 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTA: Generating Long-Horizon Tasks for Web Agents at Scale
May 28, 2026Web agents, which couple language models with browsing and tool-use capabilities, show promise as open web assistants. Yet progress is increasingly limited by the lack of scalable, process-level supervision. Existing benchmarks are largely manually constructed, providing only coarse start-goal annotations without intermediate trajectories, while recent automatic generation efforts remain expensive, biased, and shallow. These limitations prevent reliable training and evaluation of agents that must generalize to realistic, multi-hop, cross-page tasks. We introduce a scalable framework, GTA, that integrates crawling, retrieval-based seeding, in-context generation, and automated quality control to produce realistic tasks paired with executable trajectories. This design decouples crawling from generation for greater efficiency, grounds tasks in the site graph to enforce compositionality, and ensures dense supervision through deterministic replays and systematic validation. We instantiate the pipeline on over 50 websites covering e-commerce, government, forums, and news, with multilingual and multi-hop coverage. The resulting benchmark reveals a significant human-agent performance gap and enables detailed diagnostics. Our contributions are three-fold: (i) formalizing multi-hop web-agent task generation, (ii) proposing an efficient and validated pipeline for automatic data creation, and (iii) releasing a dynamic benchmark with reproducible evaluation.
Optimizing Diversity and Quality through Base-Aligned Model Collaboration
Nov 07, 2025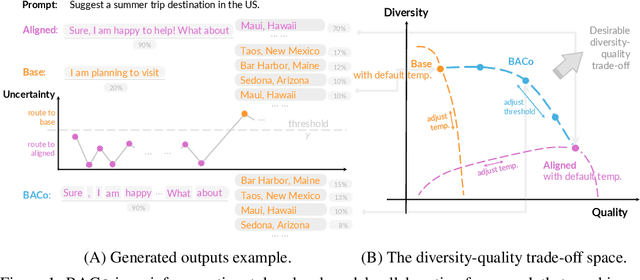
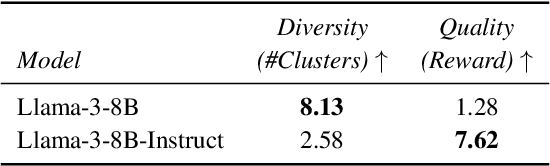
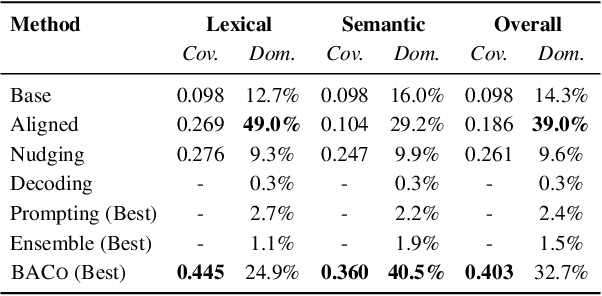
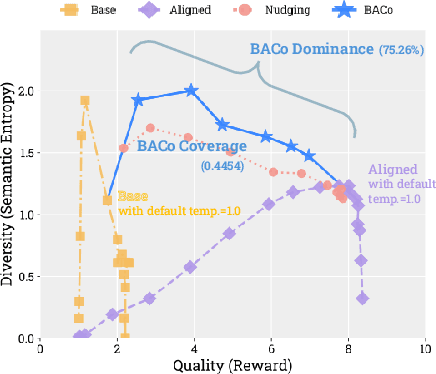
Alignment has greatly improved large language models (LLMs)' output quality at the cost of diversity, yielding highly similar outputs across generations. We propose Base-Aligned Model Collaboration (BACo), an inference-time token-level model collaboration framework that dynamically combines a base LLM with its aligned counterpart to optimize diversity and quality. Inspired by prior work (Fei et al., 2025), BACo employs routing strategies that determine, at each token, from which model to decode based on next-token prediction uncertainty and predicted contents' semantic role. Prior diversity-promoting methods, such as retraining, prompt engineering, and multi-sampling methods, improve diversity but often degrade quality or require costly decoding or post-training. In contrast, BACo achieves both high diversity and quality post hoc within a single pass, while offering strong controllability. We explore a family of routing strategies, across three open-ended generation tasks and 13 metrics covering diversity and quality, BACo consistently surpasses state-of-the-art inference-time baselines. With our best router, BACo achieves a 21.3% joint improvement in diversity and quality. Human evaluations also mirror these improvements. The results suggest that collaboration between base and aligned models can optimize and control diversity and quality.
