 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Taking Tokenizers for Granted: They Are Core Design Decisions in Large Language Models
Jan 19, 2026Tokenization underlies every large language model, yet it remains an under-theorized and inconsistently designed component. Common subword approaches such as Byte Pair Encoding (BPE) offer scalability but often misalign with linguistic structure, amplify bias, and waste capacity across languages and domains. This paper reframes tokenization as a core modeling decision rather than a preprocessing step. We argue for a context-aware framework that integrates tokenizer and model co-design, guided by linguistic, domain, and deployment considerations. Standardized evaluation and transparent reporting are essential to make tokenization choices accountable and comparable. Treating tokenization as a core design problem, not a technical afterthought, can yield language technologies that are fairer, more efficient, and more adaptable.
A Systematic Survey and Critical Review on Evaluating Large Language Models: Challenges, Limitations, and Recommendations
Jul 04, 2024



Large Language Models (LLMs) have recently gained significant attention due to their remarkable capabilities in performing diverse tasks across various domains. However, a thorough evaluation of these models is crucial before deploying them in real-world applications to ensure they produce reliable performance. Despite the well-established importance of evaluating LLMs in the community, the complexity of the evaluation process has led to varied evaluation setups, causing inconsistencies in findings and interpretations. To address this, we systematically review the primary challenges and limitations causing these inconsistencies and unreliable evaluations in various steps of LLM evaluation. Based on our critical review, we present our perspectives and recommendations to ensure LLM evaluations are reproducible, reliable, and robust.
Automatic Restoration of Diacritics for Speech Data Sets
Nov 15, 2023Automatic text-based diacritic restoration models generally have high diacritic error rates when applied to speech transcripts as a result of domain and style shifts in spoken language. In this work, we explore the possibility of improving the performance of automatic diacritic restoration when applied to speech data by utilizing the parallel spoken utterances. In particular, we use the pre-trained Whisper ASR model fine-tuned on relatively small amounts of diacritized Arabic speech data to produce rough diacritized transcripts for the speech utterances, which we then use as an additional input for a transformer-based diacritic restoration model. The proposed model consistently improve diacritic restoration performance compared to an equivalent text-only model, with at least 5\% absolute reduction in diacritic error rate within the same domain and on two out-of-domain test sets. Our results underscore the inadequacy of current text-based diacritic restoration models for speech data sets and provide a new baseline for speech-based diacritic restoration.
Injecting Domain Knowledge in Language Models for Task-Oriented Dialogue Systems
Dec 15, 2022



Pre-trained language models (PLM) have advanced the state-of-the-art across NLP applications, but lack domain-specific knowledge that does not naturally occur in pre-training data. Previous studies augmented PLMs with symbolic knowledge for different downstream NLP tasks. However, knowledge bases (KBs) utilized in these studies are usually large-scale and static, in contrast to small, domain-specific, and modifiable knowledge bases that are prominent in real-world task-oriented dialogue (TOD) systems. In this paper, we showcase the advantages of injecting domain-specific knowledge prior to fine-tuning on TOD tasks. To this end, we utilize light-weight adapters that can be easily integrated with PLMs and serve as a repository for facts learned from different KBs. To measure the efficacy of proposed knowledge injection methods, we introduce Knowledge Probing using Response Selection (KPRS) -- a probe designed specifically for TOD models. Experiments on KPRS and the response generation task show improvements of knowledge injection with adapters over strong baselines.
