 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Neural Network Predictive Control for Quadruped Locomotion
Mar 10, 2025This study introduces a unified control framework that addresses the challenge of precise quadruped locomotion with unknown payloads, named as online payload identification-based physics-informed neural network predictive control (OPI-PINNPC). By integrating online payload identification with physics-informed neural networks (PINNs), our approach embeds identified mass parameters directly into the neural network's loss function, ensuring physical consistency while adapting to changing load conditions. The physics-constrained neural representation serves as an efficient surrogate model within our nonlinear model predictive controller, enabling real-time optimization despite the complex dynamics of legged locomotion. Experimental validation on our quadruped robot platform demonstrates 35% improvement in position and orientation tracking accuracy across diverse payload conditions (25-100 kg), with substantially faster convergence compared to previous adaptive control methods. Our framework provides a adaptive solution for maintaining locomotion performance under variable payload conditions without sacrificing computational efficiency.
IterPref: Focal Preference Learning for Code Generation via Iterative Debugging
Mar 04, 2025



Preference learning enhances Code LLMs beyond supervised fine-tuning by leveraging relative quality comparisons. Existing methods construct preference pairs from candidates based on test case success, treating the higher pass rate sample as positive and the lower as negative. However, this approach does not pinpoint specific errors in the code, which prevents the model from learning more informative error correction patterns, as aligning failing code as a whole lacks the granularity needed to capture meaningful error-resolution relationships. To address these issues, we propose IterPref, a new preference alignment framework that mimics human iterative debugging to refine Code LLMs. IterPref explicitly locates error regions and aligns the corresponding tokens via a tailored DPO algorithm. To generate informative pairs, we introduce the CodeFlow dataset, where samples are iteratively refined until passing tests, with modifications capturing error corrections. Extensive experiments show that a diverse suite of Code LLMs equipped with IterPref achieves significant performance gains in code generation and improves on challenging tasks like BigCodeBench. In-depth analysis reveals that IterPref yields fewer errors. Our code and data will be made publicaly available.
GATE: Graph-based Adaptive Tool Evolution Across Diverse Tasks
Feb 20, 2025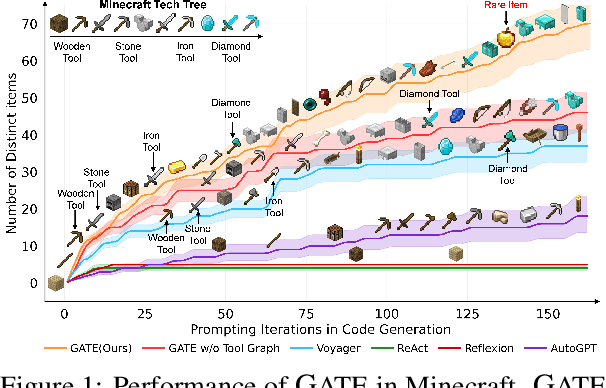
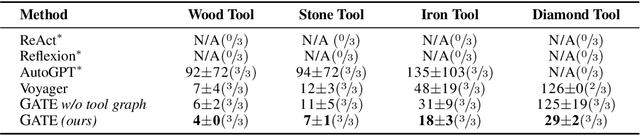
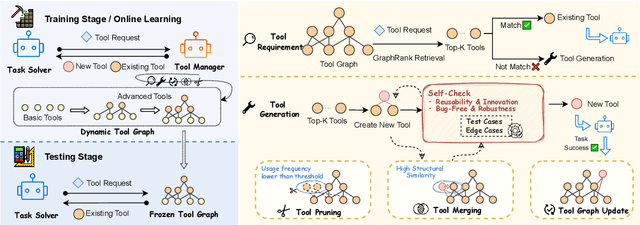
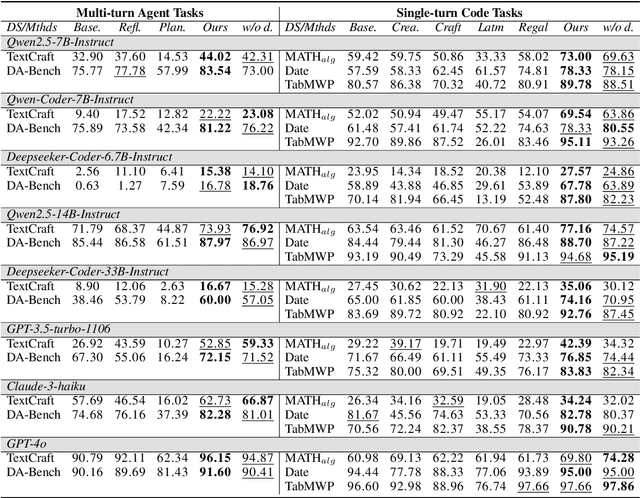
Large Language Models (LLMs) have shown great promise in tool-making, yet existing frameworks often struggle to efficiently construct reliable toolsets and are limited to single-task settings. To address these challenges, we propose GATE (Graph-based Adaptive Tool Evolution), an adaptive framework that dynamically constructs and evolves a hierarchical graph of reusable tools across multiple scenarios. We evaluate GATE on open-ended tasks (Minecraft), agent-based tasks (TextCraft, DABench), and code generation tasks (MATH, Date, TabMWP). Our results show that GATE achieves up to 4.3x faster milestone completion in Minecraft compared to the previous SOTA, and provides an average improvement of 9.23% over existing tool-making methods in code generation tasks and 10.03% in agent tasks. GATE demonstrates the power of adaptive evolution, balancing tool quantity, complexity, and functionality while maintaining high efficiency. Code and data are available at \url{https://github.com/ayanami2003/GATE}.
