 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaScale: Test-Time Scaling with Evolving Meta-Thoughts
Mar 17, 2025One critical challenge for large language models (LLMs) for making complex reasoning is their reliance on matching reasoning patterns from training data, instead of proactively selecting the most appropriate cognitive strategy to solve a given task. Existing approaches impose fixed cognitive structures that enhance performance in specific tasks but lack adaptability across diverse scenarios. To address this limitation, we introduce METASCALE, a test-time scaling framework based on meta-thoughts -- adaptive thinking strategies tailored to each task. METASCALE initializes a pool of candidate meta-thoughts, then iteratively selects and evaluates them using a multi-armed bandit algorithm with upper confidence bound selection, guided by a reward model. To further enhance adaptability, a genetic algorithm evolves high-reward meta-thoughts, refining and extending the strategy pool over time. By dynamically proposing and optimizing meta-thoughts at inference time, METASCALE improves both accuracy and generalization across a wide range of tasks. Experimental results demonstrate that MetaScale consistently outperforms standard inference approaches, achieving an 11% performance gain in win rate on Arena-Hard for GPT-4o, surpassing o1-mini by 0.9% under style control. Notably, METASCALE scales more effectively with increasing sampling budgets and produces more structured, expert-level responses.
mDPO: Conditional Preference Optimization for Multimodal Large Language Models
Jun 17, 2024



Direct preference optimization (DPO) has shown to be an effective method for large language model (LLM) alignment. Recent works have attempted to apply DPO to multimodal scenarios but have found it challenging to achieve consistent improvement. Through a comparative experiment, we identify the unconditional preference problem in multimodal preference optimization, where the model overlooks the image condition. To address this problem, we propose mDPO, a multimodal DPO objective that prevents the over-prioritization of language-only preferences by also optimizing image preference. Moreover, we introduce a reward anchor that forces the reward to be positive for chosen responses, thereby avoiding the decrease in their likelihood -- an intrinsic problem of relative preference optimization. Experiments on two multimodal LLMs of different sizes and three widely used benchmarks demonstrate that mDPO effectively addresses the unconditional preference problem in multimodal preference optimization and significantly improves model performance, particularly in reducing hallucination.
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Jun 13, 2024



We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
Offset Unlearning for Large Language Models
Apr 17, 2024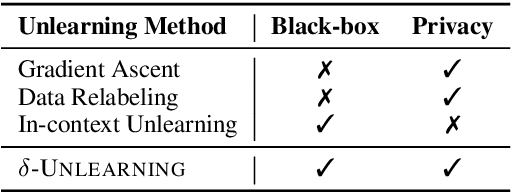
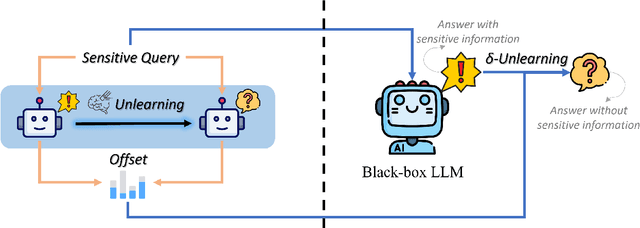

