 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle PW takes a shortcut to compound PW in US imaging
Dec 15, 2023Reconstruction of ultrasound (US) images from radio-frequency data can be conceptualized as a linear inverse problem. Traditional deep learning approaches, which aim to improve the quality of US images by directly learning priors, often encounter challenges in generalization. Recently, diffusion-based generative models have received significant attention within the research community due to their robust performance in image reconstruction tasks. However, a limitation of these models is their inherent low speed in generating image samples from pure Gaussian noise progressively. In this study, we exploit the inherent similarity between the US images reconstructed from a single plane wave (PW) and PW compounding PWC). We hypothesize that a single PW can take a shortcut to reach the diffusion trajectory of PWC, removing the need to begin with Gaussian noise. By employing an advanced diffusion model, we demonstrate its effectiveness in US image reconstruction, achieving a substantial reduction in sampling steps. In-vivo experimental results indicate that our approach can reduce sampling steps by 60%, while preserving comparable performance metrics with the conventional diffusion model.
Fast Sampling generative model for Ultrasound image reconstruction
Dec 15, 2023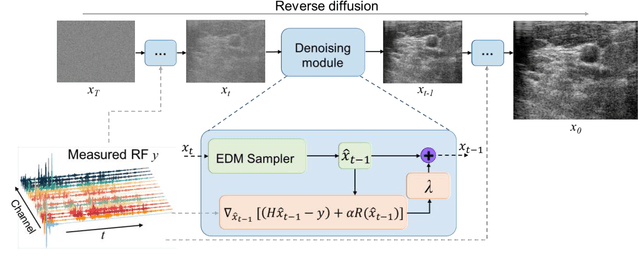

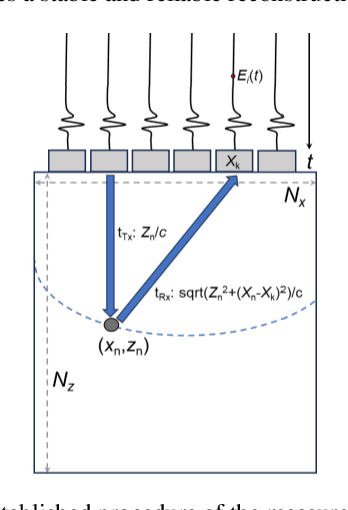
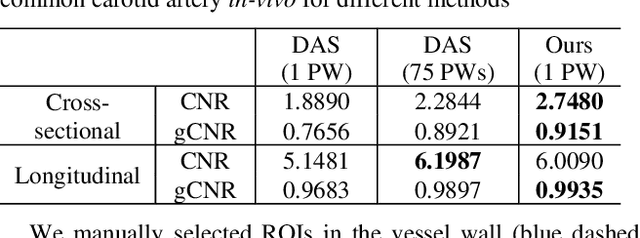
Image reconstruction from radio-frequency data is pivotal in ultrafast plane wave ultrasound imaging. Unlike the conventional delay-and-sum (DAS) technique, which relies on somewhat imprecise assumptions, deep learning-based methods perform image reconstruction by training on paired data, leading to a notable enhancement in image quality. Nevertheless, these strategies often exhibit limited generalization capabilities. Recently, denoising diffusion models have become the preferred paradigm for image reconstruction tasks. However, their reliance on an iterative sampling procedure results in prolonged generation time. In this paper, we propose a novel sampling framework that concurrently enforces data consistency of ultrasound signals and data-driven priors. By leveraging the advanced diffusion model, the generation of high-quality images is substantially expedited. Experimental evaluations on an in-vivo dataset indicate that our approach with a single plane wave surpasses DAS with spatial coherent compounding of 75 plane waves.
