 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Divergence in Ego-centric Action Recognition under Spatial and Spatiotemporal Manipulations
Mar 09, 2026Humans consistently outperform state-of-the-art AI models in action recognition, particularly in challenging real-world conditions involving low resolution, occlusion, and visual clutter. Understanding the sources of this performance gap is essential for developing more robust and human-aligned models. In this paper, we present a large-scale human-AI comparative study of egocentric action recognition using Minimal Identifiable Recognition Crops (MIRCs), defined as the smallest spatial or spatiotemporal regions sufficient for reliable human recognition. We used our previously introduced, Epic ReduAct, a systematically spatially reduced and temporally scrambled dataset derived from 36 EPIC KITCHENS videos, spanning multiple spatial reduction levels and temporal conditions. Recognition performance is evaluated using over 3,000 human participants and the Side4Video model. Our analysis combines quantitative metrics, Average Reduction Rate and Recognition Gap, with qualitative analyses of spatial (high-, mid-, and low-level visual features) and spatiotemporal factors, including a categorisation of actions into Low Temporal Actions (LTA) and High Temporal Actions (HTA). Results show that human performance exhibits sharp declines when transitioning from MIRCs to subMIRCs, reflecting a strong reliance on sparse, semantically critical cues such as hand-object interactions. In contrast, the model degrades more gradually and often relies on contextual and mid- to low-level features, sometimes even exhibiting increased confidence under spatial reduction. Temporally, humans remain robust to scrambling when key spatial cues are preserved, whereas the model often shows insensitivity to temporal disruption, revealing class-dependent temporal sensitivities.
Automated Multiple Mini Interview (MMI) Scoring
Feb 02, 2026Assessing soft skills such as empathy, ethical judgment, and communication is essential in competitive selection processes, yet human scoring is often inconsistent and biased. While Large Language Models (LLMs) have improved Automated Essay Scoring (AES), we show that state-of-the-art rationale-based fine-tuning methods struggle with the abstract, context-dependent nature of Multiple Mini-Interviews (MMIs), missing the implicit signals embedded in candidate narratives. We introduce a multi-agent prompting framework that breaks down the evaluation process into transcript refinement and criterion-specific scoring. Using 3-shot in-context learning with a large instruct-tuned model, our approach outperforms specialised fine-tuned baselines (Avg QWK 0.62 vs 0.32) and achieves reliability comparable to human experts. We further demonstrate the generalisability of our framework on the ASAP benchmark, where it rivals domain-specific state-of-the-art models without additional training. These findings suggest that for complex, subjective reasoning tasks, structured prompt engineering may offer a scalable alternative to data-intensive fine-tuning, altering how LLMs can be applied to automated assessment.
AP-VLM: Active Perception Enabled by Vision-Language Models
Sep 26, 2024Active perception enables robots to dynamically gather information by adjusting their viewpoints, a crucial capability for interacting with complex, partially observable environments. In this paper, we present AP-VLM, a novel framework that combines active perception with a Vision-Language Model (VLM) to guide robotic exploration and answer semantic queries. Using a 3D virtual grid overlaid on the scene and orientation adjustments, AP-VLM allows a robotic manipulator to intelligently select optimal viewpoints and orientations to resolve challenging tasks, such as identifying objects in occluded or inclined positions. We evaluate our system on two robotic platforms: a 7-DOF Franka Panda and a 6-DOF UR5, across various scenes with differing object configurations. Our results demonstrate that AP-VLM significantly outperforms passive perception methods and baseline models, including Toward Grounded Common Sense Reasoning (TGCSR), particularly in scenarios where fixed camera views are inadequate. The adaptability of AP-VLM in real-world settings shows promise for enhancing robotic systems' understanding of complex environments, bridging the gap between high-level semantic reasoning and low-level control.
