 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAnalog: A Diagnostic Suite for Visual Concept Transfer on Natural Images
May 22, 2026A useful test of visual concept learning is not just whether a model can recognize a concept in a single image, but whether it can preserve and manipulate concept-level properties under transformation and transfer them to new scenes. We introduce VisAnalog, a controlled suite for this setting on natural images. Each example instantiates $A\!:\!B::C\!:\,?$: images $B$ and a hidden target image $D$ are produced by applying the same deterministic transformation sequence to source images $A$ and $C$. Given $A$, $B$, and $C$, a model must answer a multiple-choice question about $D$. The benchmark contains 617 human-validated questions spanning one- to four-step transformations such as zoom, quadrant swap, rotation, flip, and hue rotation. Across strong proprietary and open-source VLMs, end-to-end accuracy is substantially lower than oracle accuracy when $D$ is directly shown, and degrades sharply as transformation depth increases, while human performance remains near the ceiling. A program-conditioned evaluation further separates failures of relation inference from failures of transformation application, showing that inferring the visual relation from $A \rightarrow B$ is the dominant bottleneck, with additional application errors emerging on harder multi-step cases. The dataset is publicly available at https://huggingface.co/datasets/zli99/VisAnalog.
Reinforced Attention Learning
Feb 04, 2026Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) through verbose rationales yields limited gains for perception and can even degrade performance. We propose Reinforced Attention Learning (RAL), a policy-gradient framework that directly optimizes internal attention distributions rather than output token sequences. By shifting optimization from what to generate to where to attend, RAL promotes effective information allocation and improved grounding in complex multimodal inputs. Experiments across diverse image and video benchmarks show consistent gains over GRPO and other baselines. We further introduce On-Policy Attention Distillation, demonstrating that transferring latent attention behaviors yields stronger cross-modal alignment than standard knowledge distillation. Our results position attention policies as a principled and general alternative for multimodal post-training.
Unbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
QLIP: A Dynamic Quadtree Vision Prior Enhances MLLM Performance Without Retraining
May 29, 2025Multimodal Large Language Models (MLLMs) encode images into visual tokens, aligning visual and textual signals within a shared latent space to facilitate crossmodal representation learning. The CLIP model is a widely adopted foundational vision language model whose vision encoder has played a critical role in the development of MLLMs such as LLaVA. However, the CLIP vision encoder suffers from notable limitations including being constrained to only handling fixed input resolutions and a failure to produce separated embeddings for dissimilar images. Replacing the vision encoder of an existing model typically incurs substantial computational costs because such a change often necessitates retraining the entire model pipeline. In this work, we identify two factors which underlie the limitations of the CLIP vision encoder: mesoscopic bias and interpolation bias. To address these issues, we propose QLIP, a drop-in replacement for CLIP that can be seamlessly integrated with existing MLLMs with only a few lines of code and can enhance both coarse-grained and fine-grained visual understanding, without re-training. QLIP is designed around an image quadtree which replaces the standard uniform grid patches with a novel content aware patchification. Our experimental results demonstrate that QLIP improves the general visual question answering accuracy of the LLaVA v1.5 model series across various model sizes--without requiring retraining or fine-tuning of the full MLLM. Notably, QLIP boosts detailed understanding performance on the challenging $V^{\ast}$ benchmark by up to 13.6 percent.