DiscoSum: Discourse-aware News Summarization
Jun 07, 2025Recent advances in text summarization have predominantly leveraged large language models to generate concise summaries. However, language models often do not maintain long-term discourse structure, especially in news articles, where organizational flow significantly influences reader engagement. We introduce a novel approach to integrating discourse structure into summarization processes, focusing specifically on news articles across various media. We present a novel summarization dataset where news articles are summarized multiple times in different ways across different social media platforms (e.g. LinkedIn, Facebook, etc.). We develop a novel news discourse schema to describe summarization structures and a novel algorithm, DiscoSum, which employs beam search technique for structure-aware summarization, enabling the transformation of news stories to meet different stylistic and structural demands. Both human and automatic evaluation results demonstrate the efficacy of our approach in maintaining narrative fidelity and meeting structural requirements.
Are Large Language Models Capable of Generating Human-Level Narratives?
Jul 18, 2024



This paper investigates the capability of LLMs in storytelling, focusing on narrative development and plot progression. We introduce a novel computational framework to analyze narratives through three discourse-level aspects: i) story arcs, ii) turning points, and iii) affective dimensions, including arousal and valence. By leveraging expert and automatic annotations, we uncover significant discrepancies between the LLM- and human- written stories. While human-written stories are suspenseful, arousing, and diverse in narrative structures, LLM stories are homogeneously positive and lack tension. Next, we measure narrative reasoning skills as a precursor to generative capacities, concluding that most LLMs fall short of human abilities in discourse understanding. Finally, we show that explicit integration of aforementioned discourse features can enhance storytelling, as is demonstrated by over 40% improvement in neural storytelling in terms of diversity, suspense, and arousal.
Red Teaming Language Models for Contradictory Dialogues
May 17, 2024



Most language models currently available are prone to self-contradiction during dialogues. To mitigate this issue, this study explores a novel contradictory dialogue processing task that aims to detect and modify contradictory statements in a conversation. This task is inspired by research on context faithfulness and dialogue comprehension, which have demonstrated that the detection and understanding of contradictions often necessitate detailed explanations. We develop a dataset comprising contradictory dialogues, in which one side of the conversation contradicts itself. Each dialogue is accompanied by an explanatory label that highlights the location and details of the contradiction. With this dataset, we present a Red Teaming framework for contradictory dialogue processing. The framework detects and attempts to explain the dialogue, then modifies the existing contradictory content using the explanation. Our experiments demonstrate that the framework improves the ability to detect contradictory dialogues and provides valid explanations. Additionally, it showcases distinct capabilities for modifying such dialogues. Our study highlights the importance of the logical inconsistency problem in conversational AI.
Planning and Editing What You Retrieve for Enhanced Tool Learning
Apr 04, 2024Recent advancements in integrating external tools with Large Language Models (LLMs) have opened new frontiers, with applications in mathematical reasoning, code generators, and smart assistants. However, existing methods, relying on simple one-time retrieval strategies, fall short on effectively and accurately shortlisting relevant tools. This paper introduces a novel PLUTO (Planning, Learning, and Understanding for TOols) approach, encompassing `Plan-and-Retrieve (P&R)` and `Edit-and-Ground (E&G)` paradigms. The P&R paradigm consists of a neural retrieval module for shortlisting relevant tools and an LLM-based query planner that decomposes complex queries into actionable tasks, enhancing the effectiveness of tool utilization. The E&G paradigm utilizes LLMs to enrich tool descriptions based on user scenarios, bridging the gap between user queries and tool functionalities. Experiment results demonstrate that these paradigms significantly improve the recall and NDCG in tool retrieval tasks, significantly surpassing current state-of-the-art models.
Affective and Dynamic Beam Search for Story Generation
Oct 23, 2023



Storytelling's captivating potential makes it a fascinating research area, with implications for entertainment, education, therapy, and cognitive studies. In this paper, we propose Affective Story Generator (AffGen) for generating interesting narratives. AffGen introduces "intriguing twists" in narratives by employing two novel techniques-Dynamic Beam Sizing and Affective Reranking. Dynamic Beam Sizing encourages less predictable, more captivating word choices using a contextual multi-arm bandit model. Affective Reranking prioritizes sentence candidates based on affect intensity. Our empirical evaluations, both automatic and human, demonstrate AffGen's superior performance over existing baselines in generating affectively charged and interesting narratives. Our ablation study and analysis provide insights into the strengths and weaknesses of AffGen.