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
Oct 09, 2024


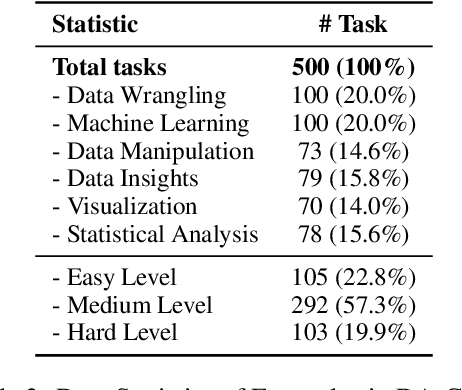
We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [https://da-code-bench.github.io](https://da-code-bench.github.io).
Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics
Apr 08, 2024Large Language Models (LLMs) are undergoing a period of rapid updates and changes, with state-of-the-art (SOTA) model frequently being replaced. When applying LLMs to a specific scientific field, it's challenging to acquire unique domain knowledge while keeping the model itself advanced. To address this challenge, a sophisticated large language model system named as Xiwu has been developed, allowing you switch between the most advanced foundation models and quickly teach the model domain knowledge. In this work, we will report on the best practices for applying LLMs in the field of high-energy physics (HEP), including: a seed fission technology is proposed and some data collection and cleaning tools are developed to quickly obtain domain AI-Ready dataset; a just-in-time learning system is implemented based on the vector store technology; an on-the-fly fine-tuning system has been developed to facilitate rapid training under a specified foundation model. The results show that Xiwu can smoothly switch between foundation models such as LLaMA, Vicuna, ChatGLM and Grok-1. The trained Xiwu model is significantly outperformed the benchmark model on the HEP knowledge question-and-answering and code generation. This strategy significantly enhances the potential for growth of our model's performance, with the hope of surpassing GPT-4 as it evolves with the development of open-source models. This work provides a customized LLM for the field of HEP, while also offering references for applying LLM to other fields, the corresponding codes are available on Github.
Fast Sampling generative model for Ultrasound image reconstruction
Dec 15, 2023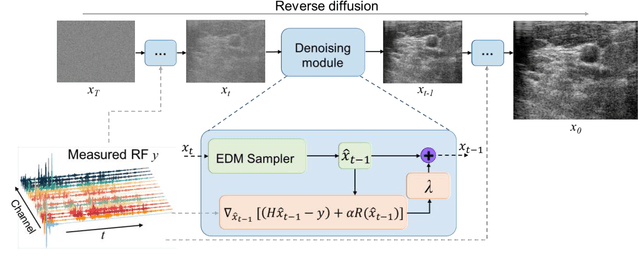

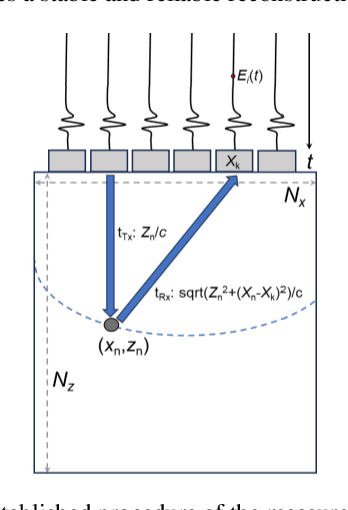
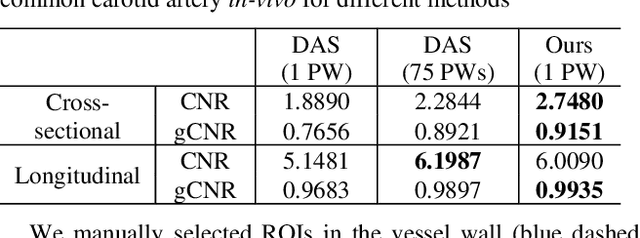
Image reconstruction from radio-frequency data is pivotal in ultrafast plane wave ultrasound imaging. Unlike the conventional delay-and-sum (DAS) technique, which relies on somewhat imprecise assumptions, deep learning-based methods perform image reconstruction by training on paired data, leading to a notable enhancement in image quality. Nevertheless, these strategies often exhibit limited generalization capabilities. Recently, denoising diffusion models have become the preferred paradigm for image reconstruction tasks. However, their reliance on an iterative sampling procedure results in prolonged generation time. In this paper, we propose a novel sampling framework that concurrently enforces data consistency of ultrasound signals and data-driven priors. By leveraging the advanced diffusion model, the generation of high-quality images is substantially expedited. Experimental evaluations on an in-vivo dataset indicate that our approach with a single plane wave surpasses DAS with spatial coherent compounding of 75 plane waves.
