 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Realistic Evaluation of Model Merging for Compositional Generalization
Sep 26, 2024Merging has become a widespread way to cheaply combine individual models into a single model that inherits their capabilities and attains better performance. This popularity has spurred rapid development of many new merging methods, which are typically validated in disparate experimental settings and frequently differ in the assumptions made about model architecture, data availability, and computational budget. In this work, we characterize the relative merits of different merging methods by evaluating them in a shared experimental setting and precisely identifying the practical requirements of each method. Specifically, our setting focuses on using merging for compositional generalization of capabilities in image classification, image generation, and natural language processing. Additionally, we measure the computational costs of different merging methods as well as how they perform when scaling the number of models being merged. Taken together, our results clarify the state of the field of model merging and provide a comprehensive and rigorous experimental setup to test new methods.
Training LLMs over Neurally Compressed Text
Apr 04, 2024



In this paper, we explore the idea of training large language models (LLMs) over highly compressed text. While standard subword tokenizers compress text by a small factor, neural text compressors can achieve much higher rates of compression. If it were possible to train LLMs directly over neurally compressed text, this would confer advantages in training and serving efficiency, as well as easier handling of long text spans. The main obstacle to this goal is that strong compression tends to produce opaque outputs that are not well-suited for learning. In particular, we find that text na\"ively compressed via Arithmetic Coding is not readily learnable by LLMs. To overcome this, we propose Equal-Info Windows, a novel compression technique whereby text is segmented into blocks that each compress to the same bit length. Using this method, we demonstrate effective learning over neurally compressed text that improves with scale, and outperforms byte-level baselines by a wide margin on perplexity and inference speed benchmarks. While our method delivers worse perplexity than subword tokenizers for models trained with the same parameter count, it has the benefit of shorter sequence lengths. Shorter sequence lengths require fewer autoregressive generation steps, and reduce latency. Finally, we provide extensive analysis of the properties that contribute to learnability, and offer concrete suggestions for how to further improve the performance of high-compression tokenizers.
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Jun 07, 2023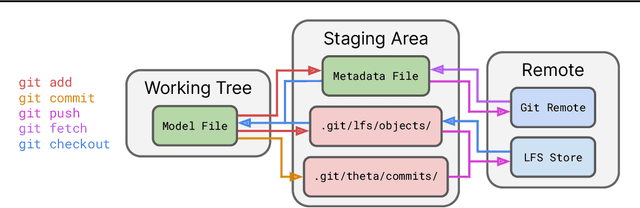
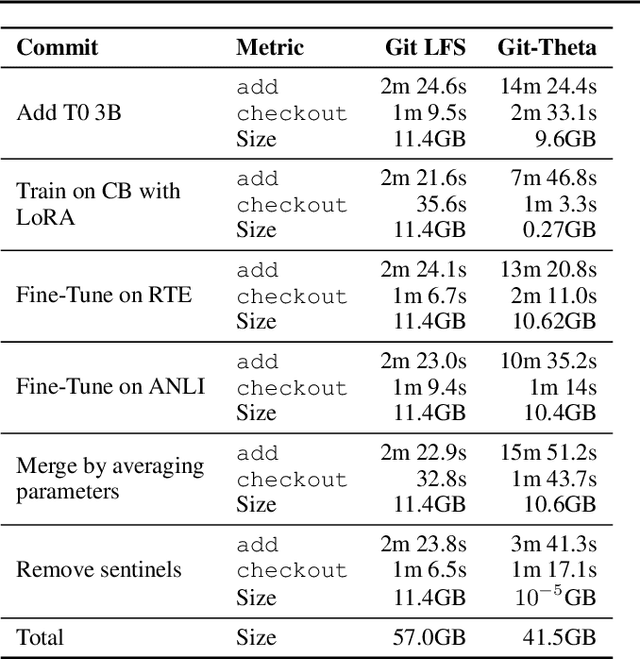
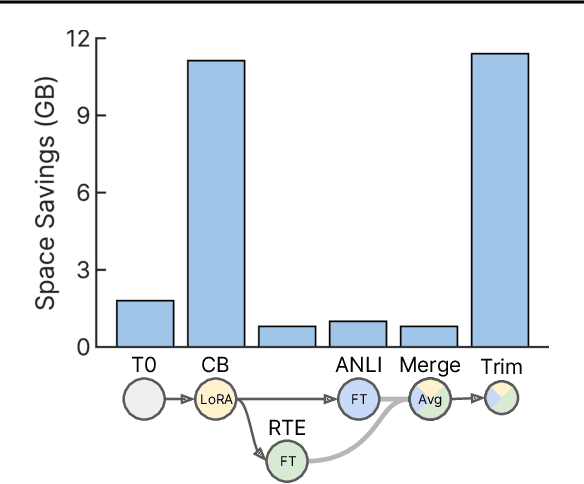
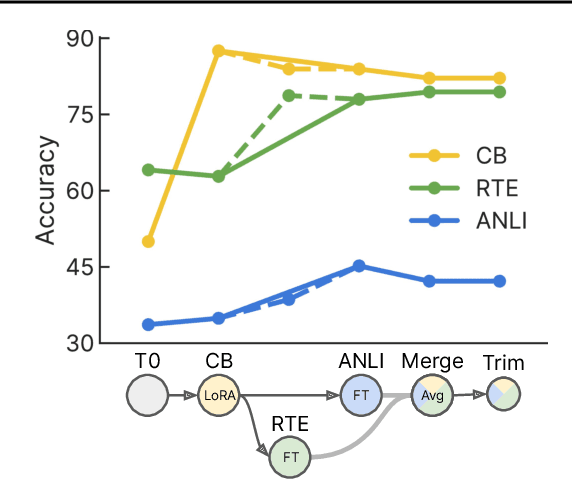
