 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupplement Generation Training for Enhancing Agentic Task Performance
Apr 22, 2026Training large foundation models for agentic tasks is increasingly impractical due to the high computational costs, long iteration cycles, and rapid obsolescence as new models are continuously released. Instead of post-training massive models for every new task or domain, we propose Supplement Generation Training (SGT), a more efficient and sustainable strategy. SGT trains a smaller LLM to generate useful supplemental text that, when appended to the original input, helps the larger LLM solve the task more effectively. These lightweight models can dynamically adapt supplements to task requirements, improving performance without modifying the underlying large models. This approach decouples task-specific optimization from large foundation models and enables more flexible, cost-effective deployment of LLM-powered agents in real-world applications.
TReMu: Towards Neuro-Symbolic Temporal Reasoning for LLM-Agents with Memory in Multi-Session Dialogues
Feb 03, 2025

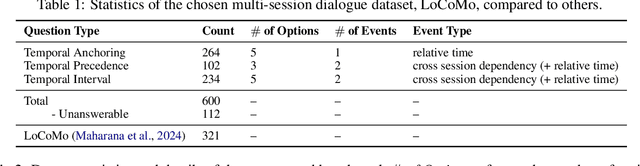
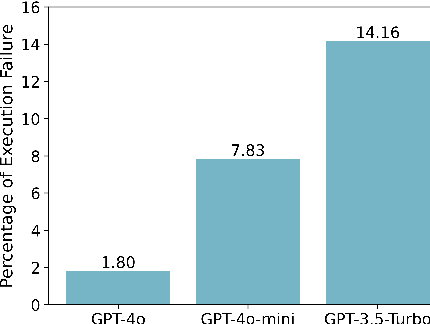
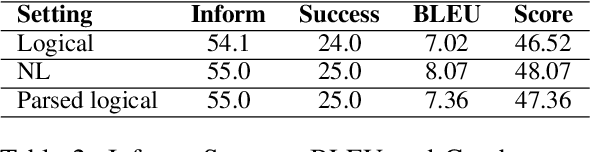
Temporal reasoning in multi-session dialogues presents a significant challenge which has been under-studied in previous temporal reasoning benchmarks. To bridge this gap, we propose a new evaluation task for temporal reasoning in multi-session dialogues and introduce an approach to construct a new benchmark by augmenting dialogues from LoCoMo and creating multi-choice QAs. Furthermore, we present TReMu, a new framework aimed at enhancing the temporal reasoning capabilities of LLM-agents in this context. Specifically, the framework employs \textit{time-aware memorization} through timeline summarization, generating retrievable memory by summarizing events in each dialogue session with their inferred dates. Additionally, we integrate \textit{neuro-symbolic temporal reasoning}, where LLMs generate Python code to perform temporal calculations and select answers. Experimental evaluations on popular LLMs demonstrate that our benchmark is challenging, and the proposed framework significantly improves temporal reasoning performance compared to baseline methods, raising from 29.83 on GPT-4o via standard prompting to 77.67 via our approach and highlighting its effectiveness in addressing temporal reasoning in multi-session dialogues.
