 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViBES: A Conversational Agent with Behaviorally-Intelligent 3D Virtual Body
Dec 16, 2025



Human communication is inherently multimodal and social: words, prosody, and body language jointly carry intent. Yet most prior systems model human behavior as a translation task co-speech gesture or text-to-motion that maps a fixed utterance to motion clips-without requiring agentic decision-making about when to move, what to do, or how to adapt across multi-turn dialogue. This leads to brittle timing, weak social grounding, and fragmented stacks where speech, text, and motion are trained or inferred in isolation. We introduce ViBES (Voice in Behavioral Expression and Synchrony), a conversational 3D agent that jointly plans language and movement and executes dialogue-conditioned body actions. Concretely, ViBES is a speech-language-behavior (SLB) model with a mixture-of-modality-experts (MoME) backbone: modality-partitioned transformer experts for speech, facial expression, and body motion. The model processes interleaved multimodal token streams with hard routing by modality (parameters are split per expert), while sharing information through cross-expert attention. By leveraging strong pretrained speech-language models, the agent supports mixed-initiative interaction: users can speak, type, or issue body-action directives mid-conversation, and the system exposes controllable behavior hooks for streaming responses. We further benchmark on multi-turn conversation with automatic metrics of dialogue-motion alignment and behavior quality, and observe consistent gains over strong co-speech and text-to-motion baselines. ViBES goes beyond "speech-conditioned motion generation" toward agentic virtual bodies where language, prosody, and movement are jointly generated, enabling controllable, socially competent 3D interaction. Code and data will be made available at: ai.stanford.edu/~juze/ViBES/
InterAgent: Physics-based Multi-agent Command Execution via Diffusion on Interaction Graphs
Dec 12, 2025Humanoid agents are expected to emulate the complex coordination inherent in human social behaviors. However, existing methods are largely confined to single-agent scenarios, overlooking the physically plausible interplay essential for multi-agent interactions. To bridge this gap, we propose InterAgent, the first end-to-end framework for text-driven physics-based multi-agent humanoid control. At its core, we introduce an autoregressive diffusion transformer equipped with multi-stream blocks, which decouples proprioception, exteroception, and action to mitigate cross-modal interference while enabling synergistic coordination. We further propose a novel interaction graph exteroception representation that explicitly captures fine-grained joint-to-joint spatial dependencies to facilitate network learning. Additionally, within it we devise a sparse edge-based attention mechanism that dynamically prunes redundant connections and emphasizes critical inter-agent spatial relations, thereby enhancing the robustness of interaction modeling. Extensive experiments demonstrate that InterAgent consistently outperforms multiple strong baselines, achieving state-of-the-art performance. It enables producing coherent, physically plausible, and semantically faithful multi-agent behaviors from only text prompts. Our code and data will be released to facilitate future research.
SocialGen: Modeling Multi-Human Social Interaction with Language Models
Mar 28, 2025Human interactions in everyday life are inherently social, involving engagements with diverse individuals across various contexts. Modeling these social interactions is fundamental to a wide range of real-world applications. In this paper, we introduce SocialGen, the first unified motion-language model capable of modeling interaction behaviors among varying numbers of individuals, to address this crucial yet challenging problem. Unlike prior methods that are limited to two-person interactions, we propose a novel social motion representation that supports tokenizing the motions of an arbitrary number of individuals and aligning them with the language space. This alignment enables the model to leverage rich, pretrained linguistic knowledge to better understand and reason about human social behaviors. To tackle the challenges of data scarcity, we curate a comprehensive multi-human interaction dataset, SocialX, enriched with textual annotations. Leveraging this dataset, we establish the first comprehensive benchmark for multi-human interaction tasks. Our method achieves state-of-the-art performance across motion-language tasks, setting a new standard for multi-human interaction modeling.
LLaVA-SLT: Visual Language Tuning for Sign Language Translation
Dec 21, 2024



In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.
The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Dec 13, 2024Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: languageofmotion.github.io.
HOI-M3:Capture Multiple Humans and Objects Interaction within Contextual Environment
Apr 02, 2024



Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M3 dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M3 dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.
BOTH2Hands: Inferring 3D Hands from Both Text Prompts and Body Dynamics
Dec 20, 2023
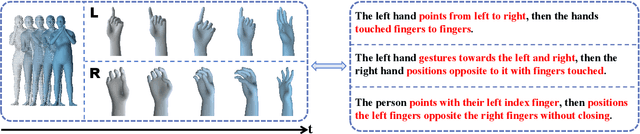
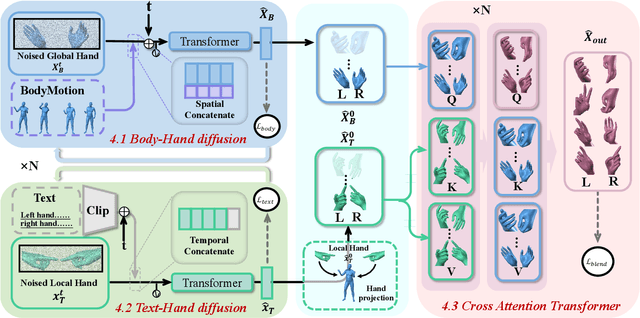

