 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsTALL: Context-aware Instructional Task Assistance with Multi-modal Large Language Models
Jan 21, 2025



The improved competence of generative models can help building multi-modal virtual assistants that leverage modalities beyond language. By observing humans performing multi-step tasks, one can build assistants that have situational awareness of actions and tasks being performed, enabling them to cater assistance based on this understanding. In this paper, we develop a Context-aware Instructional Task Assistant with Multi-modal Large Language Models (InsTALL) that leverages an online visual stream (e.g. a user's screen share or video recording) and responds in real-time to user queries related to the task at hand. To enable useful assistance, InsTALL 1) trains a multi-modal model on task videos and paired textual data, and 2) automatically extracts task graph from video data and leverages it at training and inference time. We show InsTALL achieves state-of-the-art performance across proposed sub-tasks considered for multimodal activity understanding -- task recognition (TR), action recognition (AR), next action prediction (AP), and plan prediction (PP) -- and outperforms existing baselines on two novel sub-tasks related to automatic error identification.
FLAP: Flow Adhering Planning with Constrained Decoding in LLMs
Mar 09, 2024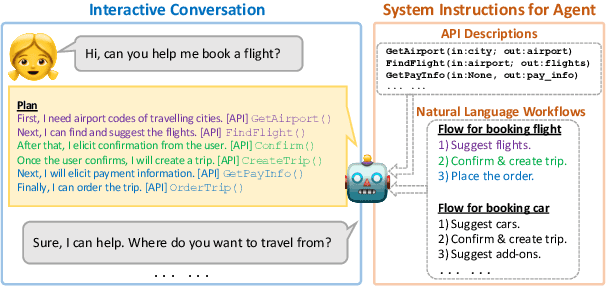
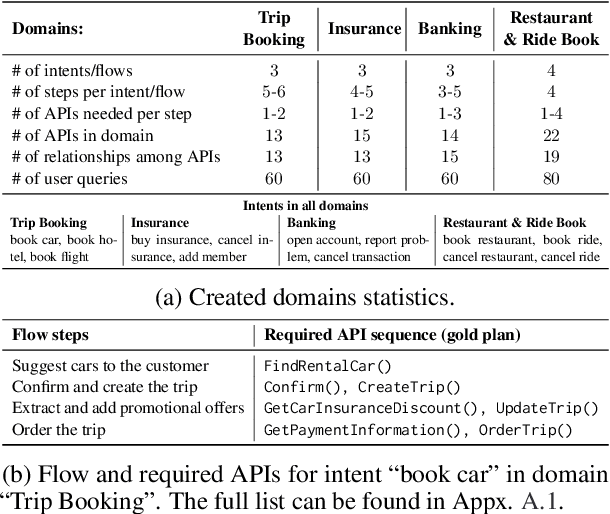
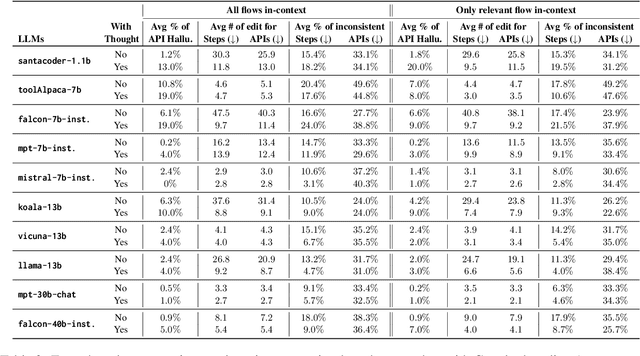
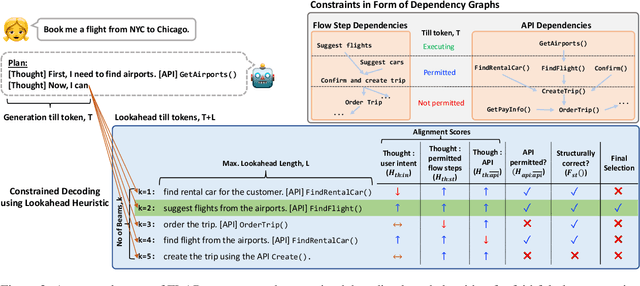
Planning is a crucial task for agents in task oriented dialogs (TODs). Human agents typically resolve user issues by following predefined workflows, decomposing workflow steps into actionable items, and performing actions by executing APIs in order; all of which require reasoning and planning. With the recent advances in LLMs, there have been increasing attempts to use LLMs for task planning and API usage. However, the faithfulness of the plans to predefined workflows and API dependencies, is not guaranteed with LLMs because of their bias towards pretraining data. Moreover, in real life, workflows are custom-defined and prone to change, hence, quickly adapting agents to the changes is desirable. In this paper, we study faithful planning in TODs to resolve user intents by following predefined flows and preserving API dependencies. We propose a constrained decoding algorithm based on lookahead heuristic for faithful planning. Our algorithm alleviates the need for finetuning LLMs using domain specific data, outperforms other decoding and prompting-based baselines, and applying our algorithm on smaller LLMs (7B) we achieve comparable performance to larger LLMs (30B-40B).
