 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthBench: Evaluating Large Language Models Towards Improved Human Health
May 13, 2025We present HealthBench, an open-source benchmark measuring the performance and safety of large language models in healthcare. HealthBench consists of 5,000 multi-turn conversations between a model and an individual user or healthcare professional. Responses are evaluated using conversation-specific rubrics created by 262 physicians. Unlike previous multiple-choice or short-answer benchmarks, HealthBench enables realistic, open-ended evaluation through 48,562 unique rubric criteria spanning several health contexts (e.g., emergencies, transforming clinical data, global health) and behavioral dimensions (e.g., accuracy, instruction following, communication). HealthBench performance over the last two years reflects steady initial progress (compare GPT-3.5 Turbo's 16% to GPT-4o's 32%) and more rapid recent improvements (o3 scores 60%). Smaller models have especially improved: GPT-4.1 nano outperforms GPT-4o and is 25 times cheaper. We additionally release two HealthBench variations: HealthBench Consensus, which includes 34 particularly important dimensions of model behavior validated via physician consensus, and HealthBench Hard, where the current top score is 32%. We hope that HealthBench grounds progress towards model development and applications that benefit human health.
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Apr 16, 2025We present BrowseComp, a simple yet challenging benchmark for measuring the ability for agents to browse the web. BrowseComp comprises 1,266 questions that require persistently navigating the internet in search of hard-to-find, entangled information. Despite the difficulty of the questions, BrowseComp is simple and easy-to-use, as predicted answers are short and easily verifiable against reference answers. BrowseComp for browsing agents can be seen as analogous to how programming competitions are an incomplete but useful benchmark for coding agents. While BrowseComp sidesteps challenges of a true user query distribution, like generating long answers or resolving ambiguity, it measures the important core capability of exercising persistence and creativity in finding information. BrowseComp can be found at https://github.com/openai/simple-evals.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Deliberative Alignment: Reasoning Enables Safer Language Models
Dec 20, 2024As large-scale language models increasingly impact safety-critical domains, ensuring their reliable adherence to well-defined principles remains a fundamental challenge. We introduce Deliberative Alignment, a new paradigm that directly teaches the model safety specifications and trains it to explicitly recall and accurately reason over the specifications before answering. We used this approach to align OpenAI's o-series models, and achieved highly precise adherence to OpenAI's safety policies, without requiring human-written chain-of-thoughts or answers. Deliberative Alignment pushes the Pareto frontier by simultaneously increasing robustness to jailbreaks while decreasing overrefusal rates, and also improves out-of-distribution generalization. We demonstrate that reasoning over explicitly specified policies enables more scalable, trustworthy, and interpretable alignment.
Measuring short-form factuality in large language models
Nov 07, 2024



We present SimpleQA, a benchmark that evaluates the ability of language models to answer short, fact-seeking questions. We prioritized two properties in designing this eval. First, SimpleQA is challenging, as it is adversarially collected against GPT-4 responses. Second, responses are easy to grade, because questions are created such that there exists only a single, indisputable answer. Each answer in SimpleQA is graded as either correct, incorrect, or not attempted. A model with ideal behavior would get as many questions correct as possible while not attempting the questions for which it is not confident it knows the correct answer. SimpleQA is a simple, targeted evaluation for whether models "know what they know," and our hope is that this benchmark will remain relevant for the next few generations of frontier models. SimpleQA can be found at https://github.com/openai/simple-evals.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
Oct 05, 2023



Most large language models (LLMs) are trained once and never updated; thus, they lack the ability to dynamically adapt to our ever-changing world. In this work, we perform a detailed study of the factuality of LLM-generated text in the context of answering questions that test current world knowledge. Specifically, we introduce FreshQA, a novel dynamic QA benchmark encompassing a diverse range of question and answer types, including questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked. We benchmark a diverse array of both closed and open-source LLMs under a two-mode evaluation procedure that allows us to measure both correctness and hallucination. Through human evaluations involving more than 50K judgments, we shed light on limitations of these models and demonstrate significant room for improvement: for instance, all models (regardless of model size) struggle on questions that involve fast-changing knowledge and false premises. Motivated by these results, we present FreshPrompt, a simple few-shot prompting method that substantially boosts the performance of an LLM on FreshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Our experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask (Press et al., 2022) as well as commercial systems such as Perplexity.AI. Further analysis of FreshPrompt reveals that both the number of retrieved evidences and their order play a key role in influencing the correctness of LLM-generated answers. Additionally, instructing the LLM to generate concise and direct answers helps reduce hallucination compared to encouraging more verbose answers. To facilitate future work, we release FreshQA at github.com/freshllms/freshqa and commit to updating it at regular intervals.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity
May 22, 2023



Pretraining is the preliminary and fundamental step in developing capable language models (LM). Despite this, pretraining data design is critically under-documented and often guided by empirically unsupported intuitions. To address this, we pretrain 28 1.5B parameter decoder-only models, training on data curated (1) at different times, (2) with varying toxicity and quality filters, and (3) with different domain compositions. First, we quantify the effect of pretraining data age. A temporal shift between evaluation data and pretraining data leads to performance degradation, which is not overcome by finetuning. Second, we explore the effect of quality and toxicity filters, showing a trade-off between performance on standard benchmarks and risk of toxic generations. Our findings indicate there does not exist a one-size-fits-all solution to filtering training data. We also find that the effects of different types of filtering are not predictable from text domain characteristics. Lastly, we empirically validate that the inclusion of heterogeneous data sources, like books and web, is broadly beneficial and warrants greater prioritization. These findings constitute the largest set of experiments to validate, quantify, and expose many undocumented intuitions about text pretraining, which we hope will help support more informed data-centric decisions in LM development.
Larger language models do in-context learning differently
Mar 08, 2023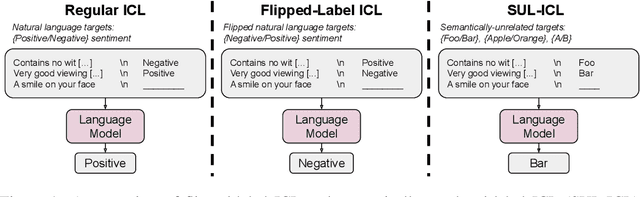



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.