 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLACID: Identity-Preserving Multi-Object Compositing via Video Diffusion with Synthetic Trajectories
Jan 30, 2026Recent advances in generative AI have dramatically improved photorealistic image synthesis, yet they fall short for studio-level multi-object compositing. This task demands simultaneous (i) near-perfect preservation of each item's identity, (ii) precise background and color fidelity, (iii) layout and design elements control, and (iv) complete, appealing displays showcasing all objects. However, current state-of-the-art models often alter object details, omit or duplicate objects, and produce layouts with incorrect relative sizing or inconsistent item presentations. To bridge this gap, we introduce PLACID, a framework that transforms a collection of object images into an appealing multi-object composite. Our approach makes two main contributions. First, we leverage a pretrained image-to-video (I2V) diffusion model with text control to preserve objects consistency, identities, and background details by exploiting temporal priors from videos. Second, we propose a novel data curation strategy that generates synthetic sequences where randomly placed objects smoothly move to their target positions. This synthetic data aligns with the video model's temporal priors during training. At inference, objects initialized at random positions consistently converge into coherent layouts guided by text, with the final frame serving as the composite image. Extensive quantitative evaluations and user studies demonstrate that PLACID surpasses state-of-the-art methods in multi-object compositing, achieving superior identity, background, and color preservation, with less omitted objects and visually appealing results.
Multitwine: Multi-Object Compositing with Text and Layout Control
Feb 07, 2025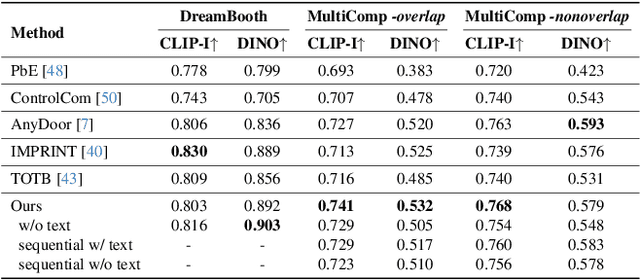



We introduce the first generative model capable of simultaneous multi-object compositing, guided by both text and layout. Our model allows for the addition of multiple objects within a scene, capturing a range of interactions from simple positional relations (e.g., next to, in front of) to complex actions requiring reposing (e.g., hugging, playing guitar). When an interaction implies additional props, like `taking a selfie', our model autonomously generates these supporting objects. By jointly training for compositing and subject-driven generation, also known as customization, we achieve a more balanced integration of textual and visual inputs for text-driven object compositing. As a result, we obtain a versatile model with state-of-the-art performance in both tasks. We further present a data generation pipeline leveraging visual and language models to effortlessly synthesize multimodal, aligned training data.
Thinking Outside the BBox: Unconstrained Generative Object Compositing
Sep 11, 2024Compositing an object into an image involves multiple non-trivial sub-tasks such as object placement and scaling, color/lighting harmonization, viewpoint/geometry adjustment, and shadow/reflection generation. Recent generative image compositing methods leverage diffusion models to handle multiple sub-tasks at once. However, existing models face limitations due to their reliance on masking the original object during training, which constrains their generation to the input mask. Furthermore, obtaining an accurate input mask specifying the location and scale of the object in a new image can be highly challenging. To overcome such limitations, we define a novel problem of unconstrained generative object compositing, i.e., the generation is not bounded by the mask, and train a diffusion-based model on a synthesized paired dataset. Our first-of-its-kind model is able to generate object effects such as shadows and reflections that go beyond the mask, enhancing image realism. Additionally, if an empty mask is provided, our model automatically places the object in diverse natural locations and scales, accelerating the compositing workflow. Our model outperforms existing object placement and compositing models in various quality metrics and user studies.
DIFF-NST: Diffusion Interleaving For deFormable Neural Style Transfer
Jul 11, 2023
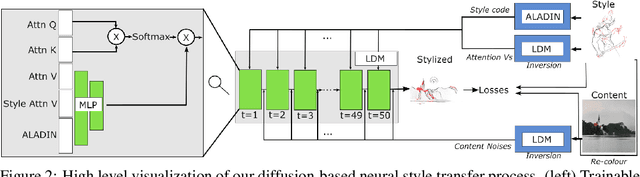


Neural Style Transfer (NST) is the field of study applying neural techniques to modify the artistic appearance of a content image to match the style of a reference style image. Traditionally, NST methods have focused on texture-based image edits, affecting mostly low level information and keeping most image structures the same. However, style-based deformation of the content is desirable for some styles, especially in cases where the style is abstract or the primary concept of the style is in its deformed rendition of some content. With the recent introduction of diffusion models, such as Stable Diffusion, we can access far more powerful image generation techniques, enabling new possibilities. In our work, we propose using this new class of models to perform style transfer while enabling deformable style transfer, an elusive capability in previous models. We show how leveraging the priors of these models can expose new artistic controls at inference time, and we document our findings in exploring this new direction for the field of style transfer.
PARASOL: Parametric Style Control for Diffusion Image Synthesis
Mar 27, 2023We propose PARASOL, a multi-modal synthesis model that enables disentangled, parametric control of the visual style of the image by jointly conditioning synthesis on both content and a fine-grained visual style embedding. We train a latent diffusion model (LDM) using specific losses for each modality and adapt the classifier-free guidance for encouraging disentangled control over independent content and style modalities at inference time. We leverage auxiliary semantic and style-based search to create training triplets for supervision of the LDM, ensuring complementarity of content and style cues. PARASOL shows promise for enabling nuanced control over visual style in diffusion models for image creation and stylization, as well as generative search where text-based search results may be adapted to more closely match user intent by interpolating both content and style descriptors.