MAGID: An Automated Pipeline for Generating Synthetic Multi-modal Datasets
Mar 05, 2024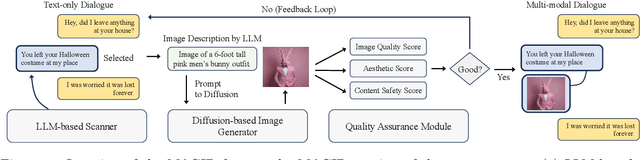



Development of multimodal interactive systems is hindered by the lack of rich, multimodal (text, images) conversational data, which is needed in large quantities for LLMs. Previous approaches augment textual dialogues with retrieved images, posing privacy, diversity, and quality constraints. In this work, we introduce \textbf{M}ultimodal \textbf{A}ugmented \textbf{G}enerative \textbf{I}mages \textbf{D}ialogues (MAGID), a framework to augment text-only dialogues with diverse and high-quality images. Subsequently, a diffusion model is applied to craft corresponding images, ensuring alignment with the identified text. Finally, MAGID incorporates an innovative feedback loop between an image description generation module (textual LLM) and image quality modules (addressing aesthetics, image-text matching, and safety), that work in tandem to generate high-quality and multi-modal dialogues. We compare MAGID to other SOTA baselines on three dialogue datasets, using automated and human evaluation. Our results show that MAGID is comparable to or better than baselines, with significant improvements in human evaluation, especially against retrieval baselines where the image database is small.
DeAL: Decoding-time Alignment for Large Language Models
Feb 05, 2024



Large Language Models (LLMs) are nowadays expected to generate content aligned with human preferences. Current work focuses on alignment at model training time, through techniques such as Reinforcement Learning with Human Feedback (RLHF). However, it is unclear if such methods are an effective choice to teach alignment objectives to the model. First, the inability to incorporate multiple, custom rewards and reliance on a model developer's view of universal and static principles are key limitations. Second, the residual gaps in model training and the reliability of such approaches are also questionable (e.g. susceptibility to jail-breaking even after safety training). To address these, we propose DeAL, a framework that allows the user to customize reward functions and enables Decoding-time Alignment of LLMs (DeAL). At its core, we view decoding as a heuristic-guided search process and facilitate the use of a wide variety of alignment objectives. Our experiments with programmatic constraints such as keyword and length constraints (studied widely in the pre-LLM era) and abstract objectives such as harmlessness and helpfulness (proposed in the post-LLM era) show that we can DeAL with fine-grained trade-offs, improve adherence to alignment objectives, and address residual gaps in LLMs. Lastly, while DeAL can be effectively paired with RLHF and prompting techniques, its generality makes decoding slower, an optimization we leave for future work.