User Simulation with Large Language Models for Evaluating Task-Oriented Dialogue
Sep 23, 2023
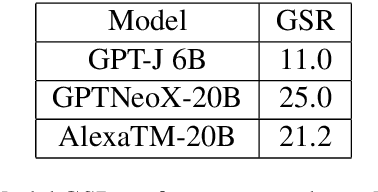
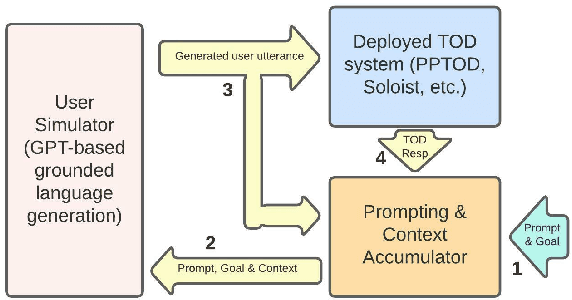
One of the major impediments to the development of new task-oriented dialogue (TOD) systems is the need for human evaluation at multiple stages and iterations of the development process. In an effort to move toward automated evaluation of TOD, we propose a novel user simulator built using recently developed large pretrained language models (LLMs). In order to increase the linguistic diversity of our system relative to the related previous work, we do not fine-tune the LLMs used by our system on existing TOD datasets; rather we use in-context learning to prompt the LLMs to generate robust and linguistically diverse output with the goal of simulating the behavior of human interlocutors. Unlike previous work, which sought to maximize goal success rate (GSR) as the primary metric of simulator performance, our goal is a system which achieves a GSR similar to that observed in human interactions with TOD systems. Using this approach, our current simulator is effectively able to interact with several TOD systems, especially on single-intent conversational goals, while generating lexically and syntactically diverse output relative to previous simulators that rely upon fine-tuned models. Finally, we collect a Human2Bot dataset of humans interacting with the same TOD systems with which we experimented in order to better quantify these achievements.
Pre-training Intent-Aware Encoders for Zero- and Few-Shot Intent Classification
May 24, 2023Intent classification (IC) plays an important role in task-oriented dialogue systems as it identifies user intents from given utterances. However, models trained on limited annotations for IC often suffer from a lack of generalization to unseen intent classes. We propose a novel pre-training method for text encoders that uses contrastive learning with intent psuedo-labels to produce embeddings that are well-suited for IC tasks. By applying this pre-training strategy, we also introduce the pre-trained intent-aware encoder (PIE). Specifically, we first train a tagger to identify key phrases within utterances that are crucial for interpreting intents. We then use these extracted phrases to create examples for pre-training a text encoder in a contrastive manner. As a result, our PIE model achieves up to 5.4% and 4.0% higher accuracy than the previous state-of-the-art pre-trained sentence encoder for the N-way zero- and one-shot settings on four IC datasets.
Intent Induction from Conversations for Task-Oriented Dialogue Track at DSTC 11
Apr 25, 2023With increasing demand for and adoption of virtual assistants, recent work has investigated ways to accelerate bot schema design through the automatic induction of intents or the induction of slots and dialogue states. However, a lack of dedicated benchmarks and standardized evaluation has made progress difficult to track and comparisons between systems difficult to make. This challenge track, held as part of the Eleventh Dialog Systems Technology Challenge, introduces a benchmark that aims to evaluate methods for the automatic induction of customer intents in a realistic setting of customer service interactions between human agents and customers. We propose two subtasks for progressively tackling the automatic induction of intents and corresponding evaluation methodologies. We then present three datasets suitable for evaluating the tasks and propose simple baselines. Finally, we summarize the submissions and results of the challenge track, for which we received submissions from 34 teams.