DEAR: Depth-Enhanced Action Recognition
Aug 28, 2024

Detecting actions in videos, particularly within cluttered scenes, poses significant challenges due to the limitations of 2D frame analysis from a camera perspective. Unlike human vision, which benefits from 3D understanding, recognizing actions in such environments can be difficult. This research introduces a novel approach integrating 3D features and depth maps alongside RGB features to enhance action recognition accuracy. Our method involves processing estimated depth maps through a separate branch from the RGB feature encoder and fusing the features to understand the scene and actions comprehensively. Using the Side4Video framework and VideoMamba, which employ CLIP and VisionMamba for spatial feature extraction, our approach outperformed our implementation of the Side4Video network on the Something-Something V2 dataset. Our code is available at: https://github.com/SadeghRahmaniB/DEAR
BioMNER: A Dataset for Biomedical Method Entity Recognition
Jun 28, 2024Named entity recognition (NER) stands as a fundamental and pivotal task within the realm of Natural Language Processing. Particularly within the domain of Biomedical Method NER, this task presents notable challenges, stemming from the continual influx of domain-specific terminologies in scholarly literature. Current research in Biomedical Method (BioMethod) NER suffers from a scarcity of resources, primarily attributed to the intricate nature of methodological concepts, which necessitate a profound understanding for precise delineation. In this study, we propose a novel dataset for biomedical method entity recognition, employing an automated BioMethod entity recognition and information retrieval system to assist human annotation. Furthermore, we comprehensively explore a range of conventional and contemporary open-domain NER methodologies, including the utilization of cutting-edge large-scale language models (LLMs) customised to our dataset. Our empirical findings reveal that the large parameter counts of language models surprisingly inhibit the effective assimilation of entity extraction patterns pertaining to biomedical methods. Remarkably, the approach, leveraging the modestly sized ALBERT model (only 11MB), in conjunction with conditional random fields (CRF), achieves state-of-the-art (SOTA) performance.
FILS: Self-Supervised Video Feature Prediction In Semantic Language Space
Jun 05, 2024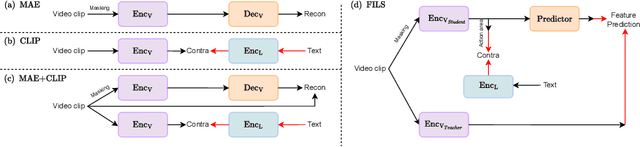
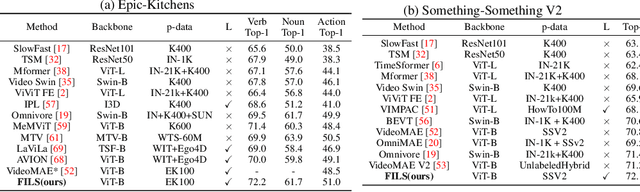
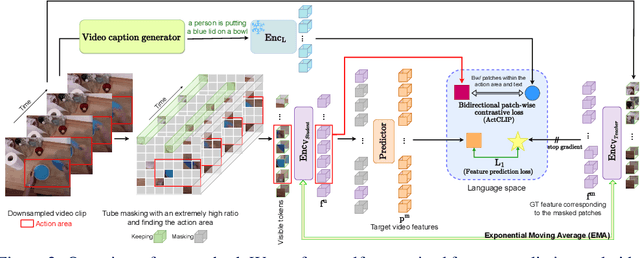
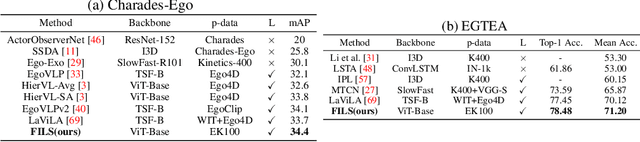
This paper demonstrates a self-supervised approach for learning semantic video representations. Recent vision studies show that a masking strategy for vision and natural language supervision has contributed to developing transferable visual pretraining. Our goal is to achieve a more semantic video representation by leveraging the text related to the video content during the pretraining in a fully self-supervised manner. To this end, we present FILS, a novel self-supervised video Feature prediction In semantic Language Space (FILS). The vision model can capture valuable structured information by correctly predicting masked feature semantics in language space. It is learned using a patch-wise video-text contrastive strategy, in which the text representations act as prototypes for transforming vision features into a language space, which are then used as targets for semantically meaningful feature prediction using our masked encoder-decoder structure. FILS demonstrates remarkable transferability on downstream action recognition tasks, achieving state-of-the-art on challenging egocentric datasets, like Epic-Kitchens, Something-SomethingV2, Charades-Ego, and EGTEA, using ViT-Base. Our efficient method requires less computation and smaller batches compared to previous works.