User Simulation with Large Language Models for Evaluating Task-Oriented Dialogue
Sep 23, 2023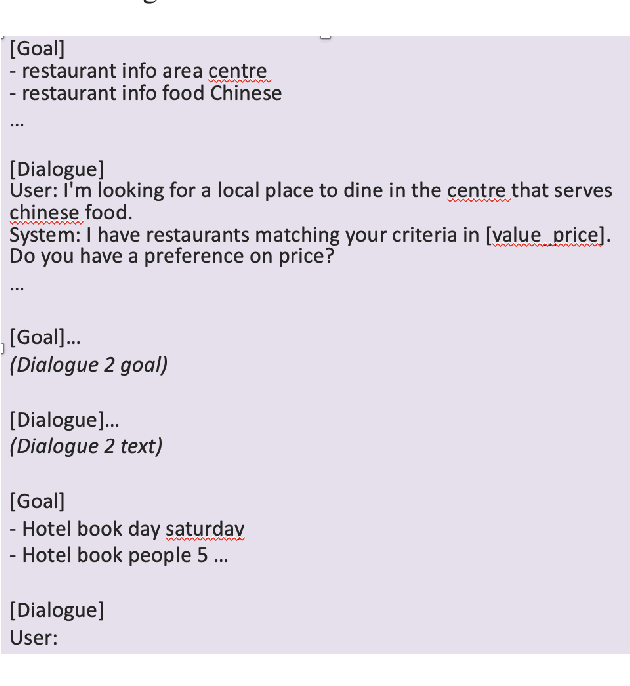
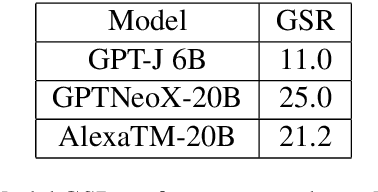
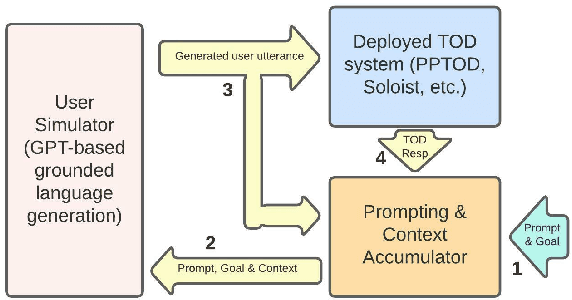
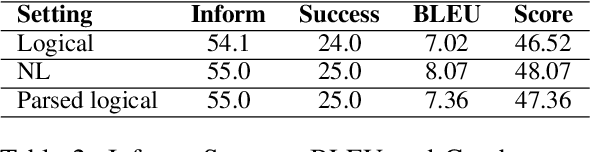
One of the major impediments to the development of new task-oriented dialogue (TOD) systems is the need for human evaluation at multiple stages and iterations of the development process. In an effort to move toward automated evaluation of TOD, we propose a novel user simulator built using recently developed large pretrained language models (LLMs). In order to increase the linguistic diversity of our system relative to the related previous work, we do not fine-tune the LLMs used by our system on existing TOD datasets; rather we use in-context learning to prompt the LLMs to generate robust and linguistically diverse output with the goal of simulating the behavior of human interlocutors. Unlike previous work, which sought to maximize goal success rate (GSR) as the primary metric of simulator performance, our goal is a system which achieves a GSR similar to that observed in human interactions with TOD systems. Using this approach, our current simulator is effectively able to interact with several TOD systems, especially on single-intent conversational goals, while generating lexically and syntactically diverse output relative to previous simulators that rely upon fine-tuned models. Finally, we collect a Human2Bot dataset of humans interacting with the same TOD systems with which we experimented in order to better quantify these achievements.
