the-art methods by 3.58 dB on the SOTS-Indoor dataset and by 1.85 dB on the SOTS-Outdoor dataset in PSNR. Our code will be publicly available.
Transformers in Protein: A Survey
May 27, 2025As protein informatics advances rapidly, the demand for enhanced predictive accuracy, structural analysis, and functional understanding has intensified. Transformer models, as powerful deep learning architectures, have demonstrated unprecedented potential in addressing diverse challenges across protein research. However, a comprehensive review of Transformer applications in this field remains lacking. This paper bridges this gap by surveying over 100 studies, offering an in-depth analysis of practical implementations and research progress of Transformers in protein-related tasks. Our review systematically covers critical domains, including protein structure prediction, function prediction, protein-protein interaction analysis, functional annotation, and drug discovery/target identification. To contextualize these advancements across various protein domains, we adopt a domain-oriented classification system. We first introduce foundational concepts: the Transformer architecture and attention mechanisms, categorize Transformer variants tailored for protein science, and summarize essential protein knowledge. For each research domain, we outline its objectives and background, critically evaluate prior methods and their limitations, and highlight transformative contributions enabled by Transformer models. We also curate and summarize pivotal datasets and open-source code resources to facilitate reproducibility and benchmarking. Finally, we discuss persistent challenges in applying Transformers to protein informatics and propose future research directions. This review aims to provide a consolidated foundation for the synergistic integration of Transformer and protein informatics, fostering further innovation and expanded applications in the field.
Transformer in Protein: A Survey
May 26, 2025As protein informatics advances rapidly, the demand for enhanced predictive accuracy, structural analysis, and functional understanding has intensified. Transformer models, as powerful deep learning architectures, have demonstrated unprecedented potential in addressing diverse challenges across protein research. However, a comprehensive review of Transformer applications in this field remains lacking. This paper bridges this gap by surveying over 100 studies, offering an in-depth analysis of practical implementations and research progress of Transformers in protein-related tasks. Our review systematically covers critical domains, including protein structure prediction, function prediction, protein-protein interaction analysis, functional annotation, and drug discovery/target identification. To contextualize these advancements across various protein domains, we adopt a domain-oriented classification system. We first introduce foundational concepts: the Transformer architecture and attention mechanisms, categorize Transformer variants tailored for protein science, and summarize essential protein knowledge. For each research domain, we outline its objectives and background, critically evaluate prior methods and their limitations, and highlight transformative contributions enabled by Transformer models. We also curate and summarize pivotal datasets and open-source code resources to facilitate reproducibility and benchmarking. Finally, we discuss persistent challenges in applying Transformers to protein informatics and propose future research directions. This review aims to provide a consolidated foundation for the synergistic integration of Transformer and protein informatics, fostering further innovation and expanded applications in the field.
AI-Driven Reinvention of Hydrological Modeling for Accurate Predictions and Interpretation to Transform Earth System Modeling
Jan 07, 2025Traditional equation-driven hydrological models often struggle to accurately predict streamflow in challenging regional Earth systems like the Tibetan Plateau, while hybrid and existing algorithm-driven models face difficulties in interpreting hydrological behaviors. This work introduces HydroTrace, an algorithm-driven, data-agnostic model that substantially outperforms these approaches, achieving a Nash-Sutcliffe Efficiency of 98% and demonstrating strong generalization on unseen data. Moreover, HydroTrace leverages advanced attention mechanisms to capture spatial-temporal variations and feature-specific impacts, enabling the quantification and spatial resolution of streamflow partitioning as well as the interpretation of hydrological behaviors such as glacier-snow-streamflow interactions and monsoon dynamics. Additionally, a large language model (LLM)-based application allows users to easily understand and apply HydroTrace's insights for practical purposes. These advancements position HydroTrace as a transformative tool in hydrological and broader Earth system modeling, offering enhanced prediction accuracy and interpretability.