Using Optimal Transport as Alignment Objective for fine-tuning Multilingual Contextualized Embeddings
Oct 06, 2021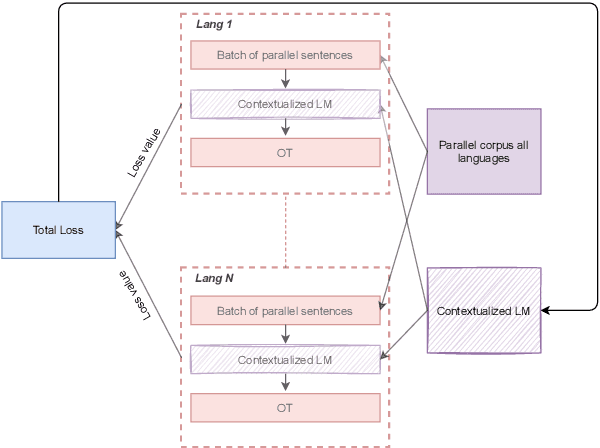
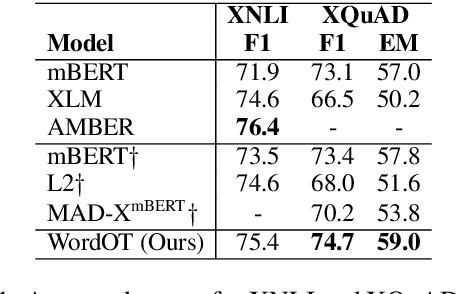

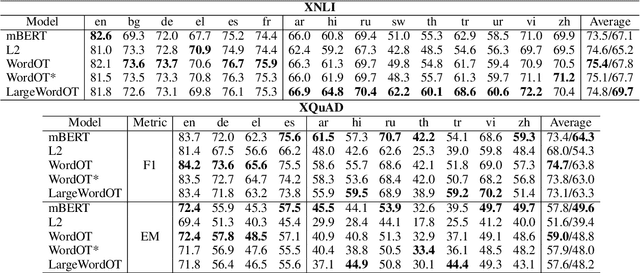
Recent studies have proposed different methods to improve multilingual word representations in contextualized settings including techniques that align between source and target embedding spaces. For contextualized embeddings, alignment becomes more complex as we additionally take context into consideration. In this work, we propose using Optimal Transport (OT) as an alignment objective during fine-tuning to further improve multilingual contextualized representations for downstream cross-lingual transfer. This approach does not require word-alignment pairs prior to fine-tuning that may lead to sub-optimal matching and instead learns the word alignments within context in an unsupervised manner. It also allows different types of mappings due to soft matching between source and target sentences. We benchmark our proposed method on two tasks (XNLI and XQuAD) and achieve improvements over baselines as well as competitive results compared to similar recent works.
A Multitask Learning Approach for Diacritic Restoration
Jun 07, 2020
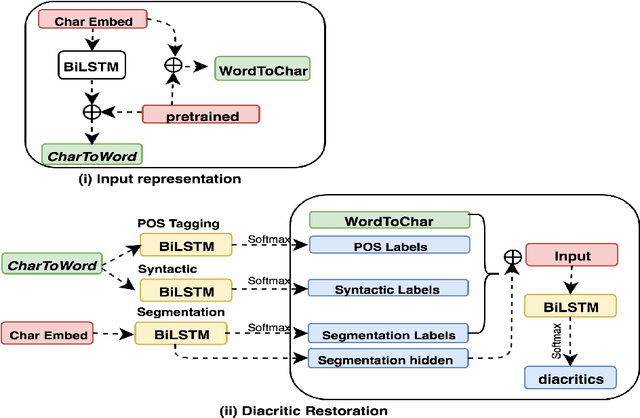
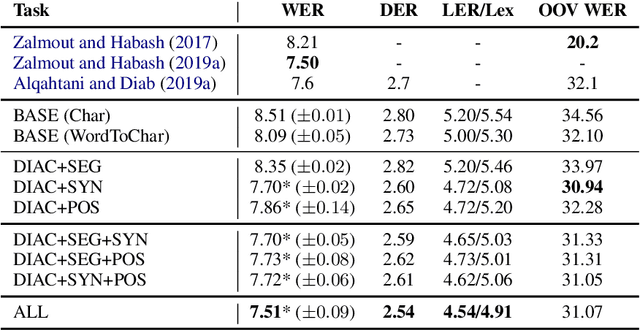
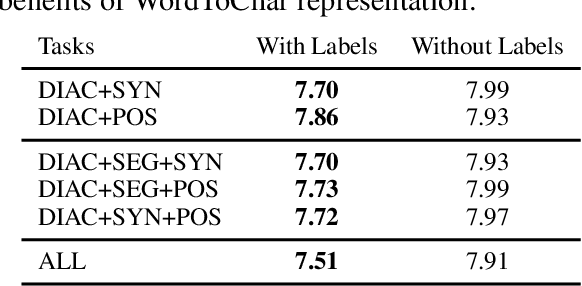
In many languages like Arabic, diacritics are used to specify pronunciations as well as meanings. Such diacritics are often omitted in written text, increasing the number of possible pronunciations and meanings for a word. This results in a more ambiguous text making computational processing on such text more difficult. Diacritic restoration is the task of restoring missing diacritics in the written text. Most state-of-the-art diacritic restoration models are built on character level information which helps generalize the model to unseen data, but presumably lose useful information at the word level. Thus, to compensate for this loss, we investigate the use of multi-task learning to jointly optimize diacritic restoration with related NLP problems namely word segmentation, part-of-speech tagging, and syntactic diacritization. We use Arabic as a case study since it has sufficient data resources for tasks that we consider in our joint modeling. Our joint models significantly outperform the baselines and are comparable to the state-of-the-art models that are more complex relying on morphological analyzers and/or a lot more data (e.g. dialectal data).
