 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Divergence in Ego-centric Action Recognition under Spatial and Spatiotemporal Manipulations
Mar 09, 2026Humans consistently outperform state-of-the-art AI models in action recognition, particularly in challenging real-world conditions involving low resolution, occlusion, and visual clutter. Understanding the sources of this performance gap is essential for developing more robust and human-aligned models. In this paper, we present a large-scale human-AI comparative study of egocentric action recognition using Minimal Identifiable Recognition Crops (MIRCs), defined as the smallest spatial or spatiotemporal regions sufficient for reliable human recognition. We used our previously introduced, Epic ReduAct, a systematically spatially reduced and temporally scrambled dataset derived from 36 EPIC KITCHENS videos, spanning multiple spatial reduction levels and temporal conditions. Recognition performance is evaluated using over 3,000 human participants and the Side4Video model. Our analysis combines quantitative metrics, Average Reduction Rate and Recognition Gap, with qualitative analyses of spatial (high-, mid-, and low-level visual features) and spatiotemporal factors, including a categorisation of actions into Low Temporal Actions (LTA) and High Temporal Actions (HTA). Results show that human performance exhibits sharp declines when transitioning from MIRCs to subMIRCs, reflecting a strong reliance on sparse, semantically critical cues such as hand-object interactions. In contrast, the model degrades more gradually and often relies on contextual and mid- to low-level features, sometimes even exhibiting increased confidence under spatial reduction. Temporally, humans remain robust to scrambling when key spatial cues are preserved, whereas the model often shows insensitivity to temporal disruption, revealing class-dependent temporal sensitivities.
MultiNeRF: Multiple Watermark Embedding for Neural Radiance Fields
Apr 03, 2025We present MultiNeRF, a 3D watermarking method that embeds multiple uniquely keyed watermarks within images rendered by a single Neural Radiance Field (NeRF) model, whilst maintaining high visual quality. Our approach extends the TensoRF NeRF model by incorporating a dedicated watermark grid alongside the existing geometry and appearance grids. This extension ensures higher watermark capacity without entangling watermark signals with scene content. We propose a FiLM-based conditional modulation mechanism that dynamically activates watermarks based on input identifiers, allowing multiple independent watermarks to be embedded and extracted without requiring model retraining. MultiNeRF is validated on the NeRF-Synthetic and LLFF datasets, with statistically significant improvements in robust capacity without compromising rendering quality. By generalizing single-watermark NeRF methods into a flexible multi-watermarking framework, MultiNeRF provides a scalable solution for 3D content. attribution.