NatCS: Eliciting Natural Customer Support Dialogues
May 04, 2023



Despite growing interest in applications based on natural customer support conversations, there exist remarkably few publicly available datasets that reflect the expected characteristics of conversations in these settings. Existing task-oriented dialogue datasets, which were collected to benchmark dialogue systems mainly in written human-to-bot settings, are not representative of real customer support conversations and do not provide realistic benchmarks for systems that are applied to natural data. To address this gap, we introduce NatCS, a multi-domain collection of spoken customer service conversations. We describe our process for collecting synthetic conversations between customers and agents based on natural language phenomena observed in real conversations. Compared to previous dialogue datasets, the conversations collected with our approach are more representative of real human-to-human conversations along multiple metrics. Finally, we demonstrate potential uses of NatCS, including dialogue act classification and intent induction from conversations as potential applications, showing that dialogue act annotations in NatCS provide more effective training data for modeling real conversations compared to existing synthetic written datasets. We publicly release NatCS to facilitate research in natural dialog systems
Intent Induction from Conversations for Task-Oriented Dialogue Track at DSTC 11
Apr 25, 2023With increasing demand for and adoption of virtual assistants, recent work has investigated ways to accelerate bot schema design through the automatic induction of intents or the induction of slots and dialogue states. However, a lack of dedicated benchmarks and standardized evaluation has made progress difficult to track and comparisons between systems difficult to make. This challenge track, held as part of the Eleventh Dialog Systems Technology Challenge, introduces a benchmark that aims to evaluate methods for the automatic induction of customer intents in a realistic setting of customer service interactions between human agents and customers. We propose two subtasks for progressively tackling the automatic induction of intents and corresponding evaluation methodologies. We then present three datasets suitable for evaluating the tasks and propose simple baselines. Finally, we summarize the submissions and results of the challenge track, for which we received submissions from 34 teams.
Dialog2API: Task-Oriented Dialogue with API Description and Example Programs
Dec 20, 2022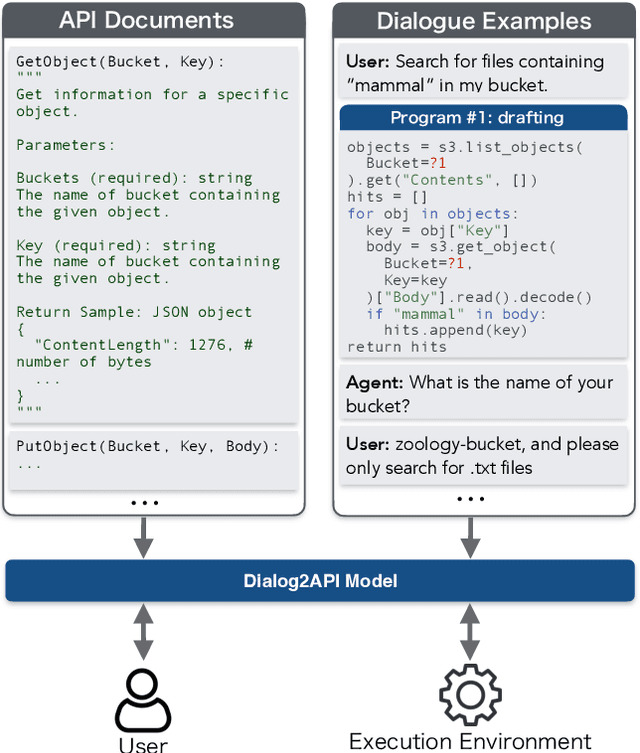



Functionality and dialogue experience are two important factors of task-oriented dialogue systems. Conventional approaches with closed schema (e.g., conversational semantic parsing) often fail as both the functionality and dialogue experience are strongly constrained by the underlying schema. We introduce a new paradigm for task-oriented dialogue - Dialog2API - to greatly expand the functionality and provide seamless dialogue experience. The conversational model interacts with the environment by generating and executing programs triggering a set of pre-defined APIs. The model also manages the dialogue policy and interact with the user through generating appropriate natural language responses. By allowing generating free-form programs, Dialog2API supports composite goals by combining different APIs, whereas unrestricted program revision provides natural and robust dialogue experience. To facilitate Dialog2API, the core model is provided with API documents, an execution environment and optionally some example dialogues annotated with programs. We propose an approach tailored for the Dialog2API, where the dialogue states are represented by a stack of programs, with most recently mentioned program on the top of the stack. Dialog2API can work with many application scenarios such as software automation and customer service. In this paper, we construct a dataset for AWS S3 APIs and present evaluation results of in-context learning baselines.