Score-based Generative Models for Photoacoustic Image Reconstruction with Rotation Consistency Constraints
Jun 24, 2023Photoacoustic tomography (PAT) is a newly emerged imaging modality which enables both high optical contrast and acoustic depth of penetration. Reconstructing images of photoacoustic tomography from limited amount of senser data is among one of the major challenges in photoacoustic imaging. Previous works based on deep learning were trained in supervised fashion, which directly map the input partially known sensor data to the ground truth reconstructed from full field of view. Recently, score-based generative models played an increasingly significant role in generative modeling. Leveraging this probabilistic model, we proposed Rotation Consistency Constrained Score-based Generative Model (RCC-SGM), which recovers the PAT images by iterative sampling between Langevin dynamics and a constraint term utilizing the rotation consistency between the images and the measurements. Our proposed method can generalize to different measurement processes (32.29 PSNR with 16 measurements under random sampling, whereas 28.50 for supervised counterpart), while supervised methods need to train on specific inverse mappings.
Cross-domain Unsupervised Reconstruction with Equivariance for Photoacoustic Computed Tomography
Jan 17, 2023Accurate image reconstruction is crucial for photoacoustic (PA) computed tomography (PACT). Recently, deep learning has been used to reconstruct the PA image with a supervised scheme, which requires high-quality images as ground truth labels. In practice, there are inevitable trade-offs between cost and performance since the use of more channels is an expensive strategy to access more measurements. Here, we propose a cross-domain unsupervised reconstruction (CDUR) strategy with a pure transformer model, which overcomes the lack of ground truth labels from limited PA measurements. The proposed approach exploits the equivariance of PACT to achieve high performance with a smaller number of channels. We implement a self-supervised reconstruction in a model-based form. Meanwhile, we also leverage the self-supervision to enforce the measurement and image consistency on three partitions of measured PA data, by randomly masking different channels. We find that dynamically masking a high proportion of the channels, e.g., 80%, yields nontrivial self-supervisors in both image and signal domains, which decrease the multiplicity of the pseudo solution to efficiently reconstruct the image from fewer PA measurements with minimum error of the image. Experimental results on in-vivo PACT dataset of mice demonstrate the potential of our unsupervised framework. In addition, our method shows a high performance (0.83 structural similarity index (SSIM) in the extreme sparse case with 13 channels), which is close to that of supervised scheme (0.77 SSIM with 16 channels). On top of all the advantages, our method may be deployed on different trainable models in an end-to-end manner.
Deep Learning Adapted Acceleration for Limited-view Photoacoustic Computed Tomography
Nov 08, 2021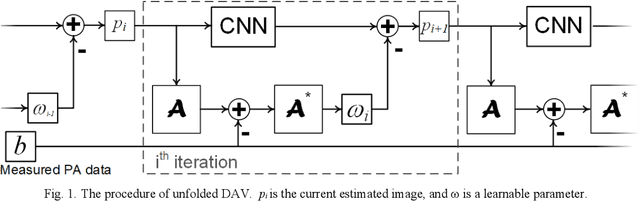
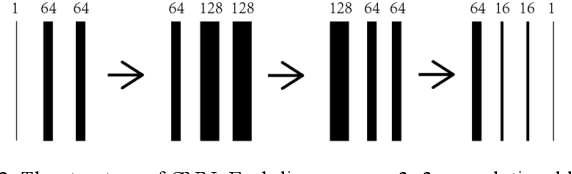
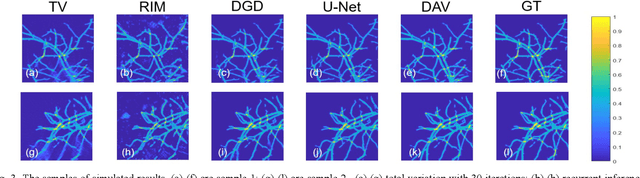
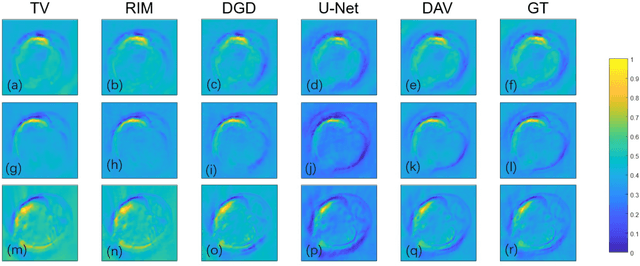