DANTE-AD: Dual-Vision Attention Network for Long-Term Audio Description
Mar 31, 2025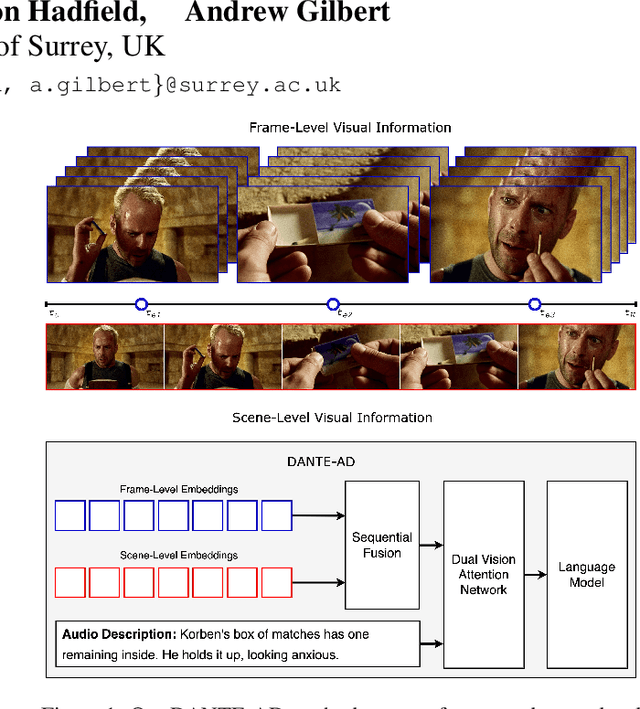
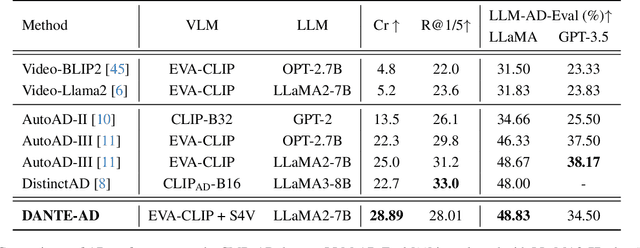
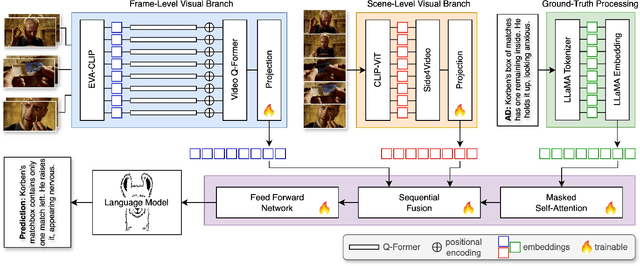
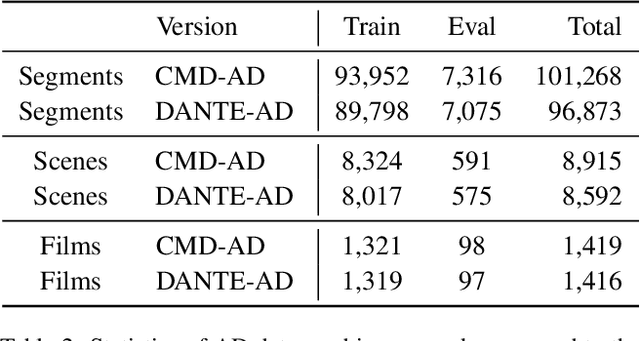
Audio Description is a narrated commentary designed to aid vision-impaired audiences in perceiving key visual elements in a video. While short-form video understanding has advanced rapidly, a solution for maintaining coherent long-term visual storytelling remains unresolved. Existing methods rely solely on frame-level embeddings, effectively describing object-based content but lacking contextual information across scenes. We introduce DANTE-AD, an enhanced video description model leveraging a dual-vision Transformer-based architecture to address this gap. DANTE-AD sequentially fuses both frame and scene level embeddings to improve long-term contextual understanding. We propose a novel, state-of-the-art method for sequential cross-attention to achieve contextual grounding for fine-grained audio description generation. Evaluated on a broad range of key scenes from well-known movie clips, DANTE-AD outperforms existing methods across traditional NLP metrics and LLM-based evaluations.
Multitwine: Multi-Object Compositing with Text and Layout Control
Feb 07, 2025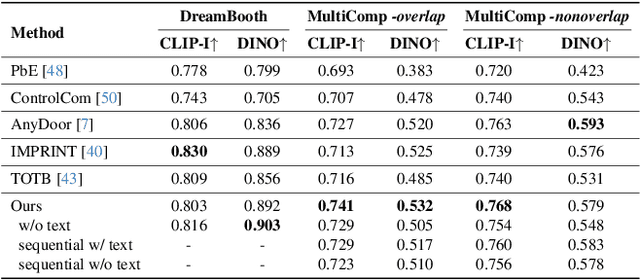



We introduce the first generative model capable of simultaneous multi-object compositing, guided by both text and layout. Our model allows for the addition of multiple objects within a scene, capturing a range of interactions from simple positional relations (e.g., next to, in front of) to complex actions requiring reposing (e.g., hugging, playing guitar). When an interaction implies additional props, like `taking a selfie', our model autonomously generates these supporting objects. By jointly training for compositing and subject-driven generation, also known as customization, we achieve a more balanced integration of textual and visual inputs for text-driven object compositing. As a result, we obtain a versatile model with state-of-the-art performance in both tasks. We further present a data generation pipeline leveraging visual and language models to effortlessly synthesize multimodal, aligned training data.
