 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatentNet: A Large-Scale Incomplete Multiview, Multimodal, Multilabel Industrial Goods Image Database
Jun 23, 2021
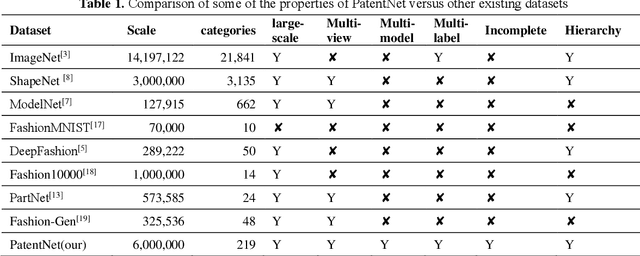
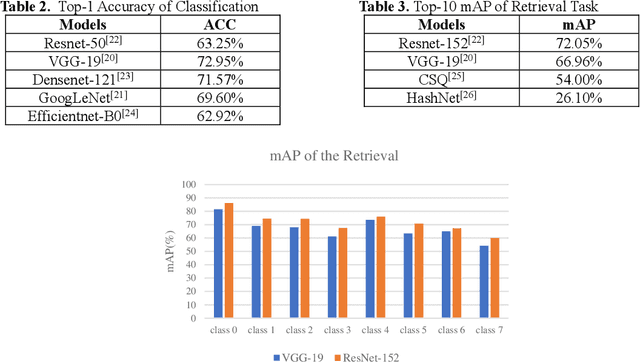

In deep learning area, large-scale image datasets bring a breakthrough in the success of object recognition and retrieval. Nowadays, as the embodiment of innovation, the diversity of the industrial goods is significantly larger, in which the incomplete multiview, multimodal and multilabel are different from the traditional dataset. In this paper, we introduce an industrial goods dataset, namely PatentNet, with numerous highly diverse, accurate and detailed annotations of industrial goods images, and corresponding texts. In PatentNet, the images and texts are sourced from design patent. Within over 6M images and corresponding texts of industrial goods labeled manually checked by professionals, PatentNet is the first ongoing industrial goods image database whose varieties are wider than industrial goods datasets used previously for benchmarking. PatentNet organizes millions of images into 32 classes and 219 subclasses based on the Locarno Classification Agreement. Through extensive experiments on image classification, image retrieval and incomplete multiview clustering, we demonstrate that our PatentNet is much more diverse, complex, and challenging, enjoying higher potentials than existing industrial image datasets. Furthermore, the characteristics of incomplete multiview, multimodal and multilabel in PatentNet are able to offer unparalleled opportunities in the artificial intelligence community and beyond.
BERT-hLSTMs: BERT and Hierarchical LSTMs for Visual Storytelling
Dec 03, 2020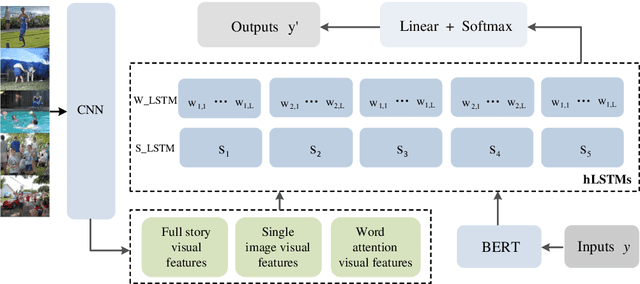

