 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitwine: Multi-Object Compositing with Text and Layout Control
Paper and Code
Feb 07, 2025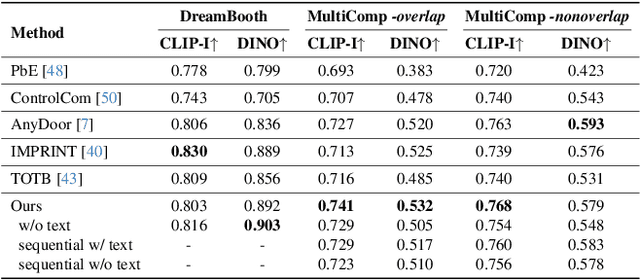



We introduce the first generative model capable of simultaneous multi-object compositing, guided by both text and layout. Our model allows for the addition of multiple objects within a scene, capturing a range of interactions from simple positional relations (e.g., next to, in front of) to complex actions requiring reposing (e.g., hugging, playing guitar). When an interaction implies additional props, like `taking a selfie', our model autonomously generates these supporting objects. By jointly training for compositing and subject-driven generation, also known as customization, we achieve a more balanced integration of textual and visual inputs for text-driven object compositing. As a result, we obtain a versatile model with state-of-the-art performance in both tasks. We further present a data generation pipeline leveraging visual and language models to effortlessly synthesize multimodal, aligned training data.