Boosting Camera Motion Control for Video Diffusion Transformers
Oct 14, 2024



Recent advancements in diffusion models have significantly enhanced the quality of video generation. However, fine-grained control over camera pose remains a challenge. While U-Net-based models have shown promising results for camera control, transformer-based diffusion models (DiT)-the preferred architecture for large-scale video generation - suffer from severe degradation in camera motion accuracy. In this paper, we investigate the underlying causes of this issue and propose solutions tailored to DiT architectures. Our study reveals that camera control performance depends heavily on the choice of conditioning methods rather than camera pose representations that is commonly believed. To address the persistent motion degradation in DiT, we introduce Camera Motion Guidance (CMG), based on classifier-free guidance, which boosts camera control by over 400%. Additionally, we present a sparse camera control pipeline, significantly simplifying the process of specifying camera poses for long videos. Our method universally applies to both U-Net and DiT models, offering improved camera control for video generation tasks.
PDFed: Privacy-Preserving and Decentralized Asynchronous Federated Learning for Diffusion Models
Sep 26, 2024
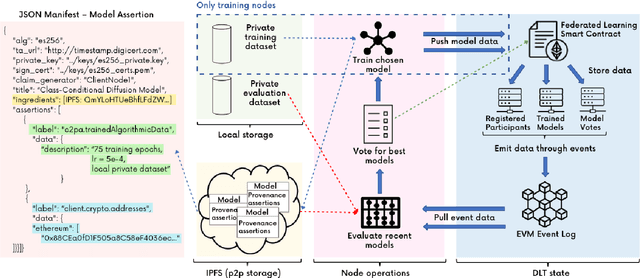
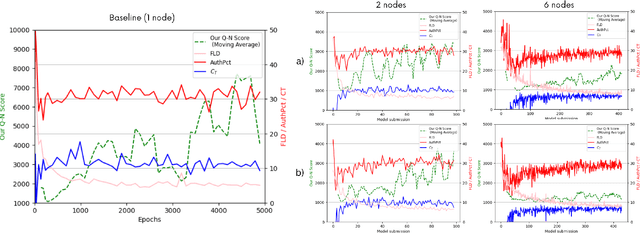

We present PDFed, a decentralized, aggregator-free, and asynchronous federated learning protocol for training image diffusion models using a public blockchain. In general, diffusion models are prone to memorization of training data, raising privacy and ethical concerns (e.g., regurgitation of private training data in generated images). Federated learning (FL) offers a partial solution via collaborative model training across distributed nodes that safeguard local data privacy. PDFed proposes a novel sample-based score that measures the novelty and quality of generated samples, incorporating these into a blockchain-based federated learning protocol that we show reduces private data memorization in the collaboratively trained model. In addition, PDFed enables asynchronous collaboration among participants with varying hardware capabilities, facilitating broader participation. The protocol records the provenance of AI models, improving transparency and auditability, while also considering automated incentive and reward mechanisms for participants. PDFed aims to empower artists and creators by protecting the privacy of creative works and enabling decentralized, peer-to-peer collaboration. The protocol positively impacts the creative economy by opening up novel revenue streams and fostering innovative ways for artists to benefit from their contributions to the AI space.