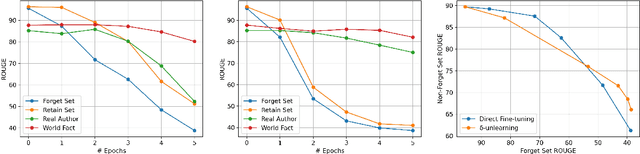
Despite the strong capabilities of Large Language Models (LLMs) to acquire knowledge from their training corpora, the memorization of sensitive information in the corpora such as copyrighted, harmful, and private content has led to ethical and legal concerns. In response to these challenges, unlearning has emerged as a potential remedy for LLMs affected by problematic training data. However, previous unlearning techniques are either not applicable to black-box LLMs due to required access to model internal weights, or violate data protection principles by retaining sensitive data for inference-time correction. We propose $\delta$-unlearning, an offset unlearning framework for black-box LLMs. Instead of tuning the black-box LLM itself, $\delta$-unlearning learns the logit offset needed for unlearning by contrasting the logits from a pair of smaller models. Experiments demonstrate that $\delta$-unlearning can effectively unlearn target data while maintaining similar or even stronger performance on general out-of-forget-scope tasks. $\delta$-unlearning also effectively incorporates different unlearning algorithms, making our approach a versatile solution to adapting various existing unlearning algorithms to black-box LLMs.
Contrastive Instruction Tuning
Feb 17, 2024
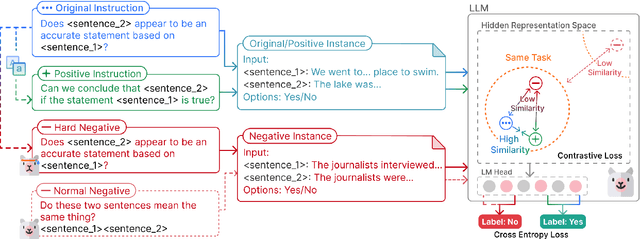
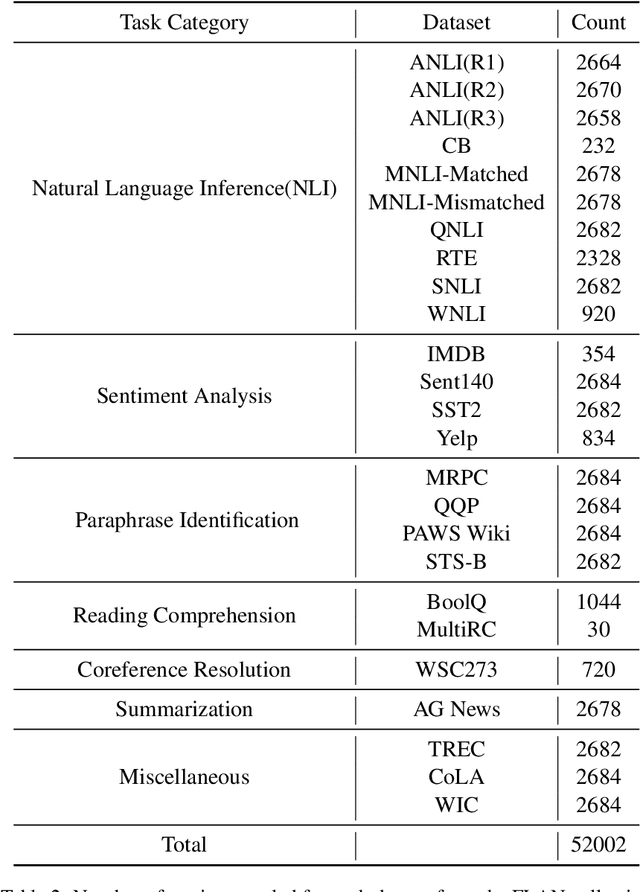
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy.
DeAL: Decoding-time Alignment for Large Language Models
Feb 05, 2024



