 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
InterAgent: Physics-based Multi-agent Command Execution via Diffusion on Interaction Graphs
Dec 12, 2025Humanoid agents are expected to emulate the complex coordination inherent in human social behaviors. However, existing methods are largely confined to single-agent scenarios, overlooking the physically plausible interplay essential for multi-agent interactions. To bridge this gap, we propose InterAgent, the first end-to-end framework for text-driven physics-based multi-agent humanoid control. At its core, we introduce an autoregressive diffusion transformer equipped with multi-stream blocks, which decouples proprioception, exteroception, and action to mitigate cross-modal interference while enabling synergistic coordination. We further propose a novel interaction graph exteroception representation that explicitly captures fine-grained joint-to-joint spatial dependencies to facilitate network learning. Additionally, within it we devise a sparse edge-based attention mechanism that dynamically prunes redundant connections and emphasizes critical inter-agent spatial relations, thereby enhancing the robustness of interaction modeling. Extensive experiments demonstrate that InterAgent consistently outperforms multiple strong baselines, achieving state-of-the-art performance. It enables producing coherent, physically plausible, and semantically faithful multi-agent behaviors from only text prompts. Our code and data will be released to facilitate future research.
STADI: Fine-Grained Step-Patch Diffusion Parallelism for Heterogeneous GPUs
Sep 05, 2025The escalating adoption of diffusion models for applications such as image generation demands efficient parallel inference techniques to manage their substantial computational cost. However, existing diffusion parallelism inference schemes often underutilize resources in heterogeneous multi-GPU environments, where varying hardware capabilities or background tasks cause workload imbalance. This paper introduces Spatio-Temporal Adaptive Diffusion Inference (STADI), a novel framework to accelerate diffusion model inference in such settings. At its core is a hybrid scheduler that orchestrates fine-grained parallelism across both temporal and spatial dimensions. Temporally, STADI introduces a novel computation-aware step allocator applied after warmup phases, using a least-common-multiple-minimizing quantization technique to reduce denoising steps on slower GPUs and execution synchronization. To further minimize GPU idle periods, STADI executes an elastic patch parallelism mechanism that allocates variably sized image patches to GPUs according to their computational capability, ensuring balanced workload distribution through a complementary spatial mechanism. Extensive experiments on both load-imbalanced and heterogeneous multi-GPU clusters validate STADI's efficacy, demonstrating improved load balancing and mitigation of performance bottlenecks. Compared to patch parallelism, a state-of-the-art diffusion inference framework, our method significantly reduces end-to-end inference latency by up to 45% and significantly improves resource utilization on heterogeneous GPUs.
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Aug 26, 2025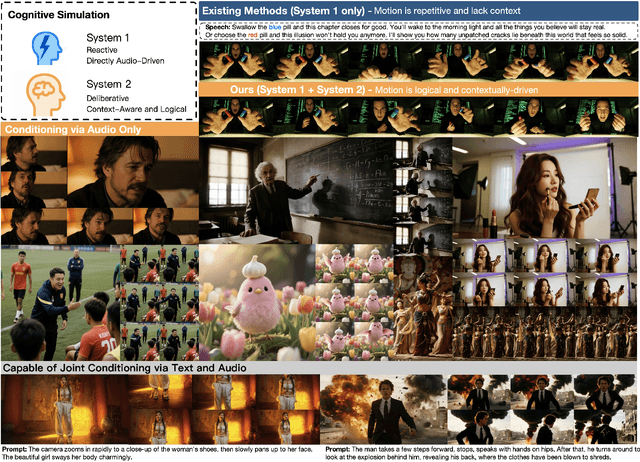
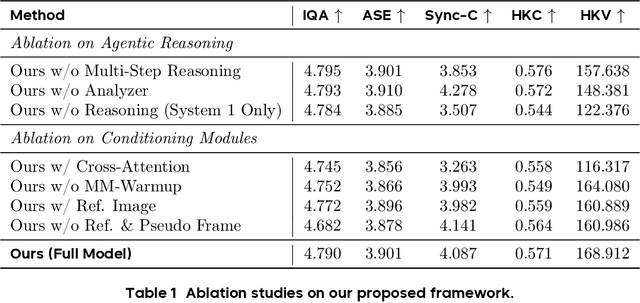
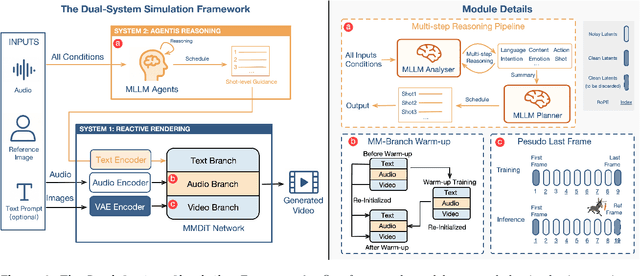

Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character's authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
LLaVA-SLT: Visual Language Tuning for Sign Language Translation
Dec 21, 2024



In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.