Photoacoustic imaging (PAI) is a non-invasive imaging modality that detects the ultrasound signal generated from tissue with light excitation. Photoacoustic computed tomography (PACT) uses unfocused large-area light to illuminate the target with ultrasound transducer array for PA signal detection. Limited-view issue could cause a low-quality image in PACT due to the limitation of geometric condition. The model-based method is used to resolve this problem, which contains different regularization. To adapt fast and high-quality reconstruction of limited-view PA data, in this paper, a model-based method that combines the mathematical variational model with deep learning is proposed to speed up and regularize the unrolled procedure of reconstruction. A deep neural network is designed to adapt the step of the gradient updated term of data consistency in the gradient descent procedure, which can obtain a high-quality PA image only with a few iterations. Note that all parameters and priors are automatically learned during the offline training stage. In experiments, we show that this method outperforms the other methods with half-view (180 degrees) simulation and real data. The comparison of different model-based methods show that our proposed scheme has superior performances (over 0.05 for SSIM) with same iteration (3 times) steps. Furthermore, an unseen data is used to validate the generalization of different methods. Finally, we find that our method obtains superior results (0.94 value of SSIM for in vivo) with a high robustness and accelerated reconstruction.
Compressed Sensing for Photoacoustic Computed Tomography Using an Untrained Neural Network
May 29, 2021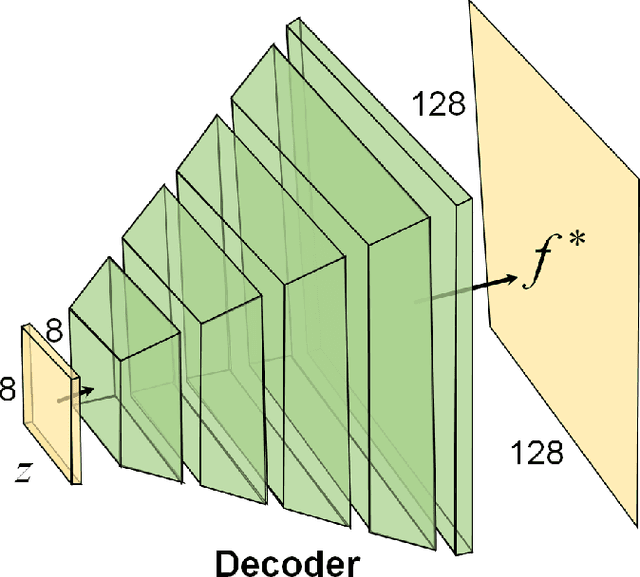
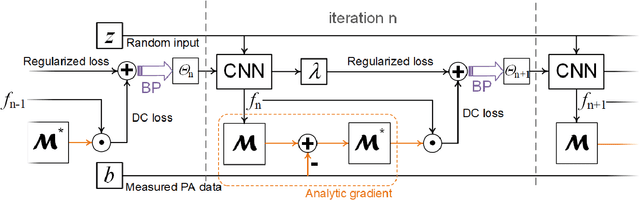
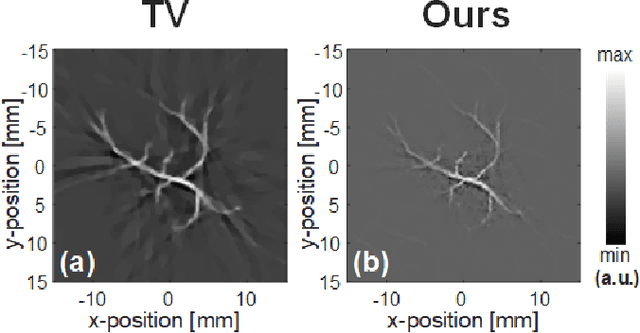
Photoacoustic (PA) computed tomography (PACT) shows great potentials in various preclinical and clinical applications. A great number of measurements are the premise that obtains a high-quality image, which implies a low imaging rate or a high system cost. The artifacts or sidelobes could pollute the image if we decrease the number of measured channels or limit the detected view. In this paper, a novel compressed sensing method for PACT using an untrained neural network is proposed, which decreases half number of the measured channels and recoveries enough details. This method uses a neural network to reconstruct without the requirement for any additional learning based on the deep image prior. The model can reconstruct the image only using a few detections with gradient descent. Our method can cooperate with other existing regularization, and further improve the quality. In addition, we introduce a shape prior to easily converge the model to the image. We verify the feasibility of untrained network based compressed sensing in PA image reconstruction, and compare this method with a conventional method using total variation minimization. The experimental results show that our proposed method outperforms 32.72% (SSIM) with the traditional compressed sensing method in the same regularization. It could dramatically reduce the requirement for the number of transducers, by sparsely sampling the raw PA data, and improve the quality of PA image significantly.
