 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFRACT: Neuralized Utility Maximization for Wireless Networks by Differentiable Programming
Jun 05, 2026Next-generation wireless networks, including satellite-to-Open RAN systems, demand agile and intelligent resource management capable of handling dynamic multi-user interference under stochastic quality of service constraints. This paper introduces DIFFRACT, a neuralized utility maximization framework that leverages differentiable programming to integrate deep learning with optimization in wireless networks. Central to our approach is the exploitation of the mathematical structure of standard interference functions, which are foundational in wireless power control. By developing a duality theory for these functions, we map iterative interference management algorithms into differentiable neural network architectures via algorithm unrolling. This enables distributed, end-to-end gradient-based learning at the network edge, supporting real-time adaptation to interference in both terrestrial and non-terrestrial environments. DIFFRACT allows for scalable and robust utility maximization by modeling complex channel dynamics and leveraging the expressiveness of differentiable models. Experimental results confirm the framework's theoretical soundness and practical effectiveness for next-generation wireless systems.
Adversarial Water-Filling: Theory, Algorithms and Foundation Model
May 24, 2026Competitive resource allocation problems over frequency and space can be formulated as minimax interaction between transmit power and worst-case interference. This formulation naturally arises in multi-operator low Earth orbit (LEO) satellite spectrum sharing, where transmissions from competing constellations interfere in real-time. Under Gaussian channels, AWF is strongly convex--concave on nondegenerate active channels, whereas discrete constellations yield generally nonconvex mercury/water-filling formulations. In this paper we propose the Adversarial Water-Filling (AWF) problem with corresponding theory and algorithms for these real situations. In addition, we develop a wireless foundation model for AWF to learn the AWF search dynamics. The architecture incorporates permutation-invariant channel representations, a constraint-aware graph neural network (GNN) with sparse message passing, and global latent variables capturing the low-dimensional water level implied by the AWF optimality. Through learned projected extragradient iterations, the model approximates stationary solutions of the constrained minimax problem arising under mercury/water-filling. We further show that, under local regularity and contractivity conditions, the learned AWF dynamics converge locally linearly around regular stationary points. Experiments demonstrate empirical generalization across unseen problem sizes, different constraints, and multiple discrete constellations, while achieving more than one-order-of-magnitude runtime improvements over iterative baselines. The related code can be found at https://github.com/convexsoft/AWF.
Accelerating Regularized Attention Kernel Regression for Spectrum Cartography
Apr 28, 2026Spectrum cartography reconstructs spatial radio fields from sparse and heterogeneous wireless measurements, underpinning many sensing and optimization tasks in wireless networks. Attention mechanisms have recently enabled adaptive measurement aggregation via attention kernel-based formulations. However, the resulting exponential kernels exhibit severe spectral imbalance, inducing large condition numbers that render standard iterative solvers ineffective for regularized attention kernel regression. This paper proposes a Learning-based Attention Kernel Regression (LAKER) algorithm for accelerating regularized attention kernel regression in spectrum cartography. The key idea is to learn a data-dependent preconditioner that captures the inverse spectral structure of the attention kernel system, directly reducing the condition number bottleneck. The preconditioner is obtained by solving a regularized maximum-likelihood estimation problem via a shrinkage-regularized convex--concave procedure, and is integrated with a preconditioned conjugate gradient solver for efficient optimization, whose solution is used for radio map reconstruction. Extensive experiments demonstrate that LAKER significantly reduces condition numbers by up to three orders of magnitude, accelerates convergence by over twenty-fold compared to baselines, and maintains high reconstruction accuracy, establishing learning-based preconditioning as an effective approach for attention kernel regression in spectrum cartography.
Nemobot Games: Crafting Strategic AI Gaming Agents for Interactive Learning with Large Language Models
Apr 23, 2026This paper introduces a new paradigm for AI game programming, leveraging large language models (LLMs) to extend and operationalize Claude Shannon's taxonomy of game-playing machines. Central to this paradigm is Nemobot, an interactive agentic engineering environment that enables users to create, customize, and deploy LLM-powered game agents while actively engaging with AI-driven strategies. The LLM-based chatbot, integrated within Nemobot, demonstrates its capabilities across four distinct classes of games. For dictionary-based games, it compresses state-action mappings into efficient, generalized models for rapid adaptability. In rigorously solvable games, it employs mathematical reasoning to compute optimal strategies and generates human-readable explanations for its decisions. For heuristic-based games, it synthesizes strategies by combining insights from classical minimax algorithms (see, e.g., shannon1950chess) with crowd-sourced data. Finally, in learning-based games, it utilizes reinforcement learning with human feedback and self-critique to iteratively refine strategies through trial-and-error and imitation learning. Nemobot amplifies this framework by offering a programmable environment where users can experiment with tool-augmented generation and fine-tuning of strategic game agents. From strategic games to role-playing games, Nemobot demonstrates how AI agents can achieve a form of self-programming by integrating crowdsourced learning and human creativity to iteratively refine their own logic. This represents a step toward the long-term goal of self-programming AI.