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Jun 07, 2023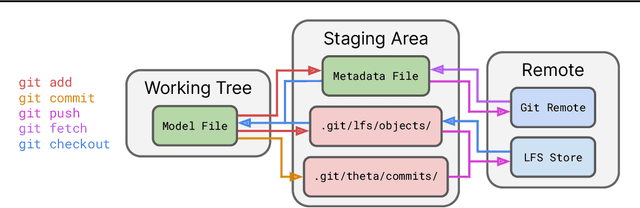
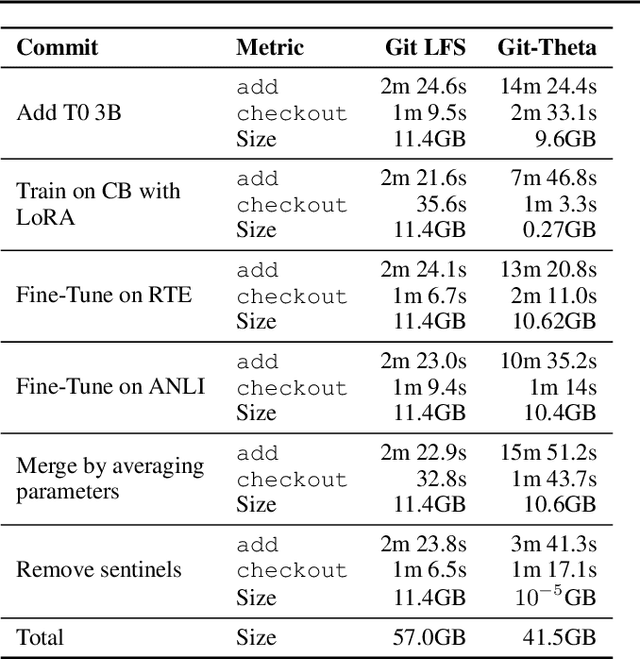
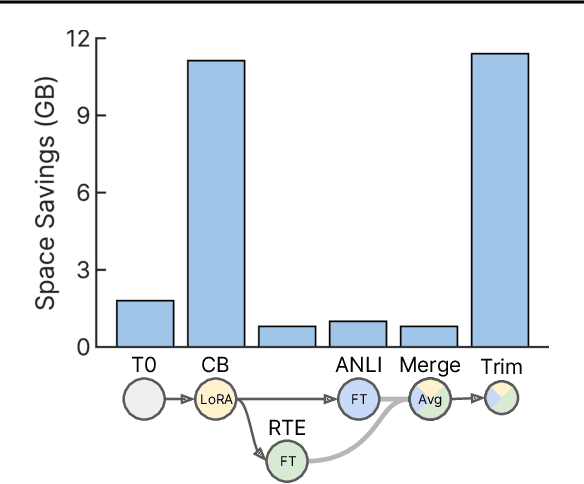
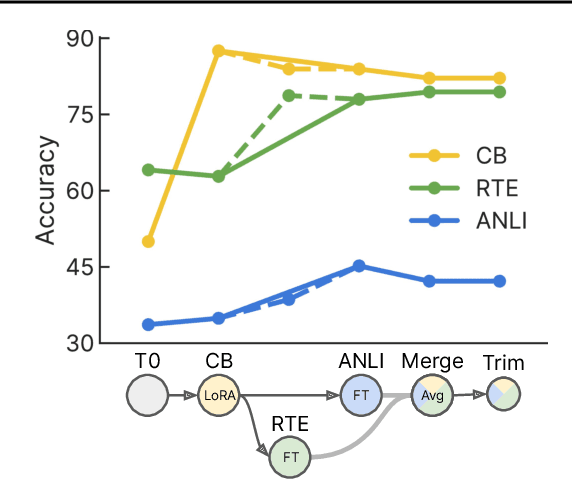
Currently, most machine learning models are trained by centralized teams and are rarely updated. In contrast, open-source software development involves the iterative development of a shared artifact through distributed collaboration using a version control system. In the interest of enabling collaborative and continual improvement of machine learning models, we introduce Git-Theta, a version control system for machine learning models. Git-Theta is an extension to Git, the most widely used version control software, that allows fine-grained tracking of changes to model parameters alongside code and other artifacts. Unlike existing version control systems that treat a model checkpoint as a blob of data, Git-Theta leverages the structure of checkpoints to support communication-efficient updates, automatic model merges, and meaningful reporting about the difference between two versions of a model. In addition, Git-Theta includes a plug-in system that enables users to easily add support for new functionality. In this paper, we introduce Git-Theta's design and features and include an example use-case of Git-Theta where a pre-trained model is continually adapted and modified. We publicly release Git-Theta in hopes of kickstarting a new era of collaborative model development.