Currently, most machine learning models are trained by centralized teams and are rarely updated. In contrast, open-source software development involves the iterative development of a shared artifact through distributed collaboration using a version control system. In the interest of enabling collaborative and continual improvement of machine learning models, we introduce Git-Theta, a version control system for machine learning models. Git-Theta is an extension to Git, the most widely used version control software, that allows fine-grained tracking of changes to model parameters alongside code and other artifacts. Unlike existing version control systems that treat a model checkpoint as a blob of data, Git-Theta leverages the structure of checkpoints to support communication-efficient updates, automatic model merges, and meaningful reporting about the difference between two versions of a model. In addition, Git-Theta includes a plug-in system that enables users to easily add support for new functionality. In this paper, we introduce Git-Theta's design and features and include an example use-case of Git-Theta where a pre-trained model is continually adapted and modified. We publicly release Git-Theta in hopes of kickstarting a new era of collaborative model development.
Reducing Retraining by Recycling Parameter-Efficient Prompts
Aug 10, 2022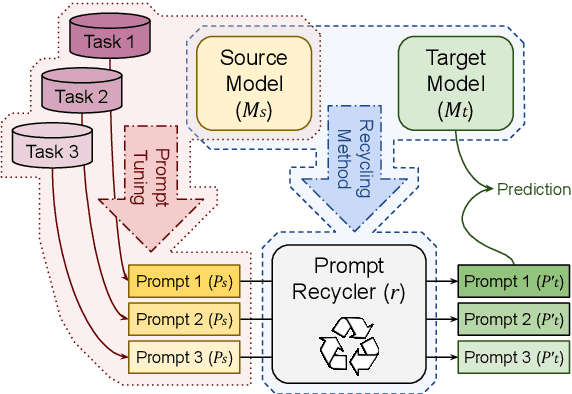
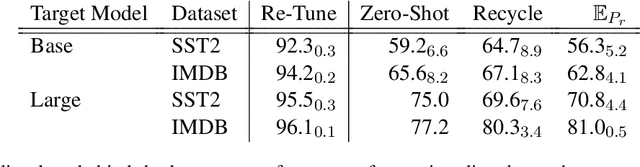
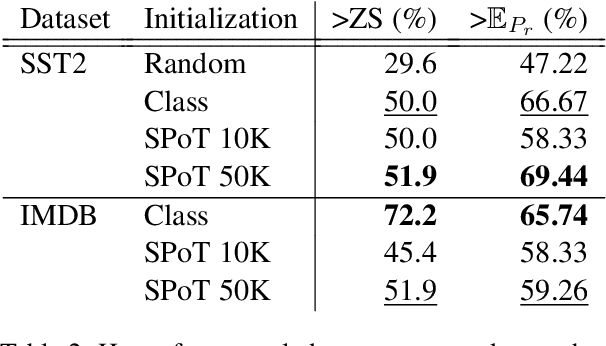
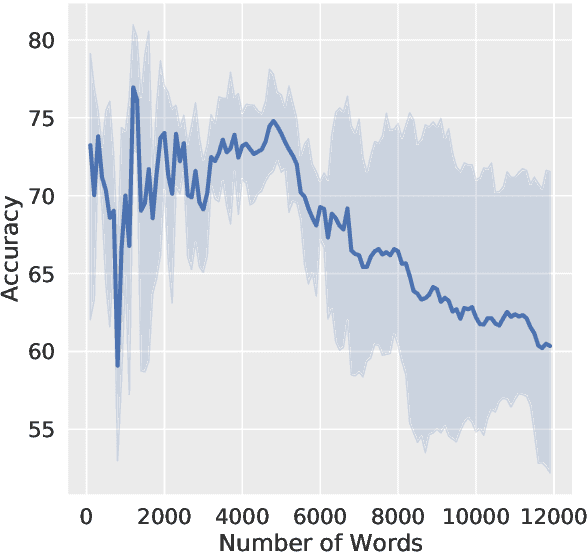