Optimizing Personalized Federated Learning through Adaptive Layer-Wise Learning
Dec 10, 2024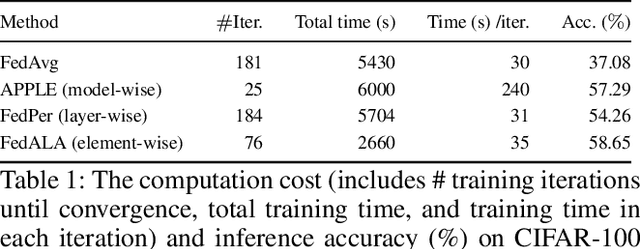
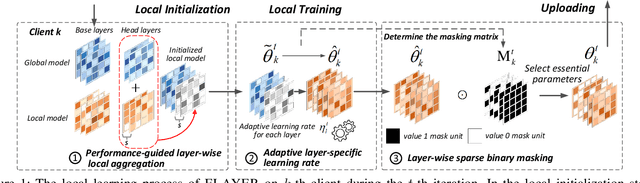
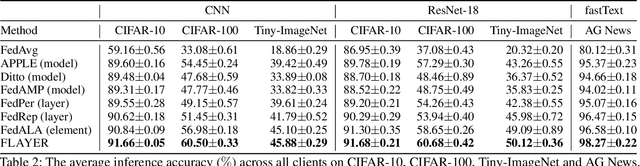
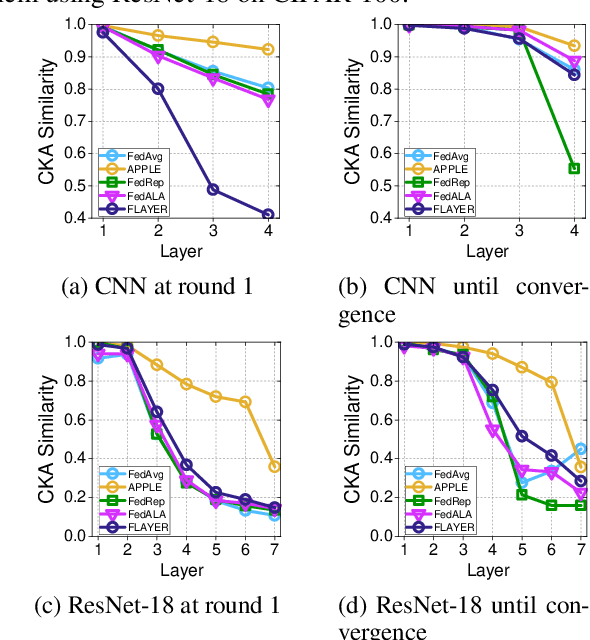
Real-life deployment of federated Learning (FL) often faces non-IID data, which leads to poor accuracy and slow convergence. Personalized FL (pFL) tackles these issues by tailoring local models to individual data sources and using weighted aggregation methods for client-specific learning. However, existing pFL methods often fail to provide each local model with global knowledge on demand while maintaining low computational overhead. Additionally, local models tend to over-personalize their data during the training process, potentially dropping previously acquired global information. We propose FLAYER, a novel layer-wise learning method for pFL that optimizes local model personalization performance. FLAYER considers the different roles and learning abilities of neural network layers of individual local models. It incorporates global information for each local model as needed to initialize the local model cost-effectively. It then dynamically adjusts learning rates for each layer during local training, optimizing the personalized learning process for each local model while preserving global knowledge. Additionally, to enhance global representation in pFL, FLAYER selectively uploads parameters for global aggregation in a layer-wise manner. We evaluate FLAYER on four representative datasets in computer vision and natural language processing domains. Compared to six state-of-the-art pFL methods, FLAYER improves the inference accuracy, on average, by 5.42% (up to 14.29%).
OptLLM: Optimal Assignment of Queries to Large Language Models
May 24, 2024Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
Fast Sampling generative model for Ultrasound image reconstruction
Dec 15, 2023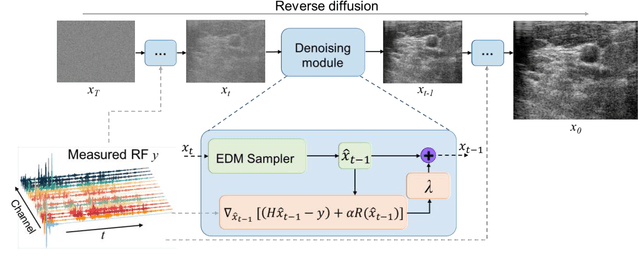

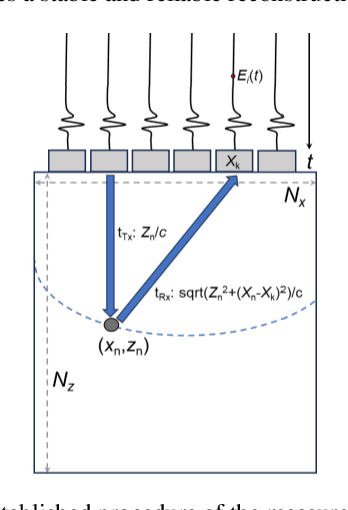
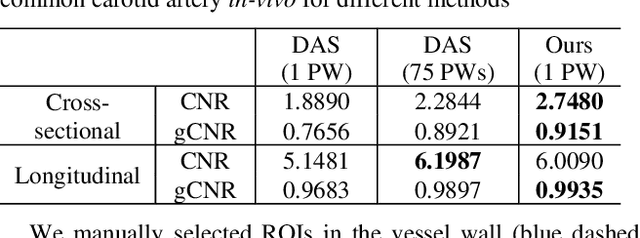
Image reconstruction from radio-frequency data is pivotal in ultrafast plane wave ultrasound imaging. Unlike the conventional delay-and-sum (DAS) technique, which relies on somewhat imprecise assumptions, deep learning-based methods perform image reconstruction by training on paired data, leading to a notable enhancement in image quality. Nevertheless, these strategies often exhibit limited generalization capabilities. Recently, denoising diffusion models have become the preferred paradigm for image reconstruction tasks. However, their reliance on an iterative sampling procedure results in prolonged generation time. In this paper, we propose a novel sampling framework that concurrently enforces data consistency of ultrasound signals and data-driven priors. By leveraging the advanced diffusion model, the generation of high-quality images is substantially expedited. Experimental evaluations on an in-vivo dataset indicate that our approach with a single plane wave surpasses DAS with spatial coherent compounding of 75 plane waves.