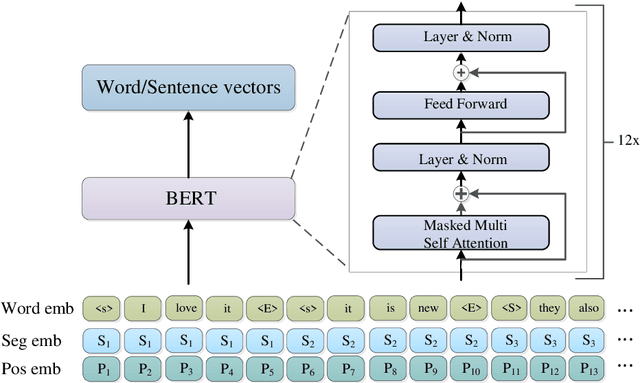
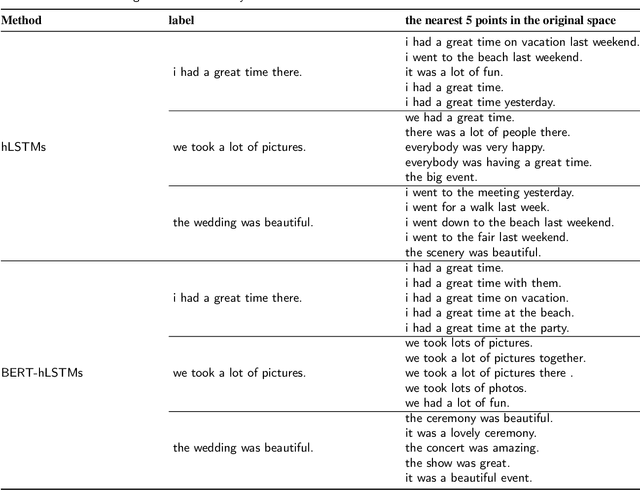
Visual storytelling is a creative and challenging task, aiming to automatically generate a story-like description for a sequence of images. The descriptions generated by previous visual storytelling approaches lack coherence because they use word-level sequence generation methods and do not adequately consider sentence-level dependencies. To tackle this problem, we propose a novel hierarchical visual storytelling framework which separately models sentence-level and word-level semantics. We use the transformer-based BERT to obtain embeddings for sentences and words. We then employ a hierarchical LSTM network: the bottom LSTM receives as input the sentence vector representation from BERT, to learn the dependencies between the sentences corresponding to images, and the top LSTM is responsible for generating the corresponding word vector representations, taking input from the bottom LSTM. Experimental results demonstrate that our model outperforms most closely related baselines under automatic evaluation metrics BLEU and CIDEr, and also show the effectiveness of our method with human evaluation.
Generating Descriptions for Sequential Images with Local-Object Attention and Global Semantic Context Modelling
Dec 02, 2020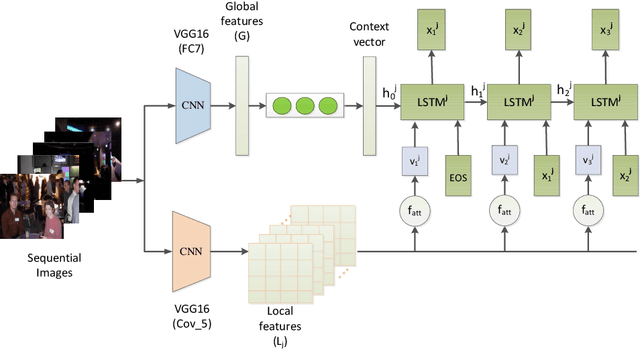
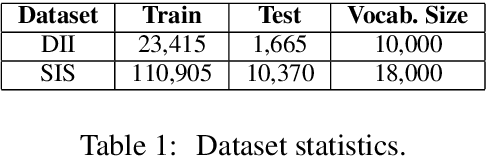

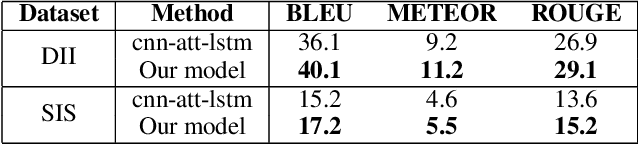
In this paper, we propose an end-to-end CNN-LSTM model for generating descriptions for sequential images with a local-object attention mechanism. To generate coherent descriptions, we capture global semantic context using a multi-layer perceptron, which learns the dependencies between sequential images. A paralleled LSTM network is exploited for decoding the sequence descriptions. Experimental results show that our model outperforms the baseline across three different evaluation metrics on the datasets published by Microsoft.