Evaluating Large Language Models for Generalization and Robustness via Data Compression
Feb 04, 2024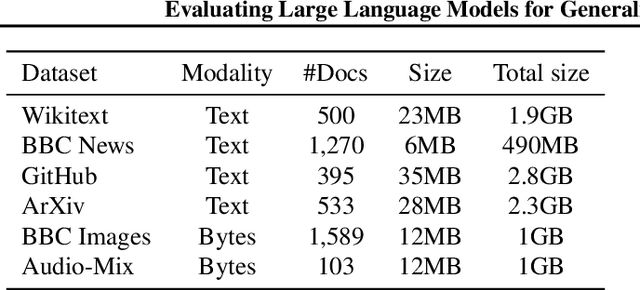
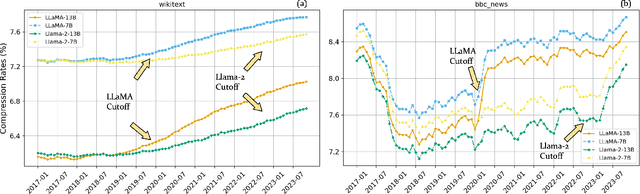
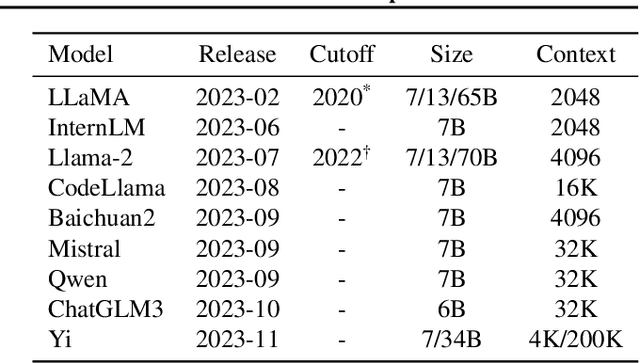
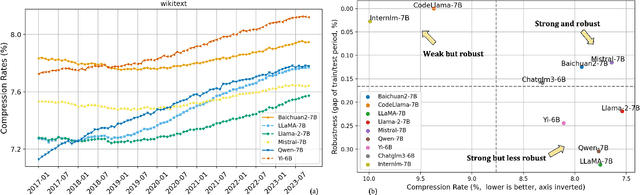
Existing methods for evaluating large language models face challenges such as data contamination, sensitivity to prompts, and the high cost of benchmark creation. To address this, we propose a lossless data compression based evaluation approach that tests how models' predictive abilities generalize after their training cutoff. Specifically, we collect comprehensive test data spanning 83 months from 2017 to 2023 and split the data into training and testing periods according to models' training data cutoff. We measure: 1) the compression performance on the testing period as a measure of generalization on unseen data; and 2) the performance gap between the training and testing period as a measure of robustness. Our experiments test 14 representative large language models with various sizes on sources including Wikipedia, news articles, code, arXiv papers, and multi-modal data. We find that the compression rate of many models reduces significantly after their cutoff date, but models such as Mistral and Llama-2 demonstrate a good balance between performance and robustness. Results also suggest that models struggle to generalize on news and code data, but work especially well on arXiv papers. We also find the context size and tokenization implementation have a big impact of on the overall compression performance.
Finding Challenging Metaphors that Confuse Pretrained Language Models
Jan 29, 2024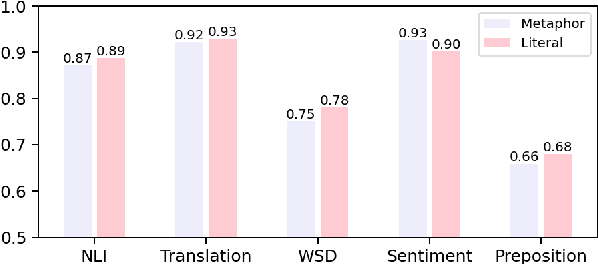

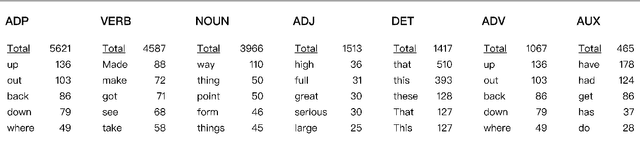
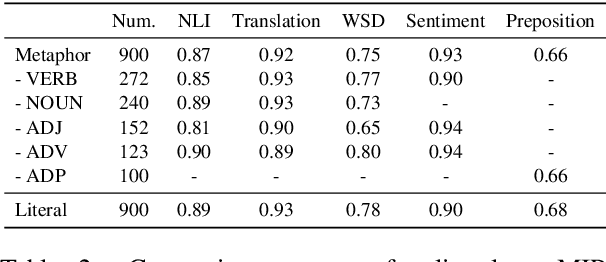
Metaphors are considered to pose challenges for a wide spectrum of NLP tasks. This gives rise to the area of computational metaphor processing. However, it remains unclear what types of metaphors challenge current state-of-the-art models. In this paper, we test various NLP models on the VUA metaphor dataset and quantify to what extent metaphors affect models' performance on various downstream tasks. Analysis reveals that VUA includes a large number of metaphors that pose little difficulty to downstream tasks. We would like to shift the attention of researchers away from these metaphors to instead focus on challenging metaphors. To identify hard metaphors, we propose an automatic pipeline that identifies metaphors that challenge a particular model. Our analysis demonstrates that our detected hard metaphors contrast significantly with VUA and reduce the accuracy of machine translation by 16\%, QA performance by 4\%, NLI by 7\%, and metaphor identification recall by over 14\% for various popular NLP systems.