FedReMa: Improving Personalized Federated Learning via Leveraging the Most Relevant Clients
Nov 04, 2024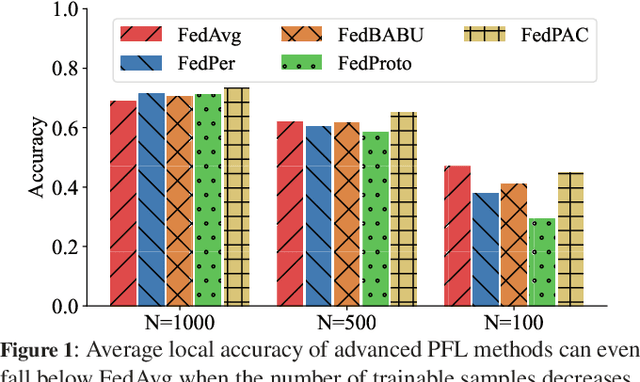
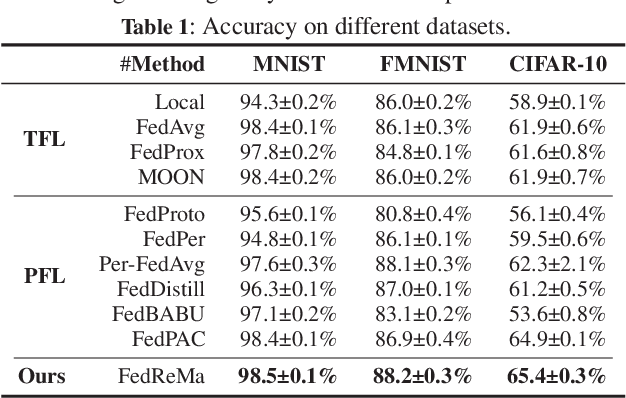
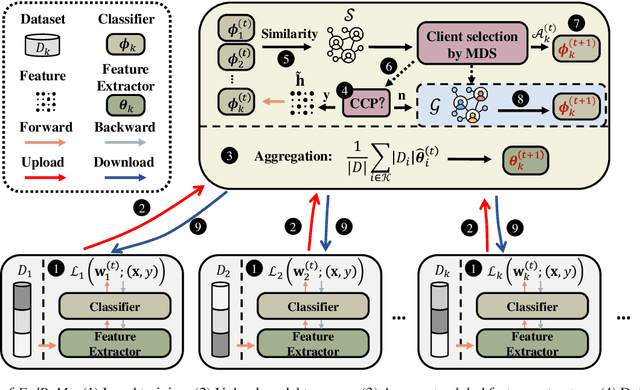
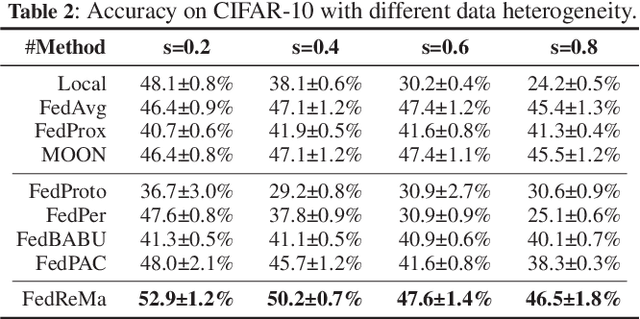
Federated Learning (FL) is a distributed machine learning paradigm that achieves a globally robust model through decentralized computation and periodic model synthesis, primarily focusing on the global model's accuracy over aggregated datasets of all participating clients. Personalized Federated Learning (PFL) instead tailors exclusive models for each client, aiming to enhance the accuracy of clients' individual models on specific local data distributions. Despite of their wide adoption, existing FL and PFL works have yet to comprehensively address the class-imbalance issue, one of the most critical challenges within the realm of data heterogeneity in PFL and FL research. In this paper, we propose FedReMa, an efficient PFL algorithm that can tackle class-imbalance by 1) utilizing an adaptive inter-client co-learning approach to identify and harness different clients' expertise on different data classes throughout various phases of the training process, and 2) employing distinct aggregation methods for clients' feature extractors and classifiers, with the choices informed by the different roles and implications of these model components. Specifically, driven by our experimental findings on inter-client similarity dynamics, we develop critical co-learning period (CCP), wherein we introduce a module named maximum difference segmentation (MDS) to assess and manage task relevance by analyzing the similarities between clients' logits