Photoacoustic-monitored laser treatment for tattoo removal: a feasibility study
May 26, 2021

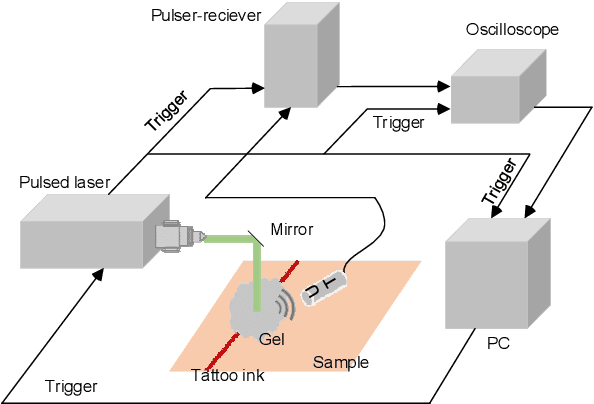
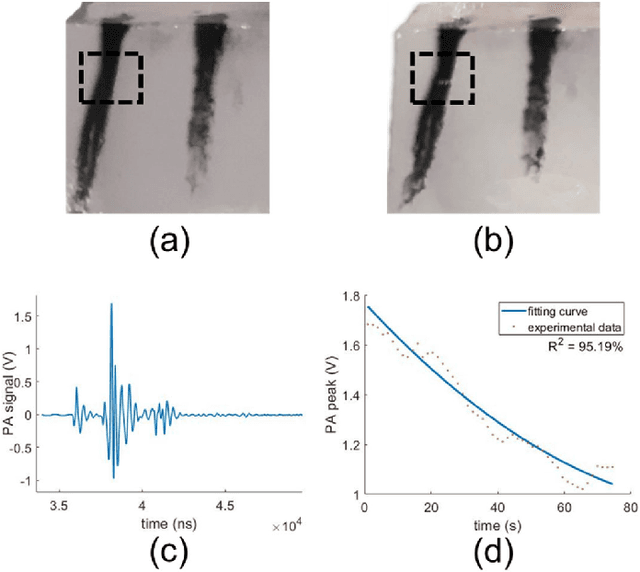
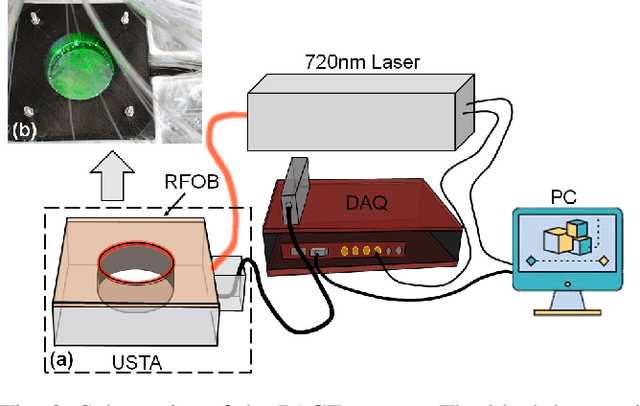
Skin blemishes and diseases have attracted increasing research interest in recent decades, due to their growing frequency of occurrence and the severity of related diseases. Various laser treatment approaches have been introduced for the alleviation and removal of skin pigmentation. The treatments' effects highly depend on the experience and prognosis of the relevant operators. But, the operation process lacks real-time feedback, which may directly reflect the extent of the treatment. In this manuscript, we report a photoacoustic-guided laser treatment method with a feasibility study, specifically for laser treatment targeting the tattoo's removal. The results well validated the feasibility of the proposed method through the experiments on phantoms and ex vivo pig skin samples.