Single PW takes a shortcut to compound PW in US imaging
Dec 15, 2023Reconstruction of ultrasound (US) images from radio-frequency data can be conceptualized as a linear inverse problem. Traditional deep learning approaches, which aim to improve the quality of US images by directly learning priors, often encounter challenges in generalization. Recently, diffusion-based generative models have received significant attention within the research community due to their robust performance in image reconstruction tasks. However, a limitation of these models is their inherent low speed in generating image samples from pure Gaussian noise progressively. In this study, we exploit the inherent similarity between the US images reconstructed from a single plane wave (PW) and PW compounding PWC). We hypothesize that a single PW can take a shortcut to reach the diffusion trajectory of PWC, removing the need to begin with Gaussian noise. By employing an advanced diffusion model, we demonstrate its effectiveness in US image reconstruction, achieving a substantial reduction in sampling steps. In-vivo experimental results indicate that our approach can reduce sampling steps by 60%, while preserving comparable performance metrics with the conventional diffusion model.
Score-based Generative Models for Photoacoustic Image Reconstruction with Rotation Consistency Constraints
Jun 24, 2023Photoacoustic tomography (PAT) is a newly emerged imaging modality which enables both high optical contrast and acoustic depth of penetration. Reconstructing images of photoacoustic tomography from limited amount of senser data is among one of the major challenges in photoacoustic imaging. Previous works based on deep learning were trained in supervised fashion, which directly map the input partially known sensor data to the ground truth reconstructed from full field of view. Recently, score-based generative models played an increasingly significant role in generative modeling. Leveraging this probabilistic model, we proposed Rotation Consistency Constrained Score-based Generative Model (RCC-SGM), which recovers the PAT images by iterative sampling between Langevin dynamics and a constraint term utilizing the rotation consistency between the images and the measurements. Our proposed method can generalize to different measurement processes (32.29 PSNR with 16 measurements under random sampling, whereas 28.50 for supervised counterpart), while supervised methods need to train on specific inverse mappings.
Cross-domain Unsupervised Reconstruction with Equivariance for Photoacoustic Computed Tomography
Jan 17, 2023Accurate image reconstruction is crucial for photoacoustic (PA) computed tomography (PACT). Recently, deep learning has been used to reconstruct the PA image with a supervised scheme, which requires high-quality images as ground truth labels. In practice, there are inevitable trade-offs between cost and performance since the use of more channels is an expensive strategy to access more measurements. Here, we propose a cross-domain unsupervised reconstruction (CDUR) strategy with a pure transformer model, which overcomes the lack of ground truth labels from limited PA measurements. The proposed approach exploits the equivariance of PACT to achieve high performance with a smaller number of channels. We implement a self-supervised reconstruction in a model-based form. Meanwhile, we also leverage the self-supervision to enforce the measurement and image consistency on three partitions of measured PA data, by randomly masking different channels. We find that dynamically masking a high proportion of the channels, e.g., 80%, yields nontrivial self-supervisors in both image and signal domains, which decrease the multiplicity of the pseudo solution to efficiently reconstruct the image from fewer PA measurements with minimum error of the image. Experimental results on in-vivo PACT dataset of mice demonstrate the potential of our unsupervised framework. In addition, our method shows a high performance (0.83 structural similarity index (SSIM) in the extreme sparse case with 13 channels), which is close to that of supervised scheme (0.77 SSIM with 16 channels). On top of all the advantages, our method may be deployed on different trainable models in an end-to-end manner.
Kirin: A Quadruped Robot with High Payload Carrying Capability
Feb 21, 2022The quadruped robot is a versatile mobile platform with potential ability for high payload carrying. However, most of the existing quadruped robots aim at high maneuverability, highly dynamic and agile locomotion. In spite of this, payload carrying is still an indispensable ability for the quadruped robots. Design of a quadruped robot with high payload capacity is yet deeply explored. In this study, a 50 kg electrically-actuated quadruped robot, Kirin, is presented to leverage the payload carrying capability. Kirin is an characterized with prismatic quasi-direct-drive (QDD) leg. This mechanism greatly augments the payload carrying capability. This study presents several design principles for the payload-carrying-oriented quadruped robots, including the mechanical design, actuator parameters selection, and locomotion control method. The theoretical analysis implies that the lifting task tends to be a bottleneck for the existing robots with the articulated knee joints. By using prismatic QDD leg, the payload carrying capability of Kirin is enhanced greatly. To demonstrate Kirin's payload carrying capability, in preliminary experiment, up to 125 kg payload lifting in static stance and 50 kg payload carrying in dynamic trotting are tested. Whole body compliance with payload carrying is also demonstrated.