Diagnosing and Mitigating Modality Interference in Multimodal Large Language Models
May 26, 2025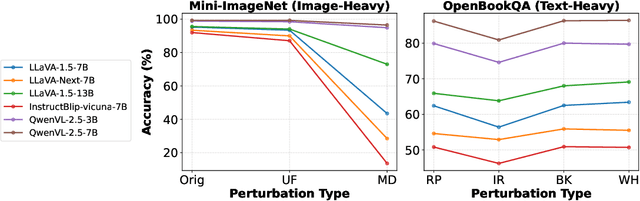
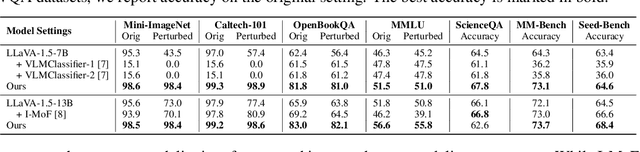
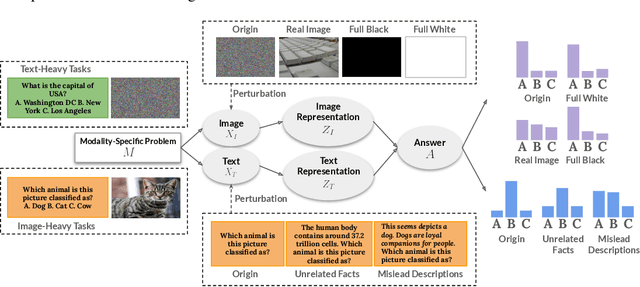
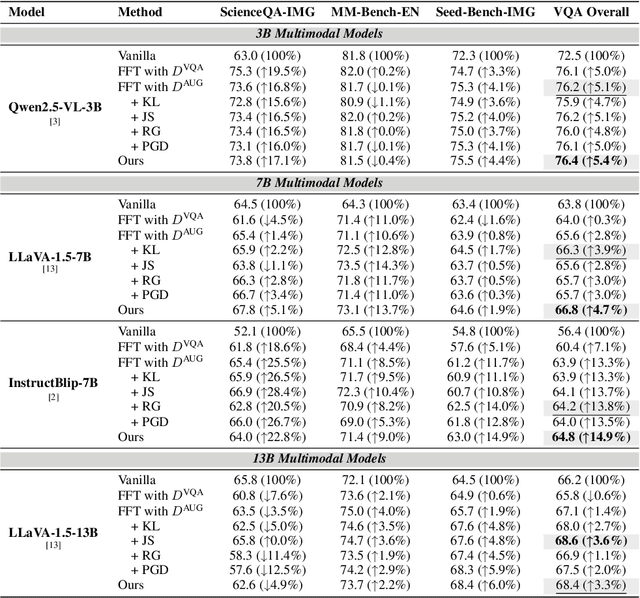
Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across tasks, yet they often exhibit difficulty in distinguishing task-relevant from irrelevant signals, particularly in tasks like Visual Question Answering (VQA), which can lead to susceptibility to misleading or spurious inputs. We refer to this broader limitation as the Cross-Modality Competency Problem: the model's inability to fairly evaluate all modalities. This vulnerability becomes more evident in modality-specific tasks such as image classification or pure text question answering, where models are expected to rely solely on one modality. In such tasks, spurious information from irrelevant modalities often leads to significant performance degradation. We refer to this failure as Modality Interference, which serves as a concrete and measurable instance of the cross-modality competency problem. We further design a perturbation-based causal diagnostic experiment to verify and quantify this problem. To mitigate modality interference, we propose a novel framework to fine-tune MLLMs, including perturbation-based data augmentations with both heuristic perturbations and adversarial perturbations via Projected Gradient Descent (PGD), and a consistency regularization strategy applied to model outputs with original and perturbed inputs. Experiments on multiple benchmark datasets (image-heavy, text-heavy, and VQA tasks) and multiple model families with different scales demonstrate significant improvements in robustness and cross-modality competency, indicating our method's effectiveness in boosting unimodal reasoning ability while enhancing performance on multimodal tasks.