LatestEval: Addressing Data Contamination in Language Model Evaluation through Dynamic and Time-Sensitive Test Construction
Dec 26, 2023



Data contamination in evaluation is getting increasingly prevalent with the emergence of language models pre-trained on super large, automatically crawled corpora. This problem leads to significant challenges in the accurate assessment of model capabilities and generalisations. In this paper, we propose LatestEval, an automatic method that leverages the most recent texts to create uncontaminated reading comprehension evaluations. LatestEval avoids data contamination by only using texts published within a recent time window, ensuring no overlap with the training corpora of pre-trained language models. We develop the LatestEval automated pipeline to 1) gather the latest texts; 2) identify key information, and 3) construct questions targeting the information while removing the existing answers from the context. This encourages models to infer the answers themselves based on the remaining context, rather than just copy-paste. Our experiments demonstrate that language models exhibit negligible memorisation behaviours on LatestEval as opposed to previous benchmarks, suggesting a significantly reduced risk of data contamination and leading to a more robust evaluation. Data and code are publicly available at: https://github.com/liyucheng09/LatestEval.
ACL Anthology Helper: A Tool to Retrieve and Manage Literature from ACL Anthology
Oct 31, 2023
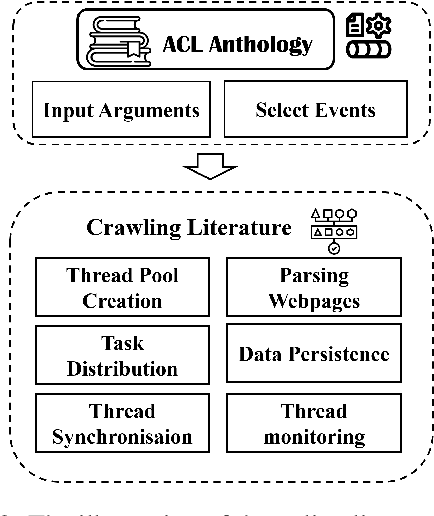
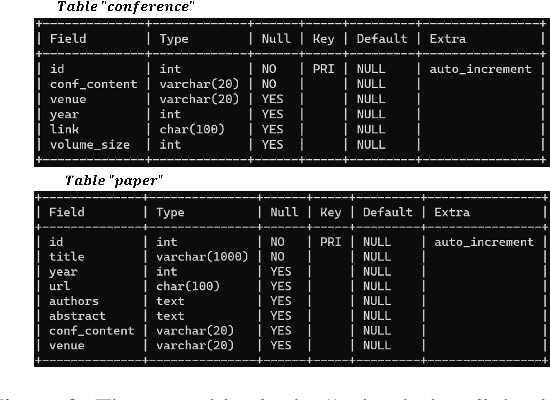
The ACL Anthology is an online repository that serves as a comprehensive collection of publications in the field of natural language processing (NLP) and computational linguistics (CL). This paper presents a tool called ``ACL Anthology Helper''. It automates the process of parsing and downloading papers along with their meta-information, which are then stored in a local MySQL database. This allows for efficient management of the local papers using a wide range of operations, including "where," "group," "order," and more. By providing over 20 operations, this tool significantly enhances the retrieval of literature based on specific conditions. Notably, this tool has been successfully utilised in writing a survey paper (Tang et al.,2022a). By introducing the ACL Anthology Helper, we aim to enhance researchers' ability to effectively access and organise literature from the ACL Anthology. This tool offers a convenient solution for researchers seeking to explore the ACL Anthology's vast collection of publications while allowing for more targeted and efficient literature retrieval.