 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast-Free Ultrasound Microvascular Imaging via Radiality and Similarity Weighting
Sep 08, 2025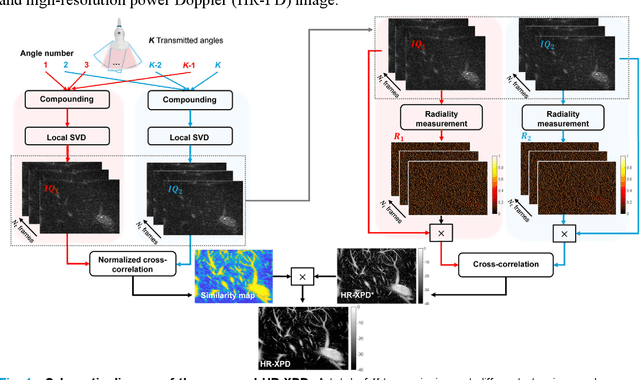
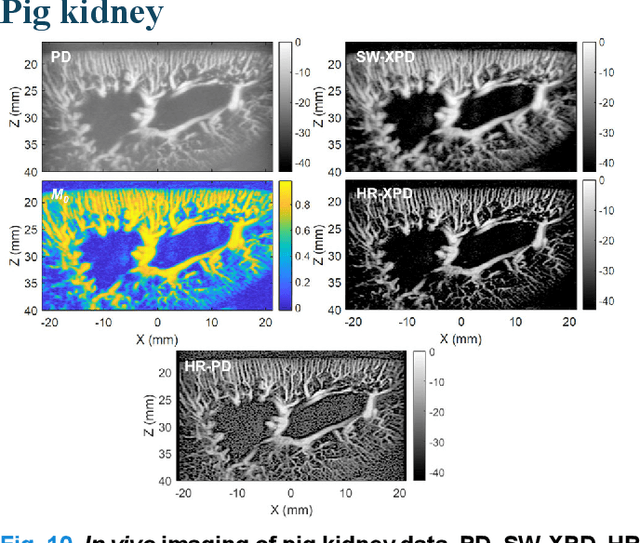
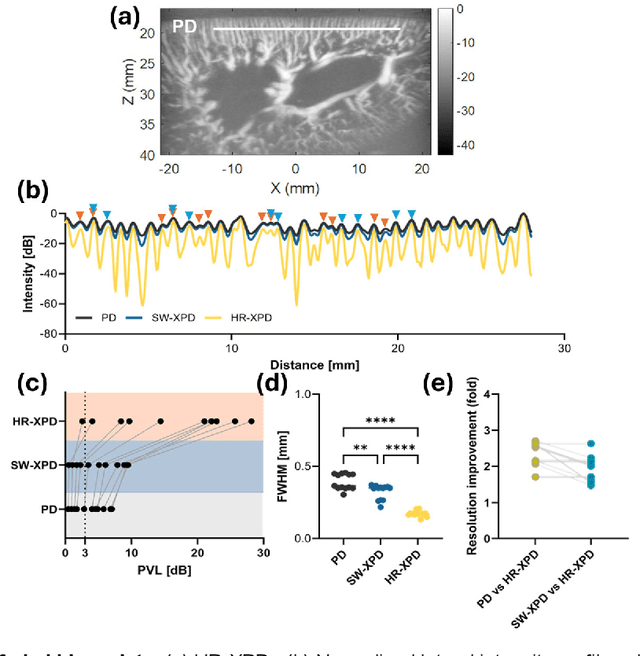
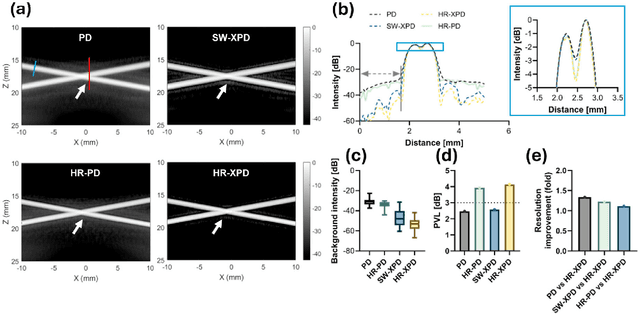
Microvascular imaging has advanced significantly with ultrafast data acquisition and improved clutter filtering, enhancing the sensitivity of power Doppler imaging to small vessels. However, the image quality remains limited by spatial resolution and elevated background noise, both of which impede visualization and accurate quantification. To address these limitations, this study proposes a high-resolution cross-correlation Power Doppler (HR-XPD) method that integrates spatial radiality weighting with Doppler signal coherence analysis, thereby enhancing spatial resolution while suppressing artifacts and background noise. Quantitative evaluations in simulation and in vivo experiments on healthy human liver, transplanted human kidney, and pig kidney demonstrated that HR-XPD significantly improves microvascular resolvability and contrast compared to conventional PD. In vivo results showed up to a 2 to 3-fold enhancement in spatial resolution and an increase in contrast by up to 20 dB. High-resolution vascular details were clearly depicted within a short acquisition time of only 0.3 s-1.2 s without the use of contrast agents. These findings indicate that HR-XPD provides an effective, contrast-free, and high-resolution microvascular imaging approach with broad applicability in both preclinical and clinical research.