Large Language Models (LLMs) are nowadays expected to generate content aligned with human preferences. Current work focuses on alignment at model training time, through techniques such as Reinforcement Learning with Human Feedback (RLHF). However, it is unclear if such methods are an effective choice to teach alignment objectives to the model. First, the inability to incorporate multiple, custom rewards and reliance on a model developer's view of universal and static principles are key limitations. Second, the residual gaps in model training and the reliability of such approaches are also questionable (e.g. susceptibility to jail-breaking even after safety training). To address these, we propose DeAL, a framework that allows the user to customize reward functions and enables Decoding-time Alignment of LLMs (DeAL). At its core, we view decoding as a heuristic-guided search process and facilitate the use of a wide variety of alignment objectives. Our experiments with programmatic constraints such as keyword and length constraints (studied widely in the pre-LLM era) and abstract objectives such as harmlessness and helpfulness (proposed in the post-LLM era) show that we can DeAL with fine-grained trade-offs, improve adherence to alignment objectives, and address residual gaps in LLMs. Lastly, while DeAL can be effectively paired with RLHF and prompting techniques, its generality makes decoding slower, an optimization we leave for future work.
Robust Natural Language Understanding with Residual Attention Debiasing
May 28, 2023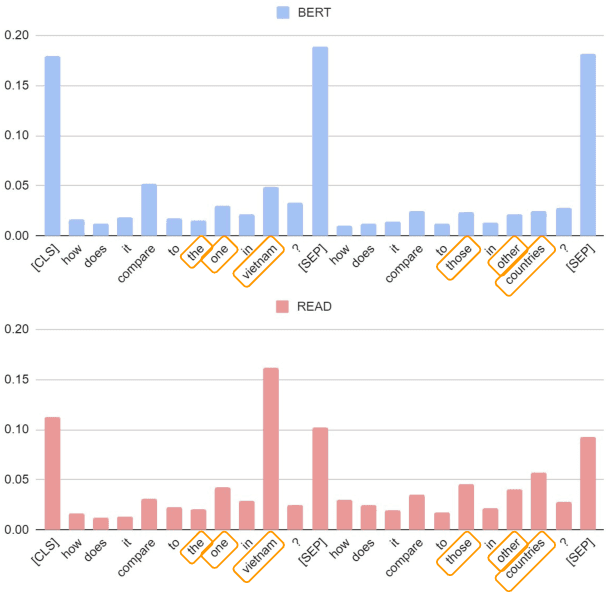
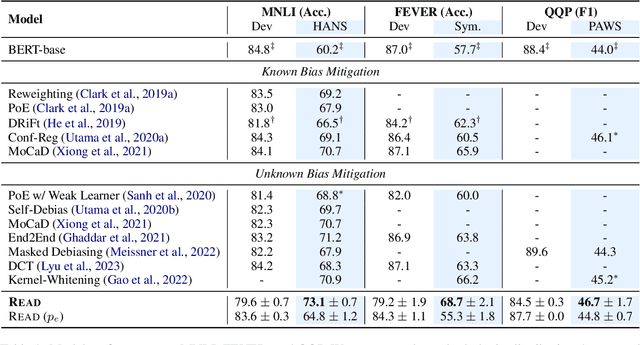
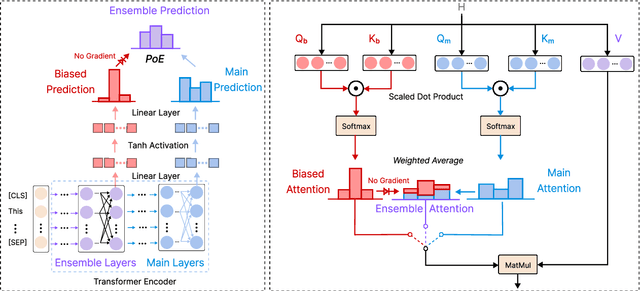