Revisiting Generative Commonsense Reasoning: A Pre-Ordering Approach
May 26, 2022

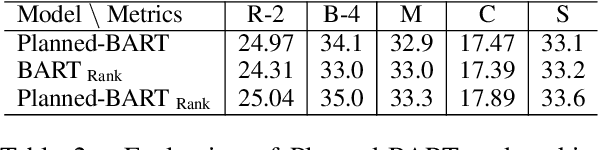
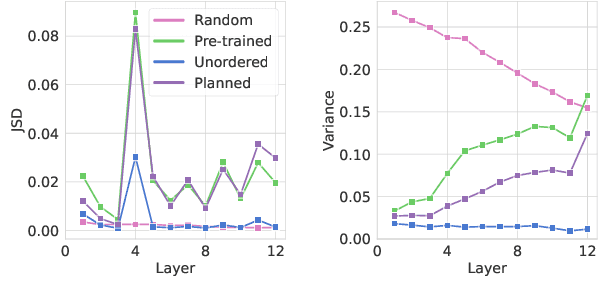
Pre-trained models (PTMs) have lead to great improvements in natural language generation (NLG). However, it is still unclear how much commonsense knowledge they possess. With the goal of evaluating commonsense knowledge of NLG models, recent work has proposed the problem of generative commonsense reasoning, e.g., to compose a logical sentence given a set of unordered concepts. Existing approaches to this problem hypothesize that PTMs lack sufficient parametric knowledge for this task, which can be overcome by introducing external knowledge or task-specific pre-training objectives. Different from this trend, we argue that PTM's inherent ability for generative commonsense reasoning is underestimated due to the order-agnostic property of its input. In particular, we hypothesize that the order of the input concepts can affect the PTM's ability to utilize its commonsense knowledge. To this end, we propose a pre-ordering approach to elaborately manipulate the order of the given concepts before generation. Experiments show that our approach can outperform the more sophisticated models that have access to a lot of external data and resources.
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
May 11, 2022
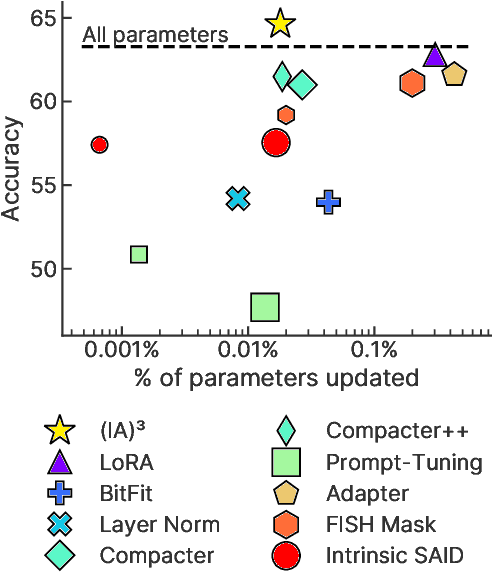
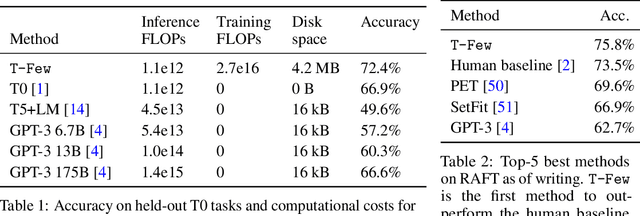
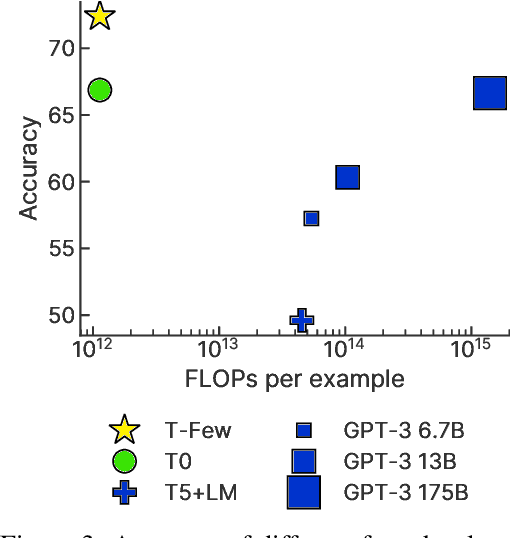
Few-shot in-context learning (ICL) enables pre-trained language models to perform a previously-unseen task without any gradient-based training by feeding a small number of training examples as part of the input. ICL incurs substantial computational, memory, and storage costs because it involves processing all of the training examples every time a prediction is made. Parameter-efficient fine-tuning (e.g. adapter modules, prompt tuning, sparse update methods, etc.) offers an alternative paradigm where a small set of parameters are trained to enable a model to perform the new task. In this paper, we rigorously compare few-shot ICL and parameter-efficient fine-tuning and demonstrate that the latter offers better accuracy as well as dramatically lower computational costs. Along the way, we introduce a new parameter-efficient fine-tuning method called (IA)$^3$ that scales activations by learned vectors, attaining stronger performance while only introducing a relatively tiny amount of new parameters. We also propose a simple recipe based on the T0 model called T-Few that can be applied to new tasks without task-specific tuning or modifications. We validate the effectiveness of T-Few on completely unseen tasks by applying it to the RAFT benchmark, attaining super-human performance for the first time and outperforming the state-of-the-art by 6% absolute. All of the code used in our experiments is publicly available.