Parameter-efficient methods are able to use a single frozen pre-trained large language model (LLM) to perform many tasks by learning task-specific soft prompts that modulate model behavior when concatenated to the input text. However, these learned prompts are tightly coupled to a given frozen model -- if the model is updated, corresponding new prompts need to be obtained. In this work, we propose and investigate several approaches to "Prompt Recycling'" where a prompt trained on a source model is transformed to work with the new target model. Our methods do not rely on supervised pairs of prompts, task-specific data, or training updates with the target model, which would be just as costly as re-tuning prompts with the target model from scratch. We show that recycling between models is possible (our best settings are able to successfully recycle $88.9\%$ of prompts, producing a prompt that out-performs baselines), but significant performance headroom remains, requiring improved recycling techniques.
Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation
May 25, 2022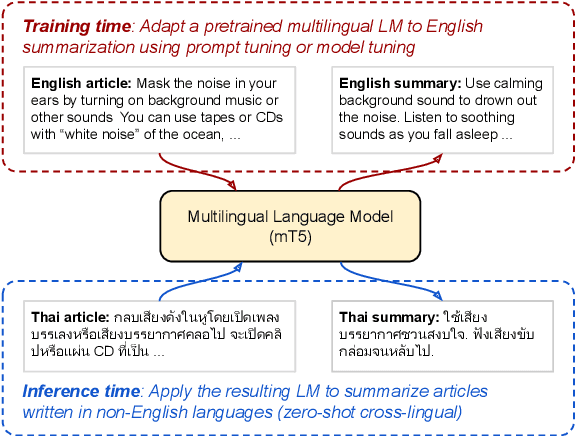
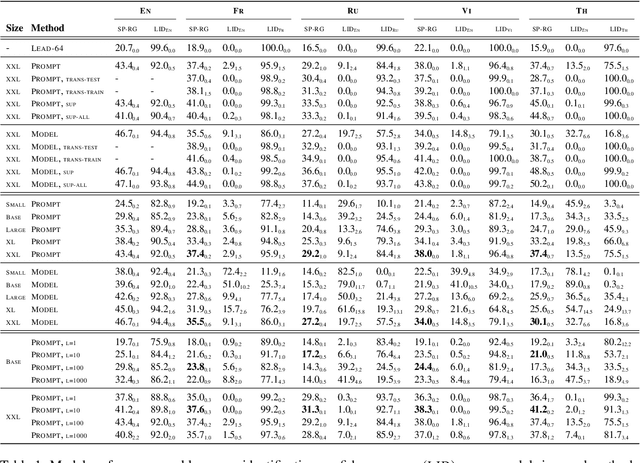
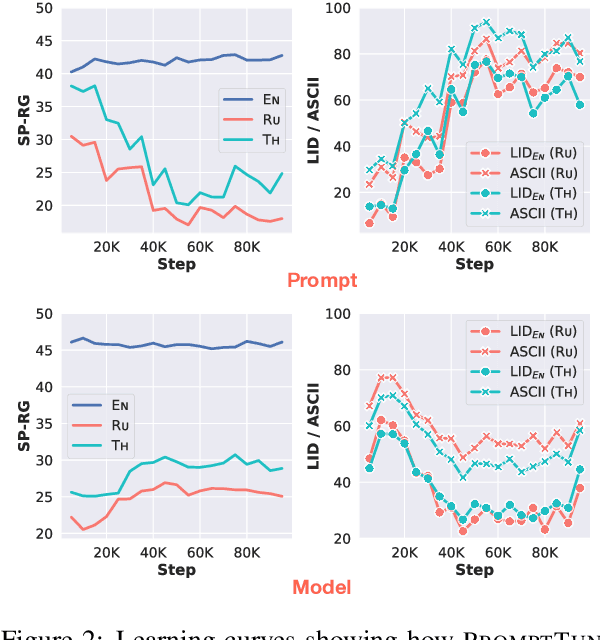
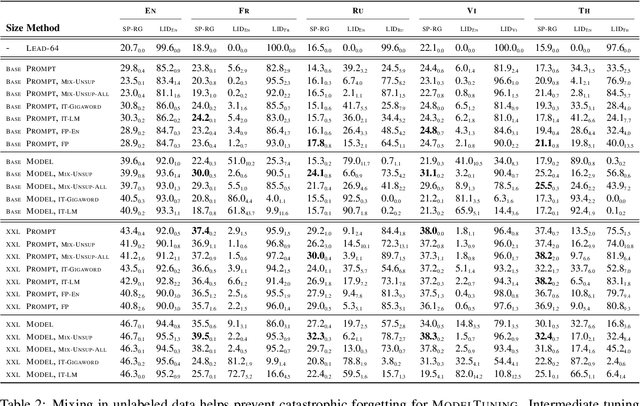
In this paper, we explore the challenging problem of performing a generative task (i.e., summarization) in a target language when labeled data is only available in English. We assume a strict setting with no access to parallel data or machine translation. Prior work has shown, and we confirm, that standard transfer learning techniques struggle in this setting, as a generative multilingual model fine-tuned purely on English catastrophically