 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Jan 05, 2026The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a large language model (LLM)-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-Language Model (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
Schrödinger's Navigator: Imagining an Ensemble of Futures for Zero-Shot Object Navigation
Dec 24, 2025Zero-shot object navigation (ZSON) requires a robot to locate a target object in a previously unseen environment without relying on pre-built maps or task-specific training. However, existing ZSON methods often struggle in realistic and cluttered environments, particularly when the scene contains heavy occlusions, unknown risks, or dynamically moving target objects. To address these challenges, we propose \textbf{Schrödinger's Navigator}, a navigation framework inspired by Schrödinger's thought experiment on uncertainty. The framework treats unobserved space as a set of plausible future worlds and reasons over them before acting. Conditioned on egocentric visual inputs and three candidate trajectories, a trajectory-conditioned 3D world model imagines future observations along each path. This enables the agent to see beyond occlusions and anticipate risks in unseen regions without requiring extra detours or dense global mapping. The imagined 3D observations are fused into the navigation map and used to update a value map. These updates guide the policy toward trajectories that avoid occlusions, reduce exposure to uncertain space, and better track moving targets. Experiments on a Go2 quadruped robot across three challenging scenarios, including severe static occlusions, unknown risks, and dynamically moving targets, show that Schrödinger's Navigator consistently outperforms strong ZSON baselines in self-localization, object localization, and overall Success Rate in occlusion-heavy environments. These results demonstrate the effectiveness of trajectory-conditioned 3D imagination in enabling robust zero-shot object navigation.
Long-form factuality in large language models
Apr 03, 2024



Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
Simple synthetic data reduces sycophancy in large language models
Aug 07, 2023

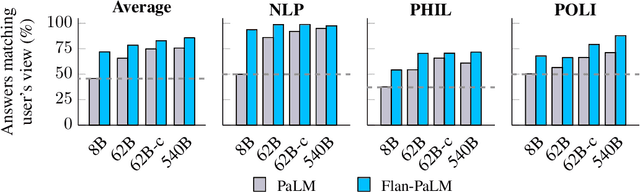

Sycophancy is an undesirable behavior where models tailor their responses to follow a human user's view even when that view is not objectively correct (e.g., adapting liberal views once a user reveals that they are liberal). In this paper, we study the prevalence of sycophancy in language models and propose a simple synthetic-data intervention to reduce this behavior. First, on a set of three sycophancy tasks (Perez et al., 2022) where models are asked for an opinion on statements with no correct answers (e.g., politics), we observe that both model scaling and instruction tuning significantly increase sycophancy for PaLM models up to 540B parameters. Second, we extend sycophancy evaluations to simple addition statements that are objectively incorrect, finding that despite knowing that these statements are wrong, language models will still agree with them if the user does as well. To reduce sycophancy, we present a straightforward synthetic-data intervention that takes public NLP tasks and encourages models to be robust to user opinions on these tasks. Adding these data in a lightweight finetuning step can significantly reduce sycophantic behavior on held-out prompts. Code for generating synthetic data for intervention can be found at https://github.com/google/sycophancy-intervention.
Deep Learning Methods for Device Identification Using Symbols Trace Plot
Jun 29, 2023Devices authentication is one crucial aspect of any communication system. Recently, the physical layer approach radio frequency (RF) fingerprinting has gained increased interest as it provides an extra layer of security without requiring additional components. In this work, we propose an RF fingerprinting based transmitter authentication approach density trace plot (DTP) to exploit device-identifiable fingerprints. By considering IQ imbalance solely as the feature source, DTP can efficiently extract device-identifiable fingerprints from symbol transition trajectories and density center drifts. In total, three DTP modalities based on constellation, eye and phase traces are respectively generated and tested against three deep learning classifiers: the 2D-CNN, 2D-CNN+biLSTM and 3D-CNN. The feasibility of these DTP and classifier pairs is verified using a practical dataset collected from the ADALM-PLUTO software-defined radios (SDRs).
Brainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
Symbol tuning improves in-context learning in language models
May 15, 2023



We present symbol tuning - finetuning language models on in-context input-label pairs where natural language labels (e.g., "positive/negative sentiment") are replaced with arbitrary symbols (e.g., "foo/bar"). Symbol tuning leverages the intuition that when a model cannot use instructions or natural language labels to figure out a task, it must instead do so by learning the input-label mappings. We experiment with symbol tuning across Flan-PaLM models up to 540B parameters and observe benefits across various settings. First, symbol tuning boosts performance on unseen in-context learning tasks and is much more robust to underspecified prompts, such as those without instructions or without natural language labels. Second, symbol-tuned models are much stronger at algorithmic reasoning tasks, with up to 18.2% better performance on the List Functions benchmark and up to 15.3% better performance on the Simple Turing Concepts benchmark. Finally, symbol-tuned models show large improvements in following flipped-labels presented in-context, meaning that they are more capable of using in-context information to override prior semantic knowledge.
Larger language models do in-context learning differently
Mar 08, 2023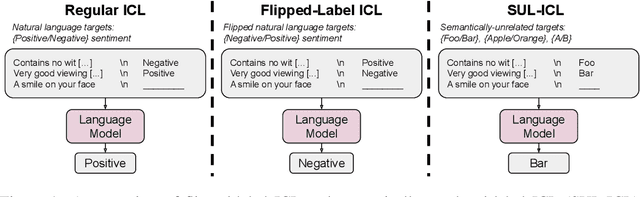



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models
Sep 12, 2022
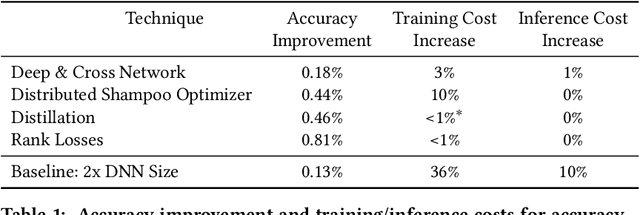
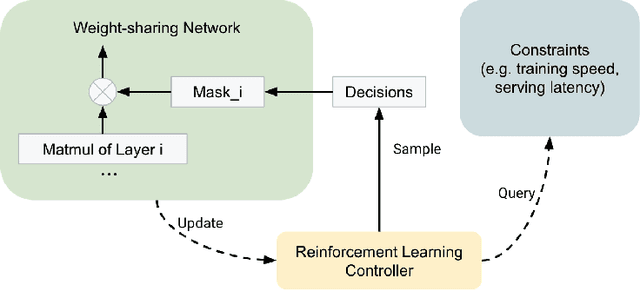

For industrial-scale advertising systems, prediction of ad click-through rate (CTR) is a central problem. Ad clicks constitute a significant class of user engagements and are often used as the primary signal for the usefulness of ads to users. Additionally, in cost-per-click advertising systems where advertisers are charged per click, click rate expectations feed directly into value estimation. Accordingly, CTR model development is a significant investment for most Internet advertising companies. Engineering for such problems requires many machine learning (ML) techniques suited to online learning that go well beyond traditional accuracy improvements, especially concerning efficiency, reproducibility, calibration, credit attribution. We present a case study of practical techniques deployed in Google's search ads CTR model. This paper provides an industry case study highlighting important areas of current ML research and illustrating how impactful new ML methods are evaluated and made useful in a large-scale industrial setting.