Learning to Optimize by Differentiable Programming
Jan 23, 2026Solving massive-scale optimization problems requires scalable first-order methods with low per-iteration cost. This tutorial highlights a shift in optimization: using differentiable programming not only to execute algorithms but to learn how to design them. Modern frameworks such as PyTorch, TensorFlow, and JAX enable this paradigm through efficient automatic differentiation. Embedding first-order methods within these systems allows end-to-end training that improves convergence and solution quality. Guided by Fenchel-Rockafellar duality, the tutorial demonstrates how duality-informed iterative schemes such as ADMM and PDHG can be learned and adapted. Case studies across LP, OPF, Laplacian regularization, and neural network verification illustrate these gains.
Certifying the Right to Be Forgotten: Primal-Dual Optimization for Sample and Label Unlearning in Vertical Federated Learning
Dec 29, 2025Federated unlearning has become an attractive approach to address privacy concerns in collaborative machine learning, for situations when sensitive data is remembered by AI models during the machine learning process. It enables the removal of specific data influences from trained models, aligning with the growing emphasis on the "right to be forgotten." While extensively studied in horizontal federated learning, unlearning in vertical federated learning (VFL) remains challenging due to the distributed feature architecture. VFL unlearning includes sample unlearning that removes specific data points' influence and label unlearning that removes entire classes. Since different parties hold complementary features of the same samples, unlearning tasks require cross-party coordination, creating computational overhead and complexities from feature interdependencies. To address such challenges, we propose FedORA (Federated Optimization for data Removal via primal-dual Algorithm), designed for sample and label unlearning in VFL. FedORA formulates the removal of certain samples or labels as a constrained optimization problem solved using a primal-dual framework. Our approach introduces a new unlearning loss function that promotes classification uncertainty rather than misclassification. An adaptive step size enhances stability, while an asymmetric batch design, considering the prior influence of the remaining data on the model, handles unlearning and retained data differently to efficiently reduce computational costs. We provide theoretical analysis proving that the model difference between FedORA and Train-from-scratch is bounded, establishing guarantees for unlearning effectiveness. Experiments on tabular and image datasets demonstrate that FedORA achieves unlearning effectiveness and utility preservation comparable to Train-from-scratch with reduced computation and communication overhead.
* Published in the IEEE Transactions on Information Forensics and Security
TrumorGPT: Graph-Based Retrieval-Augmented Large Language Model for Fact-Checking
May 11, 2025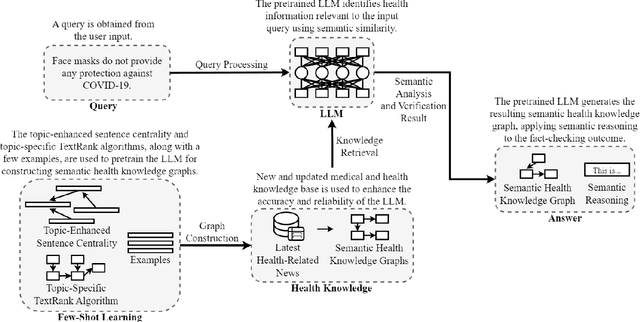



In the age of social media, the rapid spread of misinformation and rumors has led to the emergence of infodemics, where false information poses a significant threat to society. To combat this issue, we introduce TrumorGPT , a novel generative artificial intelligence solution designed for fact-checking in the health domain. TrumorGPT aims to distinguish "trumors", which are health-related rumors that turn out to be true, providing a crucial tool in differentiating between mere speculation and verified facts. This framework leverages a large language model (LLM) with few-shot learning for semantic health knowledge graph construction and semantic reasoning. TrumorGPT incorporates graph-based retrieval-augmented generation (GraphRAG) to address the hallucination issue common in LLMs and the limitations of static training data. GraphRAG involves accessing and utilizing information from regularly updated semantic health knowledge graphs that consist of the latest medical news and health information, ensuring that fact-checking by TrumorGPT is based on the most recent data. Evaluating with extensive healthcare datasets, TrumorGPT demonstrates superior performance in fact-checking for public health claims. Its ability to effectively conduct fact-checking across various platforms marks a critical step forward in the fight against health-related misinformation, enhancing trust and accuracy in the digital information age.