The recently emerging text-to-motion advances have spired numerous attempts for convenient and interactive human motion generation. Yet, existing methods are largely limited to generating body motions only without considering the rich two-hand motions, let alone handling various conditions like body dynamics or texts. To break the data bottleneck, we propose BOTH57M, a novel multi-modal dataset for two-hand motion generation. Our dataset includes accurate motion tracking for the human body and hands and provides pair-wised finger-level hand annotations and body descriptions. We further provide a strong baseline method, BOTH2Hands, for the novel task: generating vivid two-hand motions from both implicit body dynamics and explicit text prompts. We first warm up two parallel body-to-hand and text-to-hand diffusion models and then utilize the cross-attention transformer for motion blending. Extensive experiments and cross-validations demonstrate the effectiveness of our approach and dataset for generating convincing two-hand motions from the hybrid body-and-textual conditions. Our dataset and code will be disseminated to the community for future research.
I'M HOI: Inertia-aware Monocular Capture of 3D Human-Object Interactions
Dec 10, 2023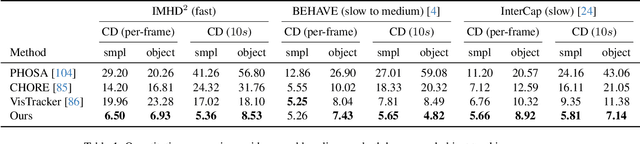
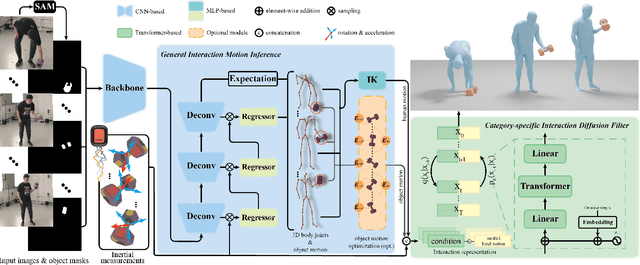
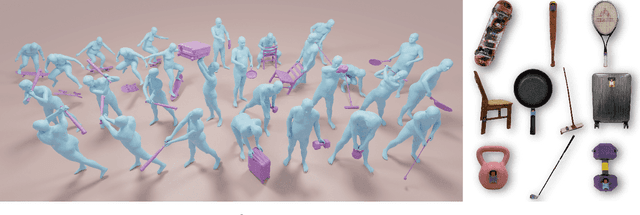
We are living in a world surrounded by diverse and "smart" devices with rich modalities of sensing ability. Conveniently capturing the interactions between us humans and these objects remains far-reaching. In this paper, we present I'm-HOI, a monocular scheme to faithfully capture the 3D motions of both the human and object in a novel setting: using a minimal amount of RGB camera and object-mounted Inertial Measurement Unit (IMU). It combines general motion inference and category-aware refinement. For the former, we introduce a holistic human-object tracking method to fuse the IMU signals and the RGB stream and progressively recover the human motions and subsequently the companion object motions. For the latter, we tailor a category-aware motion diffusion model, which is conditioned on both the raw IMU observations and the results from the previous stage under over-parameterization representation. It significantly refines the initial results and generates vivid body, hand, and object motions. Moreover, we contribute a large dataset with ground truth human and object motions, dense RGB inputs, and rich object-mounted IMU measurements. Extensive experiments demonstrate the effectiveness of I'm-HOI under a hybrid capture setting. Our dataset and code will be released to the community.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 12, 2023This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
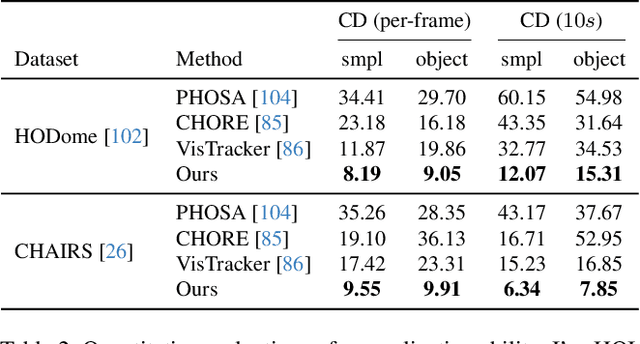
NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Dec 15, 2022
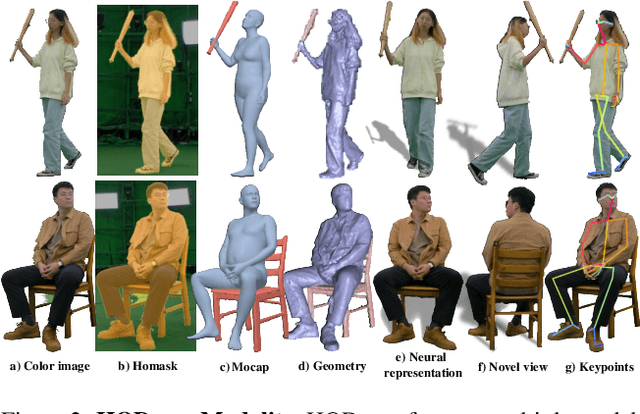
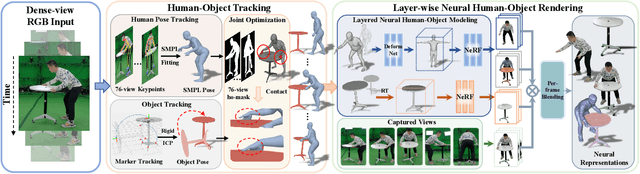
Humans constantly interact with objects in daily life tasks. Capturing such processes and subsequently conducting visual inferences from a fixed viewpoint suffers from occlusions, shape and texture ambiguities, motions, etc. To mitigate the problem, it is essential to build a training dataset that captures free-viewpoint interactions. We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of $\sim$75M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects. Extensive experiments on the HODome dataset demonstrate the effectiveness of NeuralDome on a variety of inference, modeling, and rendering tasks. Both the dataset and the NeuralDome tools will be disseminated to the community for further development.