AS-Net: Fast Photoacoustic Reconstruction with Multi-feature Fusion from Sparse Data
Jan 22, 2021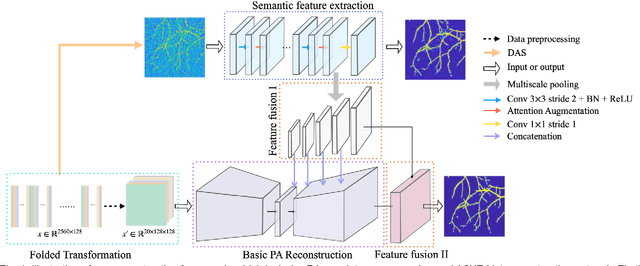
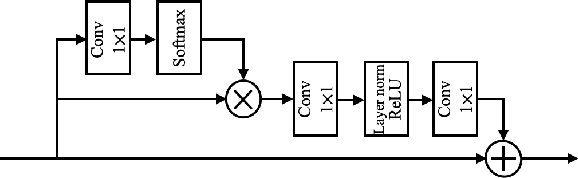

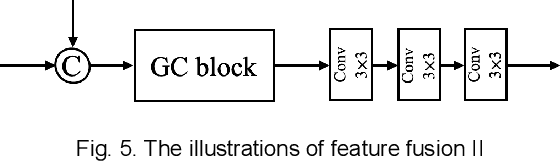
Photoacoustic (PA) imaging is a biomedical imaging modality capable of acquiring high contrast images of optical absorption at depths much greater than traditional optical imaging techniques. However, practical instrumentation and geometry limit the number of available acoustic sensors surrounding the imaging target, which results in sparsity of sensor data. Conventional PA image reconstruction methods give severe artifacts when they are applied directly to these sparse data. In this paper, we first employ a novel signal processing method to make sparse PA raw data more suitable for the neural network, and concurrently speeding up image reconstruction. Then we propose Attention Steered Network (AS-Net) for PA reconstruction with multi-feature fusion. AS-Net is validated on different datasets, including simulated photoacoustic data from fundus vasculature phantoms and real data from in vivo fish and mice imaging experiments. Notably, the method is also able to eliminate some artifacts present in the ground-truth for in vivo data. Results demonstrated that our method provides superior reconstructions at a faster speed.
Better Than Ground-truth? Beyond Supervised Learning for Photoacoustic Imaging Reconstruction
Dec 21, 2020
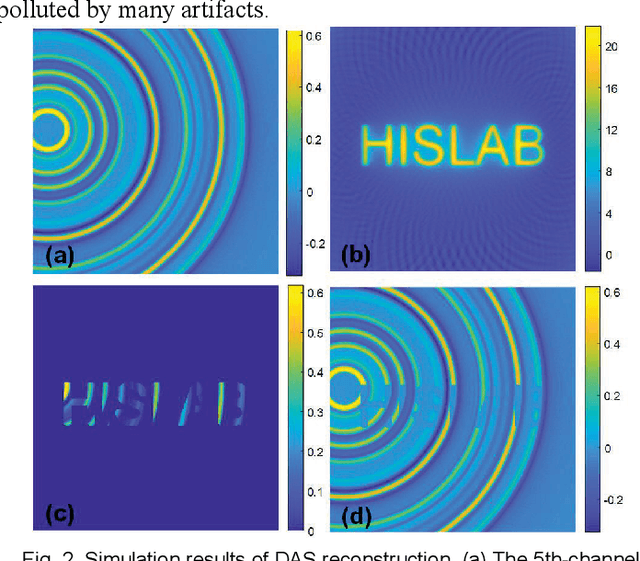
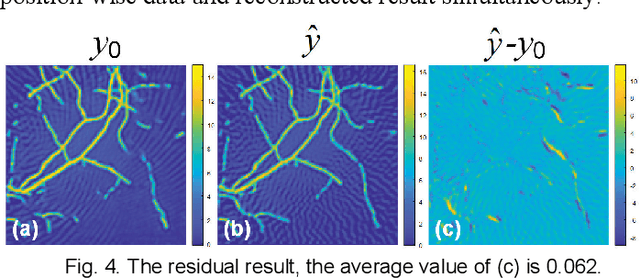
Photoacoustic computed tomography (PACT) reconstructs the initial pressure distribution from raw PA signals. Standard reconstruction always induces artifacts using limited-view signals, which are influenced by limited angle coverage of transducers, finite bandwidth, and uncertain heterogeneous biological tissue. Recently, supervised deep learning has been used to overcome limited-view problem that requires ground-truth. However, even full-view sampling still induces artifacts that cannot be used to train the model. It causes a dilemma that we could not acquire perfect ground-truth in practice. To reduce the