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Sep 29, 2021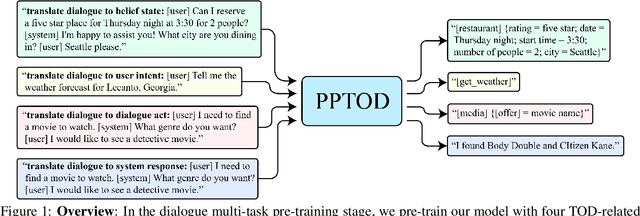
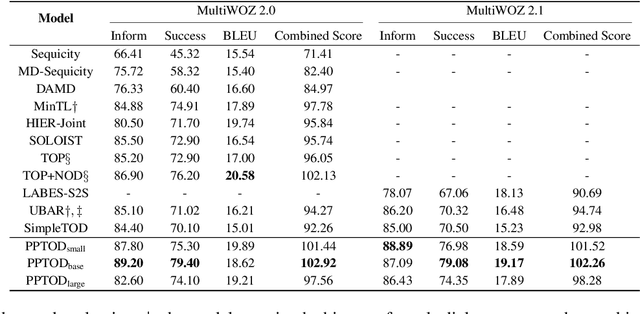
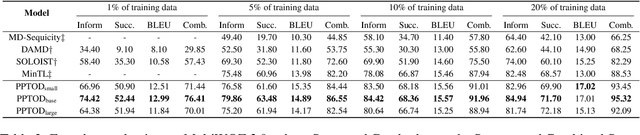
Pre-trained language models have been recently shown to benefit task-oriented dialogue (TOD) systems. Despite their success, existing methods often formulate this task as a cascaded generation problem which can lead to error accumulation across different sub-tasks and greater data annotation overhead. In this study, we present PPTOD, a unified plug-and-play model for task-oriented dialogue. In addition, we introduce a new dialogue multi-task pre-training strategy that allows the model to learn the primary TOD task completion skills from heterogeneous dialog corpora. We extensively test our model on three benchmark TOD tasks, including end-to-end dialogue modelling, dialogue state tracking, and intent classification. Experimental results show that PPTOD achieves new state of the art on all evaluated tasks in both high-resource and low-resource scenarios. Furthermore, comparisons against previous SOTA methods show that the responses generated by PPTOD are more factually correct and semantically coherent as judged by human annotators.
Goal-Embedded Dual Hierarchical Model for Task-Oriented Dialogue Generation
Sep 19, 2019

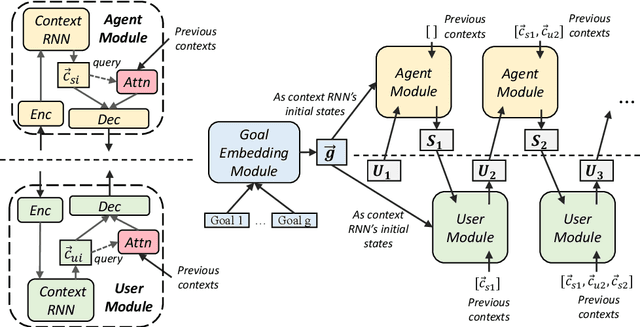
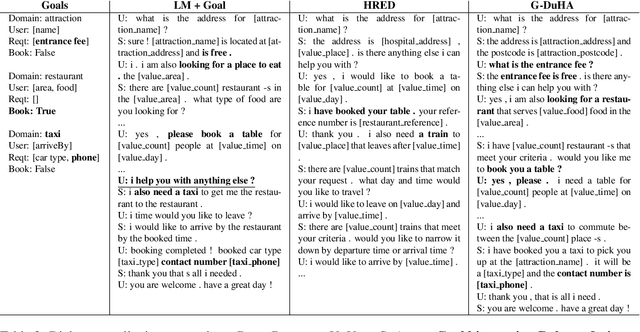
Hierarchical neural networks are often used to model inherent structures within dialogues. For goal-oriented dialogues, these models miss a mechanism adhering to the goals and neglect the distinct conversational patterns between two interlocutors. In this work, we propose Goal-Embedded Dual Hierarchical Attentional Encoder-Decoder (G-DuHA) able to center around goals and capture interlocutor-level disparity while modeling goal-oriented dialogues. Experiments on dialogue generation, response generation, and human evaluations demonstrate that the proposed model successfully generates higher-quality, more diverse and goal-centric dialogues. Moreover, we apply data augmentation via goal-oriented dialogue generation for task-oriented dialog systems with better performance achieved.