of their classifiers. Outside the CCP, we employ an additional scheme for model aggregation that utilizes historical records of each client's most relevant peers to further enhance the personalization stability. We demonstrate the superiority of our FedReMa in extensive experiments.
Media2Face: Co-speech Facial Animation Generation With Multi-Modality Guidance
Jan 30, 2024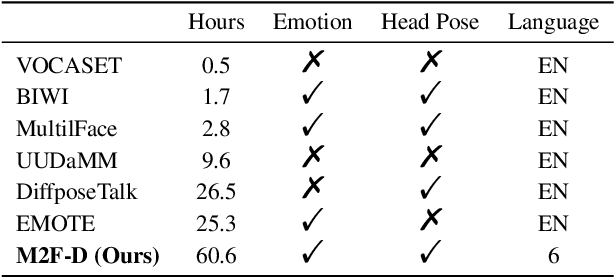
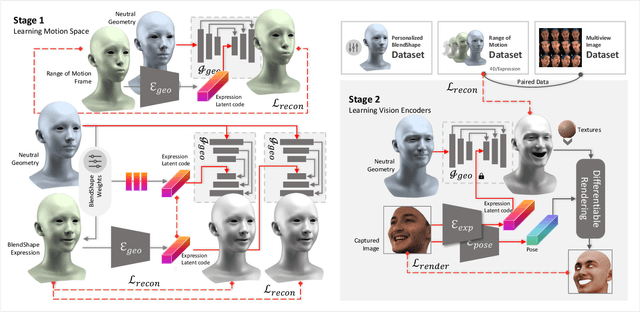

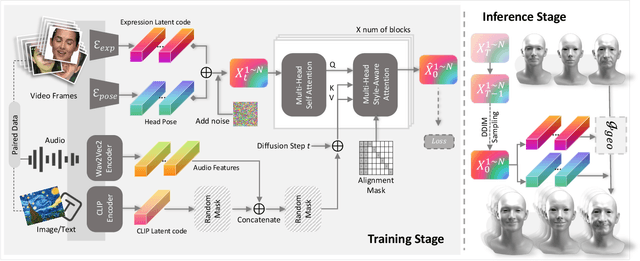
The synthesis of 3D facial animations from speech has garnered considerable attention. Due to the scarcity of high-quality 4D facial data and well-annotated abundant multi-modality labels, previous methods often suffer from limited realism and a lack of lexible conditioning. We address this challenge through a trilogy. We first introduce Generalized Neural Parametric Facial Asset (GNPFA), an efficient variational auto-encoder mapping facial geometry and images to a highly generalized expression latent space, decoupling expressions and identities. Then, we utilize GNPFA to extract high-quality expressions and accurate head poses from a large array of videos. This presents the M2F-D dataset, a large, diverse, and scan-level co-speech 3D facial animation dataset with well-annotated emotional and style labels. Finally, we propose Media2Face, a diffusion model in GNPFA latent space for co-speech facial animation generation, accepting rich multi-modality guidances from audio, text, and image. Extensive experiments demonstrate that our model not only achieves high fidelity in facial animation synthesis but also broadens the scope of expressiveness and style adaptability in 3D facial animation.
OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers
Dec 18, 2023

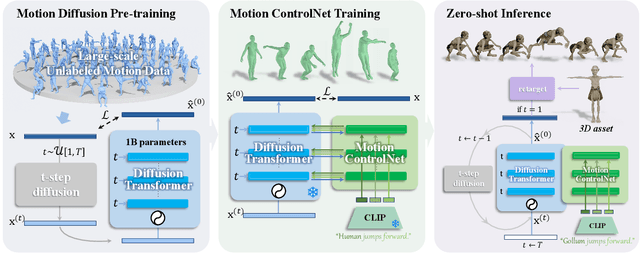
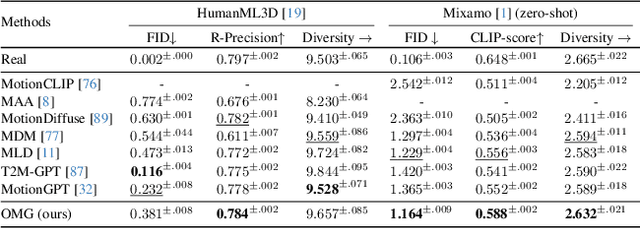
We have recently seen tremendous progress in realistic text-to-motion generation. Yet, the existing methods often fail or produce implausible motions with unseen text inputs, which limits the applications. In this paper, we present OMG, a novel framework, which enables compelling motion generation from zero-shot open-vocabulary text prompts. Our key idea is to carefully tailor the pretrain-then-finetune paradigm into the text-to-motion generation. At the pre-training stage, our model improves the generation ability by learning the rich out-of-domain inherent motion traits. To this end, we scale up a large unconditional diffusion model up to 1B parameters, so as to utilize the massive unlabeled motion data up to over 20M motion instances. At the subsequent fine-tuning stage, we introduce motion ControlNet, which incorporates text prompts as conditioning information, through a trainable copy of the pre-trained model and the proposed novel Mixture-of-Controllers (MoC) block. MoC block adaptively recognizes various ranges of the sub-motions with a cross-attention mechanism and processes them separately with the text-token-specific experts. Such a design effectively aligns the CLIP token embeddings of text prompts to various ranges of compact and expressive motion features. Extensive experiments demonstrate that our OMG achieves significant improvements over the state-of-the-art methods on zero-shot text-to-motion generation. Project page: https://tr3e.github.io/omg-page.
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions
Apr 12, 2023We have recently seen tremendous progress in diffusion advances for generating realistic human motions. Yet, they largely disregard the rich multi-human interactions. In this paper, we present InterGen, an effective diffusion-based approach that incorporates human-to-human interactions into the motion diffusion process, which enables layman users to customize high-quality two-person interaction motions, with only text guidance. We first contribute a multimodal dataset, named InterHuman. It consists of about 107M frames for diverse two-person interactions, with accurate skeletal motions and 16,756 natural language descriptions. For the algorithm side, we carefully tailor the motion diffusion model to our two-person interaction setting. To handle the symmetry of human identities during interactions, we propose two cooperative transformer-based denoisers that explicitly share weights, with a mutual attention mechanism to further connect the two denoising processes. Then, we propose a novel representation for motion input in our interaction diffusion model, which explicitly formulates the global relations between the two performers in the world frame. We further introduce two novel regularization terms to encode spatial relations, equipped with a corresponding damping scheme during the training of our interaction diffusion model. Extensive experiments validate the effectiveness and generalizability of InterGen. Notably, it can generate more diverse and compelling two-person motions than previous methods and enables various downstream applications for human interactions.