Dialog2API: Task-Oriented Dialogue with API Description and Example Programs
Dec 20, 2022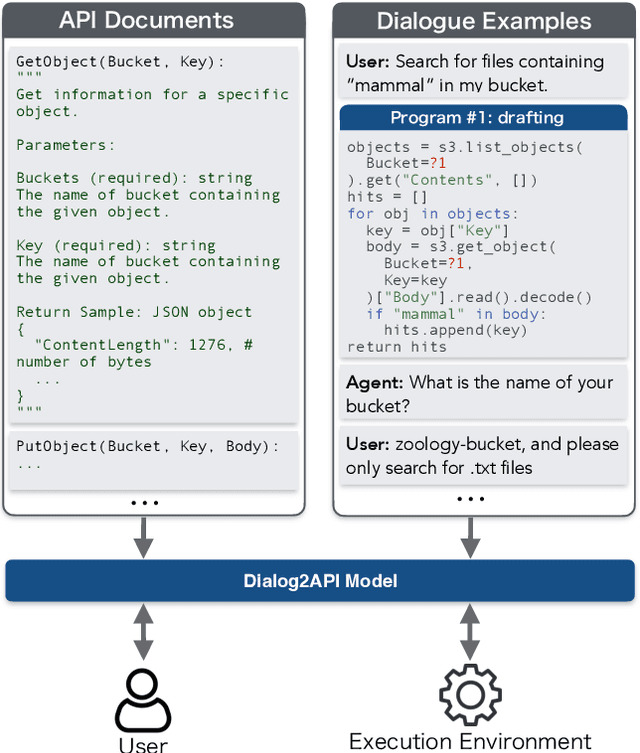



Functionality and dialogue experience are two important factors of task-oriented dialogue systems. Conventional approaches with closed schema (e.g., conversational semantic parsing) often fail as both the functionality and dialogue experience are strongly constrained by the underlying schema. We introduce a new paradigm for task-oriented dialogue - Dialog2API - to greatly expand the functionality and provide seamless dialogue experience. The conversational model interacts with the environment by generating and executing programs triggering a set of pre-defined APIs. The model also manages the dialogue policy and interact with the user through generating appropriate natural language responses. By allowing generating free-form programs, Dialog2API supports composite goals by combining different APIs, whereas unrestricted program revision provides natural and robust dialogue experience. To facilitate Dialog2API, the core model is provided with API documents, an execution environment and optionally some example dialogues annotated with programs. We propose an approach tailored for the Dialog2API, where the dialogue states are represented by a stack of programs, with most recently mentioned program on the top of the stack. Dialog2API can work with many application scenarios such as software automation and customer service. In this paper, we construct a dataset for AWS S3 APIs and present evaluation results of in-context learning baselines.
Label Semantic Aware Pre-training for Few-shot Text Classification
Apr 14, 2022
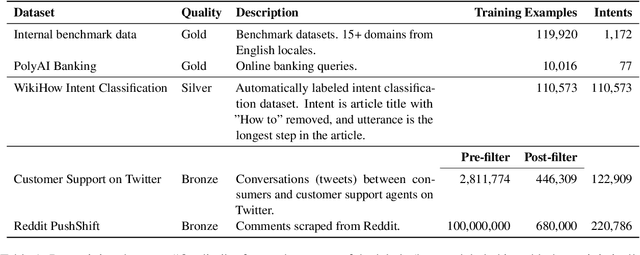
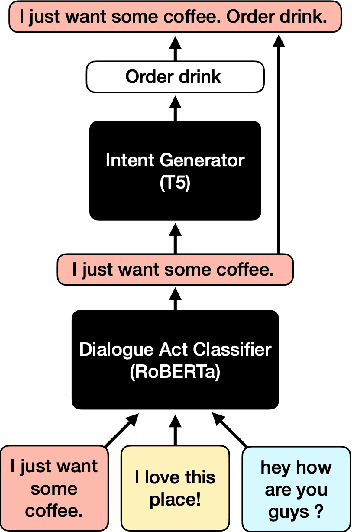
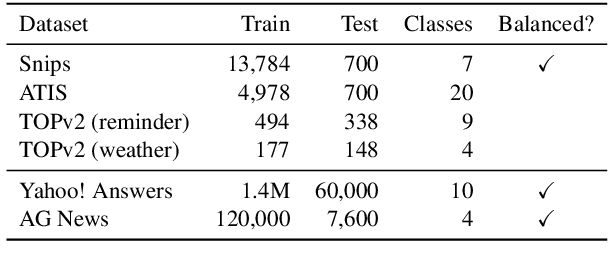
In text classification tasks, useful information is encoded in the label names. Label semantic aware systems have leveraged this information for improved text classification performance during fine-tuning and prediction. However, use of label-semantics during pre-training has not been extensively explored. We therefore propose Label Semantic Aware Pre-training (LSAP) to improve the generalization and data efficiency of text classification systems. LSAP incorporates label semantics into pre-trained generative models (T5 in our case) by performing secondary pre-training on labeled sentences from a variety of domains. As domain-general pre-training requires large amounts of data, we develop a filtering and labeling pipeline to automatically create sentence-label pairs from unlabeled text. We perform experiments on intent (ATIS, Snips, TOPv2) and topic classification (AG News, Yahoo! Answers). LSAP obtains significant accuracy improvements over state-of-the-art models for few-shot text classification while maintaining performance comparable to state of the art in high-resource settings.