Thinking Outside the BBox: Unconstrained Generative Object Compositing
Sep 11, 2024Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
DEAR: Depth-Enhanced Action Recognition
Aug 28, 2024

Detecting actions in videos, particularly within cluttered scenes, poses significant challenges due to the limitations of 2D frame analysis from a camera perspective. Unlike human vision, which benefits from 3D understanding, recognizing actions in such environments can be difficult. This research introduces a novel approach integrating 3D features and depth maps alongside RGB features to enhance action recognition accuracy. Our method involves processing estimated depth maps through a separate branch from the RGB feature encoder and fusing the features to understand the scene and actions comprehensively. Using the Side4Video framework and VideoMamba, which employ CLIP and VisionMamba for spatial feature extraction, our approach outperformed our implementation of the Side4Video network on the Something-Something V2 dataset. Our code is available at: https://github.com/SadeghRahmaniB/DEAR
Interpretable Long-term Action Quality Assessment
Aug 21, 2024Long-term Action Quality Assessment (AQA) evaluates the execution of activities in videos. However, the length presents challenges in fine-grained interpretability, with current AQA methods typically producing a single score by averaging clip features, lacking detailed semantic meanings of individual clips. Long-term videos pose additional difficulty due to the complexity and diversity of actions, exacerbating interpretability challenges. While query-based transformer networks offer promising long-term modeling capabilities, their interpretability in AQA remains unsatisfactory due to a phenomenon we term Temporal Skipping, where the model skips self-attention layers to prevent output degradation. To address this, we propose an attention loss function and a query initialization method to enhance performance and interpretability. Additionally, we introduce a weight-score regression module designed to approximate the scoring patterns observed in human judgments and replace conventional single-score regression, improving the rationality of interpretability. Our approach achieves state-of-the-art results on three real-world, long-term AQA benchmarks. Our code is available at: https://github.com/dx199771/Interpretability-AQA
FILS: Self-Supervised Video Feature Prediction In Semantic Language Space
Jun 05, 2024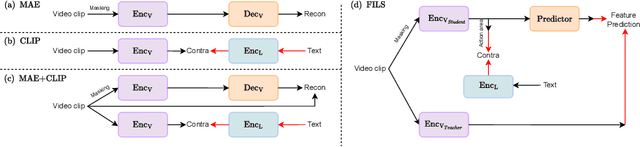
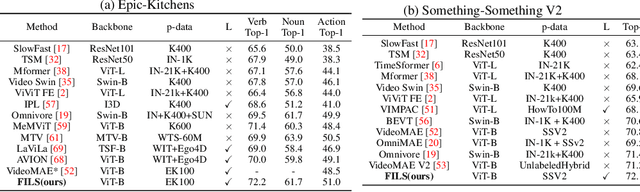
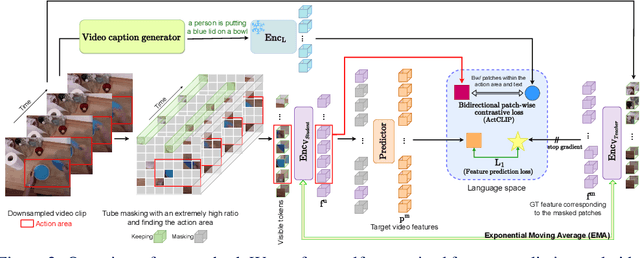
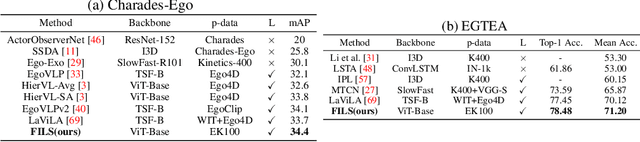
This paper demonstrates a self-supervised approach for learning semantic video representations. Recent vision studies show that a masking strategy for vision and natural language supervision has contributed to developing transferable visual pretraining. Our goal is to achieve a more semantic video representation by leveraging the text related to the video content during the pretraining in a fully self-supervised manner. To this end, we present FILS, a novel self-supervised video Feature prediction In semantic Language Space (FILS). The vision model can capture valuable structured information by correctly predicting masked feature semantics in language space. It is learned using a patch-wise video-text contrastive strategy, in which the text representations act as prototypes for transforming vision features into a language space, which are then used as targets for semantically meaningful feature prediction using our masked encoder-decoder structure. FILS demonstrates remarkable transferability on downstream action recognition tasks, achieving state-of-the-art on challenging egocentric datasets, like Epic-Kitchens, Something-SomethingV2, Charades-Ego, and EGTEA, using ViT-Base. Our efficient method requires less computation and smaller batches compared to previous works.