dependence on the quality of ground-truth, in this paper, for the first time, we propose a beyond supervised reconstruction framework (BSR-Net) based on deep learning to compensate the limited-view issue by feeding limited-view position-wise data. A quarter position-wise data is fed into model and outputs a group full-view data. Specifically, our method introduces a residual structure, which generates beyond supervised reconstruction result, whose artifacts are drastically reduced in the output compared to ground-truth. Moreover, two novel losses are designed to restrain the artifacts. The numerical and in-vivo results have demonstrated the performance of our method to reconstruct the full-view image without artifacts.
Deep Learning Enables Robust and Precise Light Focusing on Treatment Needs
Aug 16, 2020

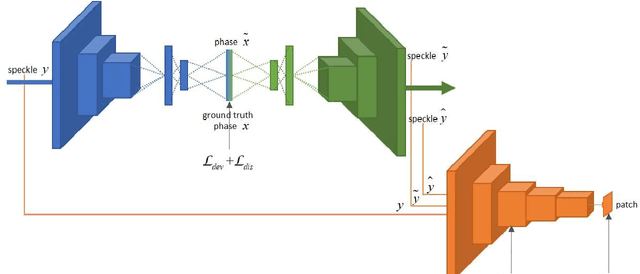
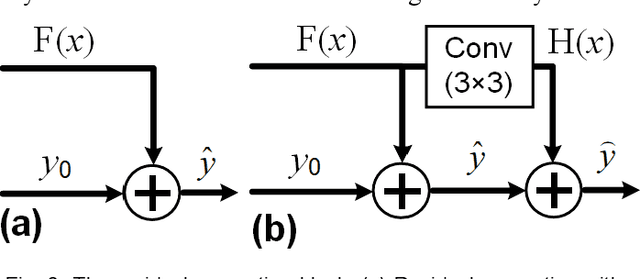
If light passes through the body tissues, focusing only on areas where treatment needs, such as tumors, will revolutionize many biomedical imaging and therapy technologies. So how to focus light through deep inhomogeneous tissues overcoming scattering is Holy Grail in biomedical areas. In this paper, we use deep learning to learn and accelerate the process of phase pre-compensation using wavefront shaping. We present an approach (LoftGAN, light only focuses on treatment needs) for learning the relationship between phase domain X and speckle domain Y . Our goal is not just to learn an inverse mapping F:Y->X such that we can know the corresponding X needed for imaging Y like most work, but also to make focusing that is susceptible to disturbances more robust and precise by ensuring that the phase obtained can be forward mapped back to speckle. So we introduce different constraints to enforce F(Y)=X and H(F(Y))=Y with the transmission mapping H:X->Y. Both simulation and physical experiments are performed to investigate the effects of light focusing to demonstrate the effectiveness of our method and comparative experiments prove the crucial improvement of robustness and precision. Codes are available at https://github.com/ChangchunYang/LoftGAN.