Single PW takes a shortcut to compound PW in US imaging
Dec 15, 2023Reconstruction of ultrasound (US) images from radio-frequency data can be conceptualized as a linear inverse problem. Traditional deep learning approaches, which aim to improve the quality of US images by directly learning priors, often encounter challenges in generalization. Recently, diffusion-based generative models have received significant attention within the research community due to their robust performance in image reconstruction tasks. However, a limitation of these models is their inherent low speed in generating image samples from pure Gaussian noise progressively. In this study, we exploit the inherent similarity between the US images reconstructed from a single plane wave (PW) and PW compounding PWC). We hypothesize that a single PW can take a shortcut to reach the diffusion trajectory of PWC, removing the need to begin with Gaussian noise. By employing an advanced diffusion model, we demonstrate its effectiveness in US image reconstruction, achieving a substantial reduction in sampling steps. In-vivo experimental results indicate that our approach can reduce sampling steps by 60%, while preserving comparable performance metrics with the conventional diffusion model.
Cross-domain Unsupervised Reconstruction with Equivariance for Photoacoustic Computed Tomography
Jan 17, 2023Accurate image reconstruction is crucial for photoacoustic (PA) computed tomography (PACT). Recently, deep learning has been used to reconstruct the PA image with a supervised scheme, which requires high-quality images as ground truth labels. In practice, there are inevitable trade-offs between cost and performance since the use of more channels is an expensive strategy to access more measurements. Here, we propose a cross-domain unsupervised reconstruction (CDUR) strategy with a pure transformer model, which overcomes the lack of ground truth labels from limited PA measurements. The proposed approach exploits the equivariance of PACT to achieve high performance with a smaller number of channels. We implement a self-supervised reconstruction in a model-based form. Meanwhile, we also leverage the self-supervision to enforce the measurement and image consistency on three partitions of measured PA data, by randomly masking different channels. We find that dynamically masking a high proportion of the channels, e.g., 80%, yields nontrivial self-supervisors in both image and signal domains, which decrease the multiplicity of the pseudo solution to efficiently reconstruct the image from fewer PA measurements with minimum error of the image. Experimental results on in-vivo PACT dataset of mice demonstrate the potential of our unsupervised framework. In addition, our method shows a high performance (0.83 structural similarity index (SSIM) in the extreme sparse case with 13 channels), which is close to that of supervised scheme (0.77 SSIM with 16 channels). On top of all the advantages, our method may be deployed on different trainable models in an end-to-end manner.
SNEAK: Synonymous Sentences-Aware Adversarial Attack on Natural Language Video Localization
Dec 08, 2021
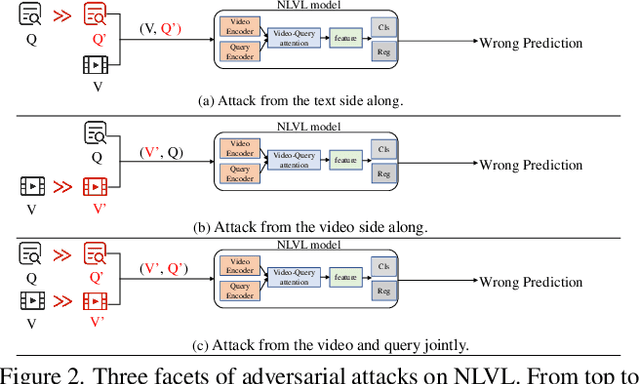
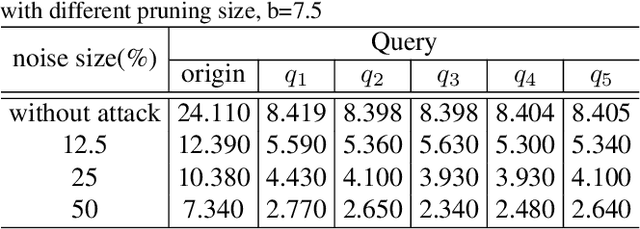

Natural language video localization (NLVL) is an important task in the vision-language understanding area, which calls for an in-depth understanding of not only computer vision and natural language side alone, but more importantly the interplay between both sides. Adversarial vulnerability has been well-recognized as a critical security issue of deep neural network models, which requires prudent investigation. Despite its extensive yet separated studies in video and language tasks, current understanding of the adversarial robustness in vision-language joint tasks like NLVL is less developed. This paper therefore aims to comprehensively investigate the adversarial robustness of NLVL models by examining three facets of vulnerabilities from both attack and defense aspects. To achieve the attack goal, we propose a new adversarial attack paradigm called synonymous sentences-aware adversarial attack on NLVL (SNEAK), which captures the cross-modality interplay between the vision and language sides.