Efficient Convolutional Neural Networks for Diacritic Restoration
Dec 14, 2019
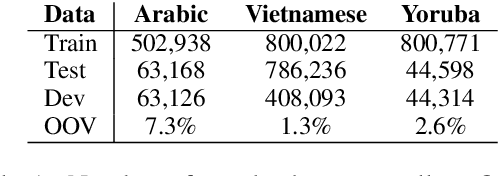
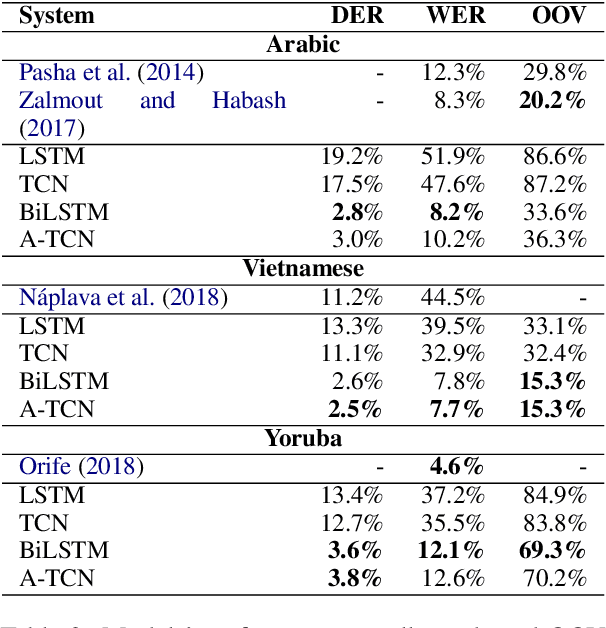
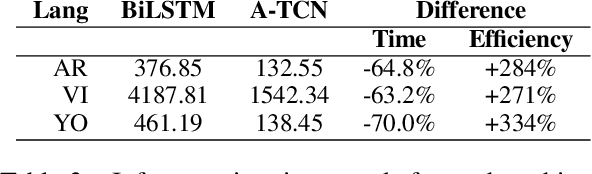
Diacritic restoration has gained importance with the growing need for machines to understand written texts. The task is typically modeled as a sequence labeling problem and currently Bidirectional Long Short Term Memory (BiLSTM) models provide state-of-the-art results. Recently, Bai et al. (2018) show the advantages of Temporal Convolutional Neural Networks (TCN) over Recurrent Neural Networks (RNN) for sequence modeling in terms of performance and computational resources. As diacritic restoration benefits from both previous as well as subsequent timesteps, we further apply and evaluate a variant of TCN, Acausal TCN (A-TCN), which incorporates context from both directions (previous and future) rather than strictly incorporating previous context as in the case of TCN. A-TCN yields significant improvement over TCN for diacritization in three different languages: Arabic, Yoruba, and Vietnamese. Furthermore, A-TCN and BiLSTM have comparable performance, making A-TCN an efficient alternative over BiLSTM since convolutions can be trained in parallel. A-TCN is significantly faster than BiLSTM at inference time (270%-334% improvement in the amount of text diacritized per minute).
* accepted in EMNLP 2019
Homograph Disambiguation Through Selective Diacritic Restoration
Dec 10, 2019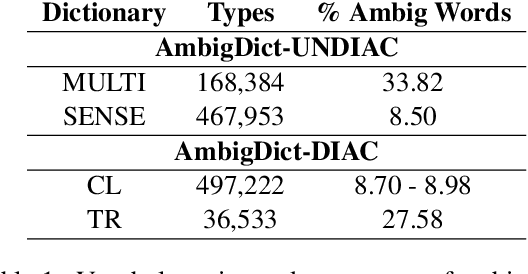


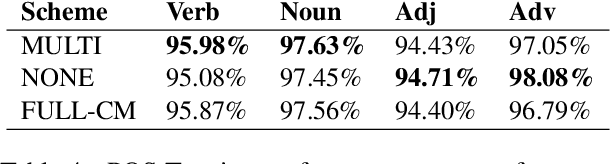
Lexical ambiguity, a challenging phenomenon in all natural languages, is particularly prevalent for languages with diacritics that tend to be omitted in writing, such as Arabic. Omitting diacritics leads to an increase in the number of homographs: different words with the same spelling. Diacritic restoration could theoretically help disambiguate these words, but in practice, the increase in overall sparsity leads to performance degradation in NLP applications. In this paper, we propose approaches for automatically marking a subset of words for diacritic restoration, which leads to selective homograph disambiguation. Compared to full or no diacritic restoration, these approaches yield selectively-diacritized datasets that balance sparsity and lexical disambiguation. We evaluate the various selection strategies extrinsically on several downstream applications: neural machine translation, part-of-speech tagging, and semantic textual similarity. Our experiments on Arabic show promising results, where our devised strategies on selective diacritization lead to a more balanced and consistent performance in downstream applications.