Using Optimal Transport as Alignment Objective for fine-tuning Multilingual Contextualized Embeddings
Oct 06, 2021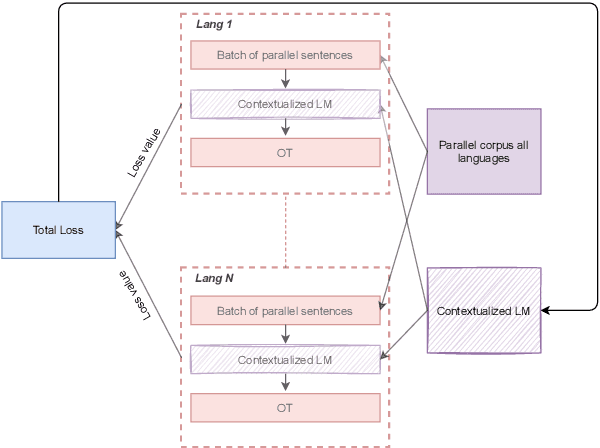
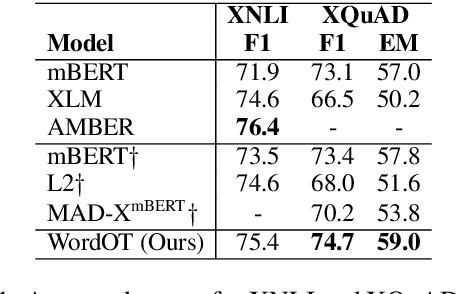

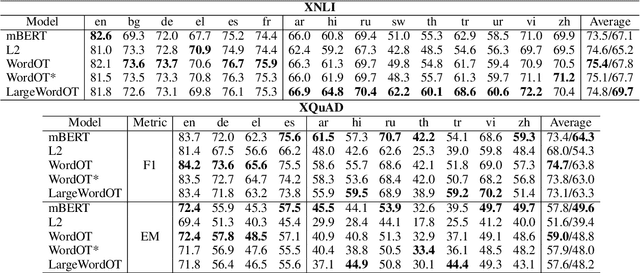
Recent studies have proposed different methods to improve multilingual word representations in contextualized settings including techniques that align between source and target embedding spaces. For contextualized embeddings, alignment becomes more complex as we additionally take context into consideration. In this work, we propose using Optimal Transport (OT) as an alignment objective during fine-tuning to further improve multilingual contextualized representations for downstream cross-lingual transfer. This approach does not require word-alignment pairs prior to fine-tuning that may lead to sub-optimal matching and instead learns the word alignments within context in an unsupervised manner. It also allows different types of mappings due to soft matching between source and target sentences. We benchmark our proposed method on two tasks (XNLI and XQuAD) and achieve improvements over baselines as well as competitive results compared to similar recent works.