forgets how to generate non-English. Given the recent rise of parameter-efficient adaptation techniques (e.g., prompt tuning), we conduct the first investigation into how well these methods can overcome catastrophic forgetting to enable zero-shot cross-lingual generation. We find that parameter-efficient adaptation provides gains over standard fine-tuning when transferring between less-related languages, e.g., from English to Thai. However, a significant gap still remains between these methods and fully-supervised baselines. To improve cross-lingual transfer further, we explore three approaches: (1) mixing in unlabeled multilingual data, (2) pre-training prompts on target language data, and (3) explicitly factoring prompts into recombinable language and task components. Our methods can provide further quality gains, suggesting that robust zero-shot cross-lingual generation is within reach.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022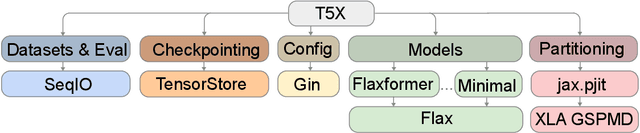
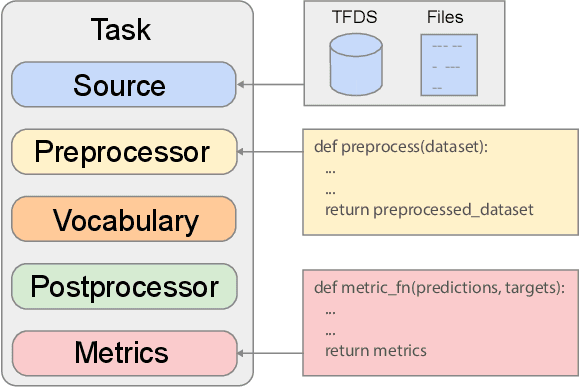
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
Oct 15, 2021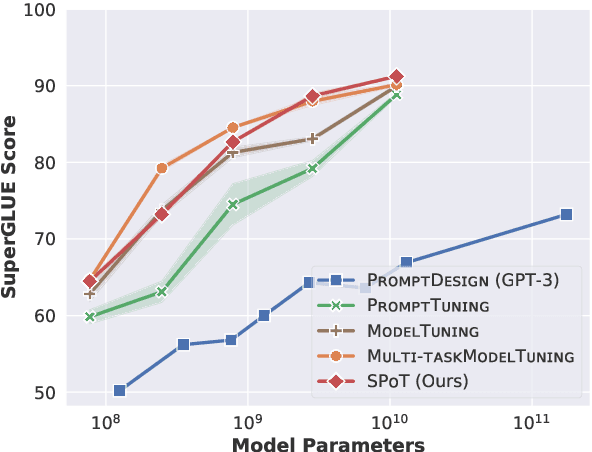
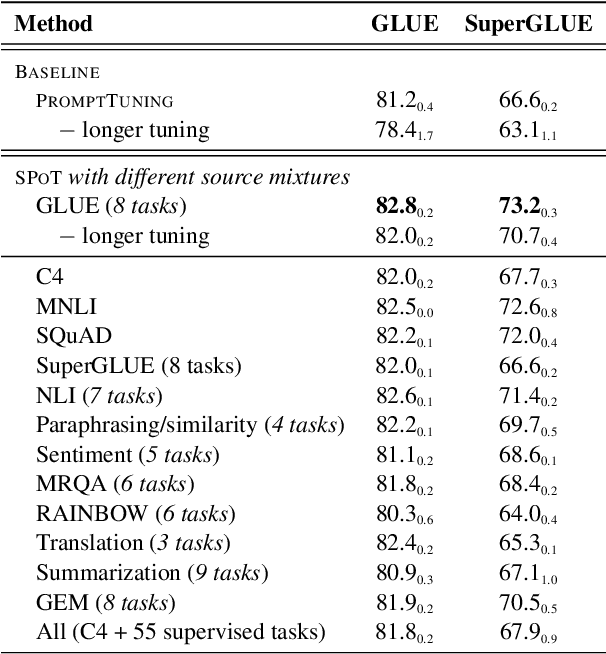
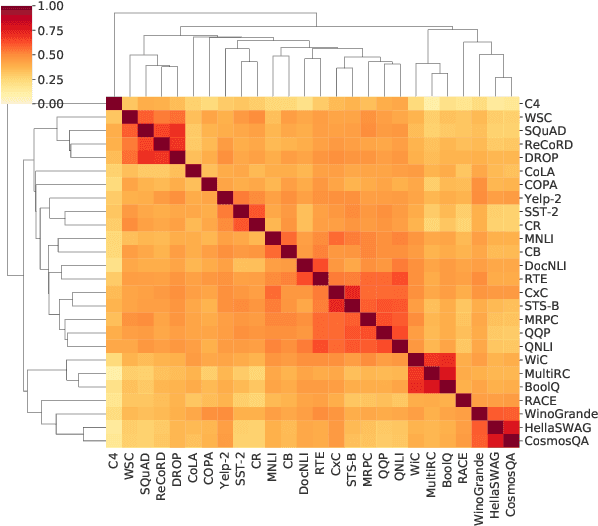
As pre-trained language models have gotten larger, there has been growing interest in parameter-efficient methods to apply these models to downstream tasks. Building on the PromptTuning approach of Lester et al. (2021), which learns task-specific soft prompts to condition a frozen language model to perform downstream tasks, we