Natural language understanding (NLU) models often suffer from unintended dataset biases. Among bias mitigation methods, ensemble-based debiasing methods, especially product-of-experts (PoE), have stood out for their impressive empirical success. However, previous ensemble-based debiasing methods typically apply debiasing on top-level logits without directly addressing biased attention patterns. Attention serves as the main media of feature interaction and aggregation in PLMs and plays a crucial role in providing robust prediction. In this paper, we propose REsidual Attention Debiasing (READ), an end-to-end debiasing method that mitigates unintended biases from attention. Experiments on three NLU tasks show that READ significantly improves the performance of BERT-based models on OOD data with shortcuts removed, including +12.9% accuracy on HANS, +11.0% accuracy on FEVER-Symmetric, and +2.7% F1 on PAWS. Detailed analyses demonstrate the crucial role of unbiased attention in robust NLU models and that READ effectively mitigates biases in attention. Code is available at https://github.com/luka-group/READ.
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
May 24, 2023Traditional sentence embedding models encode sentences into vector representations to capture useful properties such as the semantic similarity between sentences. However, in addition to similarity, sentence semantics can also be interpreted via compositional operations such as sentence fusion or difference. It is unclear whether the compositional semantics of sentences can be directly reflected as compositional operations in the embedding space. To more effectively bridge the continuous embedding and discrete text spaces, we explore the plausibility of incorporating various compositional properties into the sentence embedding space that allows us to interpret embedding transformations as compositional sentence operations. We propose InterSent, an end-to-end framework for learning interpretable sentence embeddings that supports compositional sentence operations in the embedding space. Our method optimizes operator networks and a bottleneck encoder-decoder model to produce meaningful and interpretable sentence embeddings. Experimental results demonstrate that our method significantly improves the interpretability of sentence embeddings on four textual generation tasks over existing approaches while maintaining strong performance on traditional semantic similarity tasks.
Parameter-Efficient Tuning with Special Token Adaptation
Oct 10, 2022

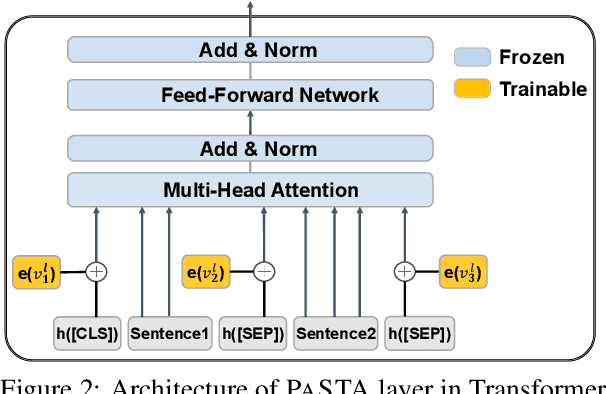
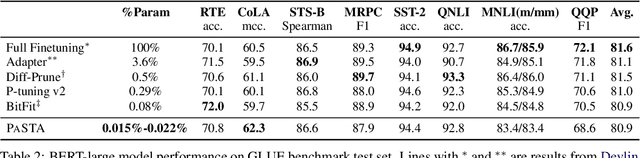
Parameter-efficient tuning aims at updating only a small subset of parameters when adapting a pretrained model to downstream tasks. In this work, we introduce PASTA, in which we only modify the special token representations (e.g., [SEP] and [CLS] in BERT) before the self-attention module at each layer in Transformer-based models. PASTA achieves comparable performance to fine-tuning in natural language understanding tasks including text classification and NER with up to only 0.029% of total parameters trained. Our work not only provides a simple yet effective way of parameter-efficient tuning, which has a wide range of practical applications when deploying finetuned models for multiple tasks, but also demonstrates the pivotal role of special tokens in pretrained language models.
Unified Semantic Typing with Meaningful Label Inference
May 04, 2022



Semantic typing aims at classifying tokens or spans of interest in a textual context into semantic categories such as relations, entity types, and event types. The inferred labels of semantic categories meaningfully interpret how machines understand components of text. In this paper, we present UniST, a unified framework for semantic typing that captures label semantics by projecting both inputs and labels into a joint semantic embedding space. To formulate different lexical and relational semantic typing tasks as a unified task, we incorporate task descriptions to be jointly encoded with the input, allowing UniST to be adapted to different tasks without introducing task-specific model components. UniST optimizes a margin ranking loss such that the semantic relatedness of the input and labels is reflected from their embedding similarity. Our experiments demonstrate that UniST achieves strong performance across three semantic typing tasks: entity typing, relation classification and event typing. Meanwhile, UniST effectively transfers semantic knowledge of labels and substantially improves generalizability on inferring rarely seen and unseen types. In addition, multiple semantic typing tasks can be jointly trained within the unified framework, leading to a single compact multi-tasking model that performs comparably to dedicated single-task models, while offering even better transferability.