Tanbih: Get To Know What You Are Reading
Oct 04, 2019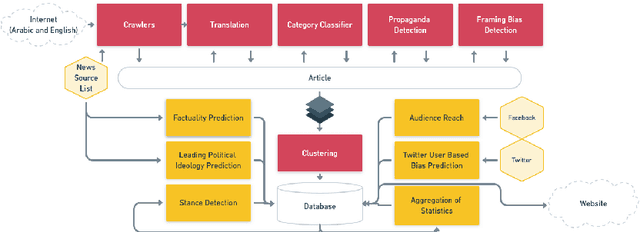
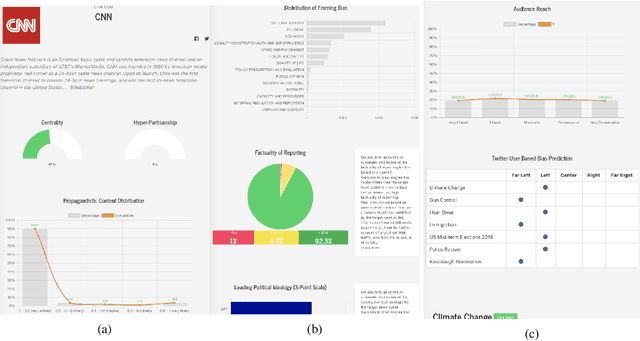
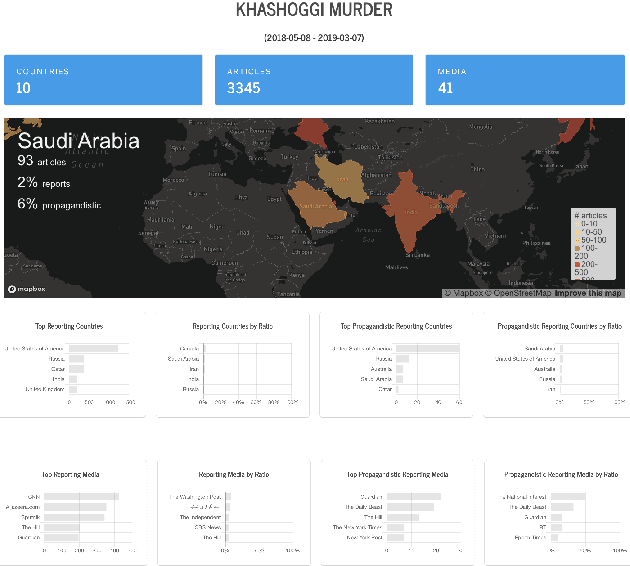
We introduce Tanbih, a news aggregator with intelligent analysis tools to help readers understanding what's behind a news story. Our system displays news grouped into events and generates media profiles that show the general factuality of reporting, the degree of propagandistic content, hyper-partisanship, leading political ideology, general frame of reporting, and stance with respect to various claims and topics of a news outlet. In addition, we automatically analyse each article to detect whether it is propagandistic and to determine its stance with respect to a number of controversial topics.
Adversarial Domain Adaptation for Duplicate Question Detection
Sep 07, 2018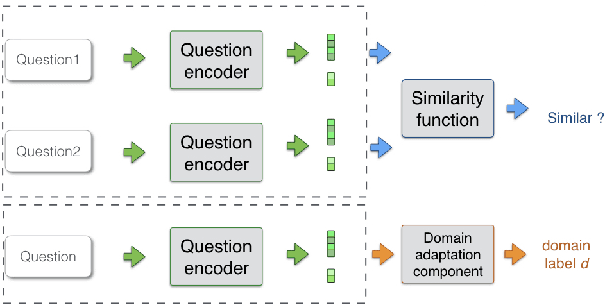


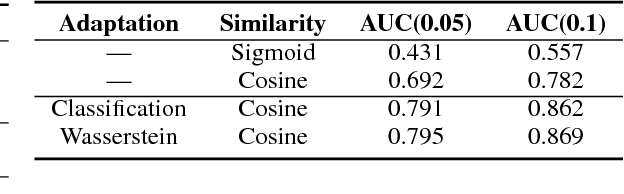
We address the problem of detecting duplicate questions in forums, which is an important step towards automating the process of answering new questions. As finding and annotating such potential duplicates manually is very tedious and costly, automatic methods based on machine learning are a viable alternative. However, many forums do not have annotated data, i.e., questions labeled by experts as duplicates, and thus a promising solution is to use domain adaptation from another forum that has such annotations. Here we focus on adversarial domain adaptation, deriving important findings about when it performs well and what properties of the domains are important in this regard. Our experiments with StackExchange data show an average improvement of 5.6% over the best baseline across multiple pairs of domains.