 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPNet: Simplifying Graph Neural Networks via Multi-channel Geometric Polynomials
Sep 30, 2022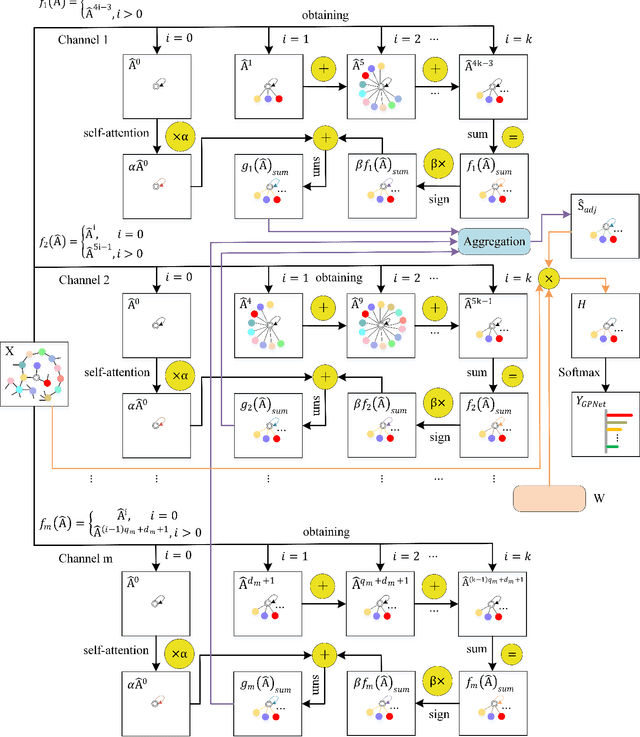

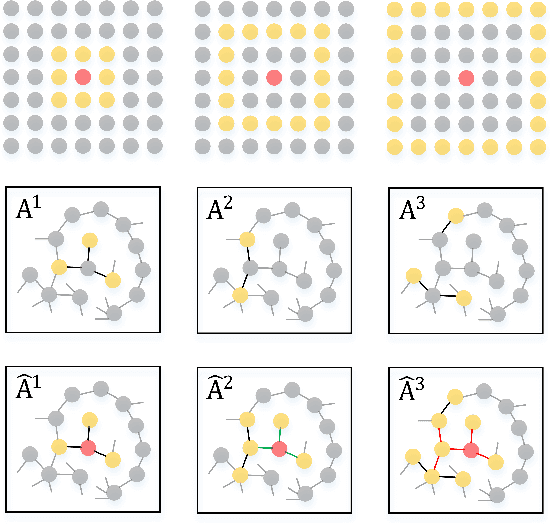
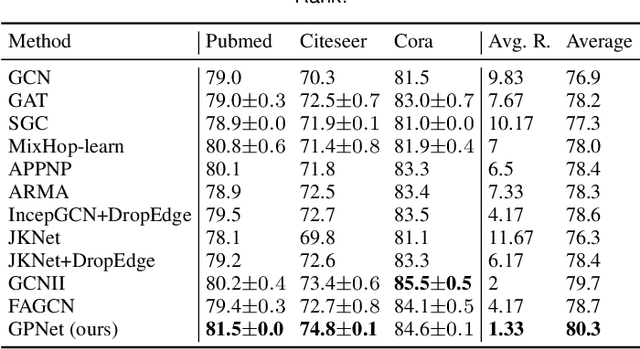
Graph Neural Networks (GNNs) are a promising deep learning approach for circumventing many real-world problems on graph-structured data. However, these models usually have at least one of four fundamental limitations: over-smoothing, over-fitting, difficult to train, and strong homophily assumption. For example, Simple Graph Convolution (SGC) is known to suffer from the first and fourth limitations. To tackle these limitations, we identify a set of key designs including (D1) dilated convolution, (D2) multi-channel learning, (D3) self-attention score, and (D4) sign factor to boost learning from different types (i.e. homophily and heterophily) and scales (i.e. small, medium, and large) of networks, and combine them into a graph neural network, GPNet, a simple and efficient one-layer model. We theoretically analyze the model and show that it can approximate various graph filters by adjusting the self-attention score and sign factor. Experiments show that GPNet consistently outperforms baselines in terms of average rank, average accuracy, complexity, and parameters on semi-supervised and full-supervised tasks, and achieves competitive performance compared to state-of-the-art model with inductive learning task.
PatentNet: A Large-Scale Incomplete Multiview, Multimodal, Multilabel Industrial Goods Image Database
Jun 23, 2021
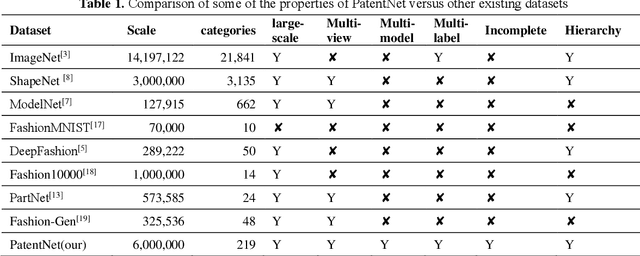
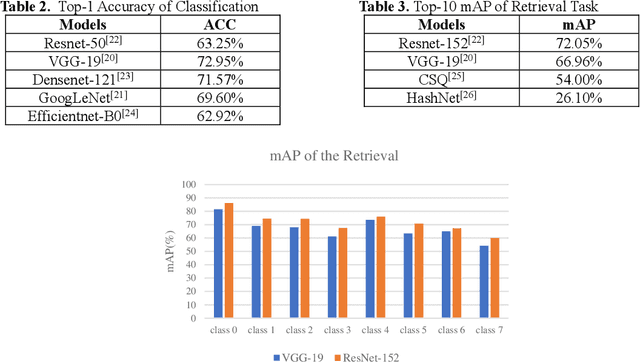

In deep learning area, large-scale image datasets bring a breakthrough in the success of object recognition and retrieval. Nowadays, as the embodiment of innovation, the diversity of the industrial goods is significantly larger, in which the incomplete multiview, multimodal and multilabel are different from the traditional dataset. In this paper, we introduce an industrial goods dataset, namely PatentNet, with numerous highly diverse, accurate and detailed annotations of industrial goods images, and corresponding texts. In PatentNet, the images and texts are sourced from design patent. Within over 6M images and corresponding texts of industrial goods labeled manually checked by professionals, PatentNet is the first ongoing industrial goods image database whose varieties are wider than industrial goods datasets used previously for benchmarking. PatentNet organizes millions of images into 32 classes and 219 subclasses based on the Locarno Classification Agreement. Through extensive experiments on image classification, image retrieval and incomplete multiview clustering, we demonstrate that our PatentNet is much more diverse, complex, and challenging, enjoying higher potentials than existing industrial image datasets. Furthermore, the characteristics of incomplete multiview, multimodal and multilabel in PatentNet are able to offer unparalleled opportunities in the artificial intelligence community and beyond.