propose a novel prompt-based transfer learning approach called SPoT: Soft Prompt Transfer. SPoT first learns a prompt on one or more source tasks and then uses it to initialize the prompt for a target task. We show that SPoT significantly boosts the performance of PromptTuning across many tasks. More importantly, SPoT either matches or outperforms ModelTuning, which fine-tunes the entire model on each individual task, across all model sizes while being more parameter-efficient (up to 27,000x fewer task-specific parameters). We further conduct a large-scale study on task transferability with 26 NLP tasks and 160 combinations of source-target tasks, and demonstrate that tasks can often benefit each other via prompt transfer. Finally, we propose a simple yet efficient retrieval approach that interprets task prompts as task embeddings to identify the similarity between tasks and predict the most transferable source tasks for a given novel target task.
Finetuned Language Models Are Zero-Shot Learners
Sep 03, 2021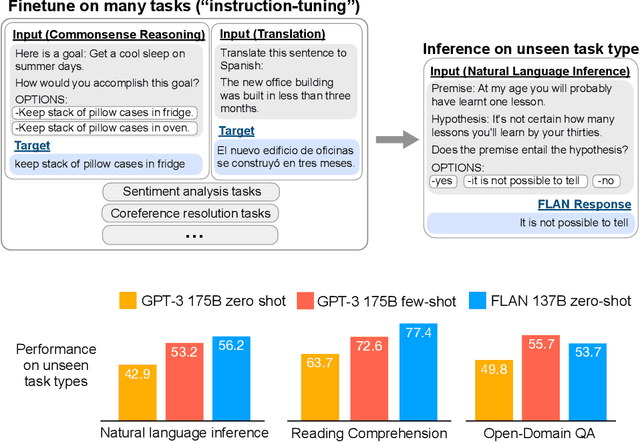
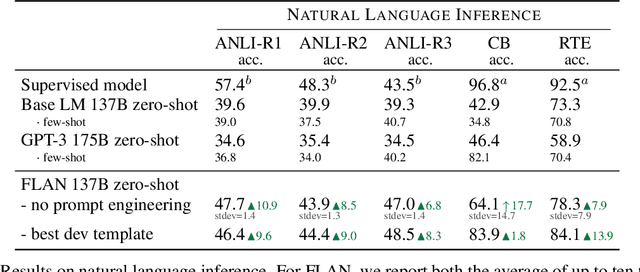
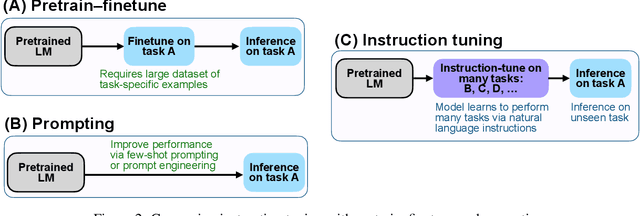
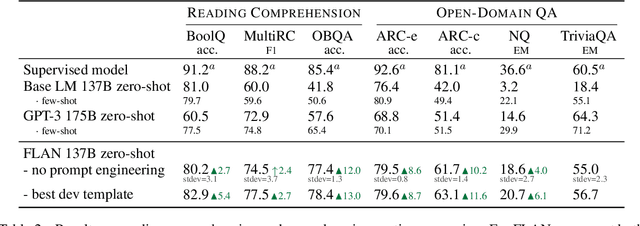
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially boosts zero-shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction-tune it on over 60 NLP tasks verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 19 of 25 tasks that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of tasks and model scale are key components to the success of instruction tuning.