Semantic-Clipping: Efficient Vision-Language Modeling with Semantic-Guidedd Visual Selection
Mar 14, 2025Vision-Language Models (VLMs) leverage aligned visual encoders to transform images into visual tokens, allowing them to be processed similarly to text by the backbone large language model (LLM). This unified input paradigm enables VLMs to excel in vision-language tasks such as visual question answering (VQA). To improve fine-grained visual reasoning, recent advancements in vision-language modeling introduce image cropping techniques that feed all encoded sub-images into the model. However, this approach significantly increases the number of visual tokens, leading to inefficiency and potential distractions for the LLM. To address the generalization challenges of image representation in VLMs, we propose a lightweight, universal framework that seamlessly integrates with existing VLMs to enhance their ability to process finegrained details. Our method leverages textual semantics to identify key visual areas, improving VQA performance without requiring any retraining of the VLM. Additionally, it incorporates textual signals into the visual encoding process, enhancing both efficiency and effectiveness. The proposed method, SEMCLIP, strengthens the visual understanding of a 7B VLM, LLaVA-1.5 by 3.3% on average across 7 benchmarks, and particularly by 5.3% on the challenging detailed understanding benchmark V*.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
FamiCom: Further Demystifying Prompts for Language Models with Task-Agnostic Performance Estimation
Jun 17, 2024



Language models have shown impressive in-context-learning capabilities, which allow them to benefit from input prompts and perform better on downstream end tasks. Existing works investigate the mechanisms behind this observation, and propose label-agnostic prompt metrics that can better estimate end-task performances. One popular approach is using perplexity as a way to measure models' familiarity with the prompt. While showing consistent improvements on in-domain tasks, we found that familiarity metrics such as perplexity cannot accurately estimate performance in complicated situations such as task or domain transferring scenarios. In this work, we propose a revised measure called FamiCom, providing a more comprehensive measure for task-agnostic performance estimation. Specifically, FamiCom combines familiarity with \textit{complexity} -- the inherent difficulty of end tasks, which is an important factor missing from current metrics. Experiments show that FamiCom strongly correlates with end-task performances, producing a 0.85 Spearman's correlation, versus 0.43 of familiarity-only ones'. We further apply FamiCom to automatic prompt and demonstration selection, and outperform existing methods and baselines by more than 7.0% in accuracy.
Rewarded Region Replay (R3) for Policy Learning with Discrete Action Space
May 26, 2024



We introduce a new on-policy algorithm called Rewarded Region Replay (R3), which significantly improves on PPO in solving environments with discrete action spaces. R3 improves sample efficiency by using a replay buffer which contains past successful trajectories with reward above a certain threshold, which are used to update a PPO agent with importance sampling. Crucially, we discard the importance sampling factors which are above a certain ratio to reduce variance and stabilize training. We found that R3 significantly outperforms PPO in Minigrid environments with sparse rewards and discrete action space, such as DoorKeyEnv and CrossingEnv, and moreover we found that the improvement margin of our method versus baseline PPO increases with the complexity of the environment. We also benchmarked the performance of R3 against DDQN (Double Deep Q-Network), which is a standard baseline in off-policy methods for discrete actions, and found that R3 also outperforms DDQN agent in DoorKeyEnv. Lastly, we adapt the idea of R3 to dense reward setting to obtain the Dense R3 algorithm (or DR3) and benchmarked it against PPO on Cartpole-V1 environment. We found that DR3 outperforms PPO significantly on this dense reward environment. Our code can be found at https://github.com/chry-santhemum/R3.
Red Teaming Language Models for Contradictory Dialogues
May 17, 2024



Most language models currently available are prone to self-contradiction during dialogues. To mitigate this issue, this study explores a novel contradictory dialogue processing task that aims to detect and modify contradictory statements in a conversation. This task is inspired by research on context faithfulness and dialogue comprehension, which have demonstrated that the detection and understanding of contradictions often necessitate detailed explanations. We develop a dataset comprising contradictory dialogues, in which one side of the conversation contradicts itself. Each dialogue is accompanied by an explanatory label that highlights the location and details of the contradiction. With this dataset, we present a Red Teaming framework for contradictory dialogue processing. The framework detects and attempts to explain the dialogue, then modifies the existing contradictory content using the explanation. Our experiments demonstrate that the framework improves the ability to detect contradictory dialogues and provides valid explanations. Additionally, it showcases distinct capabilities for modifying such dialogues. Our study highlights the importance of the logical inconsistency problem in conversational AI.