From Code Generation to Software Testing: AI Copilot with Context-Based RAG
Apr 02, 2025The rapid pace of large-scale software development places increasing demands on traditional testing methodologies, often leading to bottlenecks in efficiency, accuracy, and coverage. We propose a novel perspective on software testing by positing bug detection and coding with fewer bugs as two interconnected problems that share a common goal, which is reducing bugs with limited resources. We extend our previous work on AI-assisted programming, which supports code auto-completion and chatbot-powered Q&A, to the realm of software testing. We introduce Copilot for Testing, an automated testing system that synchronizes bug detection with codebase updates, leveraging context-based Retrieval Augmented Generation (RAG) to enhance the capabilities of large language models (LLMs). Our evaluation demonstrates a 31.2% improvement in bug detection accuracy, a 12.6% increase in critical test coverage, and a 10.5% higher user acceptance rate, highlighting the transformative potential of AI-driven technologies in modern software development practices.
Aligning Crowd-sourced Human Feedback for Reinforcement Learning on Code Generation by Large Language Models
Mar 19, 2025This paper studies how AI-assisted programming and large language models (LLM) improve software developers' ability via AI tools (LLM agents) like Github Copilot and Amazon CodeWhisperer, while integrating human feedback to enhance reinforcement learning (RLHF) with crowd-sourced computation to enhance text-to-code generation. Additionally, we demonstrate that our Bayesian optimization framework supports AI alignment in code generation by distributing the feedback collection burden, highlighting the value of collecting human feedback of good quality. Our empirical evaluations demonstrate the efficacy of this approach, showcasing how LLM agents can be effectively trained for improved text-to-code generation. Our Bayesian optimization framework can be designed for general domain-specific languages, promoting the alignment of large language model capabilities with human feedback in AI-assisted programming for code generation.
Online Location Planning for AI-Defined Vehicles: Optimizing Joint Tasks of Order Serving and Spatio-Temporal Heterogeneous Model Fine-Tuning
Feb 06, 2025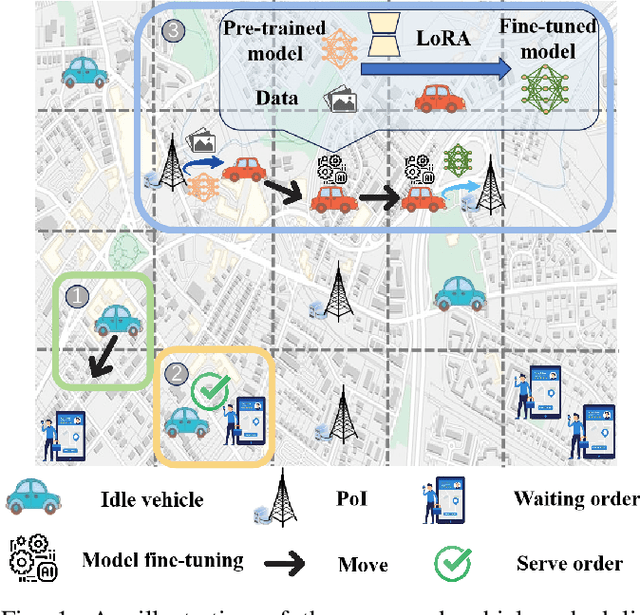



Advances in artificial intelligence (AI) including foundation models (FMs), are increasingly transforming human society, with smart city driving the evolution of urban living.Meanwhile, vehicle crowdsensing (VCS) has emerged as a key enabler, leveraging vehicles' mobility and sensor-equipped capabilities. In particular, ride-hailing vehicles can effectively facilitate flexible data collection and contribute towards urban intelligence, despite resource limitations. Therefore, this work explores a promising scenario, where edge-assisted vehicles perform joint tasks of order serving and the emerging foundation model fine-tuning using various urban data. However, integrating the VCS AI task with the conventional order serving task is challenging, due to their inconsistent spatio-temporal characteristics: (i) The distributions of ride orders and data point-of-interests (PoIs) may not coincide in geography, both following a priori unknown patterns; (ii) they have distinct forms of temporal effects, i.e., prolonged waiting makes orders become instantly invalid while data with increased staleness gradually reduces its utility for model fine-tuning.To overcome these obstacles, we propose an online framework based on multi-agent reinforcement learning (MARL) with careful augmentation. A new quality-of-service (QoS) metric is designed to characterize and balance the utility of the two joint tasks, under the effects of varying data volumes and staleness. We also integrate graph neural networks (GNNs) with MARL to enhance state representations, capturing graph-structured, time-varying dependencies among vehicles and across locations. Extensive experiments on our testbed simulator, utilizing various real-world foundation model fine-tuning tasks and the New York City Taxi ride order dataset, demonstrate the advantage of our proposed method.