 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-Sim: An Identity-Focused Similarity Metric
Apr 06, 2026Humans have remarkable selective sensitivity to identities -- easily distinguishing between highly similar identities, even across significantly different contexts such as diverse viewpoints or lighting. Vision models have struggled to match this capability, and progress toward identity-focused tasks such as personalized image generation is slowed by a lack of identity-focused evaluation metrics. To help facilitate progress, we propose ID-Sim, a feed-forward metric designed to faithfully reflect human selective sensitivity. To build ID-Sim, we curate a high-quality training set of images spanning diverse real-world domains, augmented with generative synthetic data that provides controlled, fine-grained identity and contextual variations. We evaluate our metric on a new unified evaluation benchmark for assessing consistency with human annotations across identity-focused recognition, retrieval, and generative tasks.
Relational Visual Similarity
Dec 08, 2025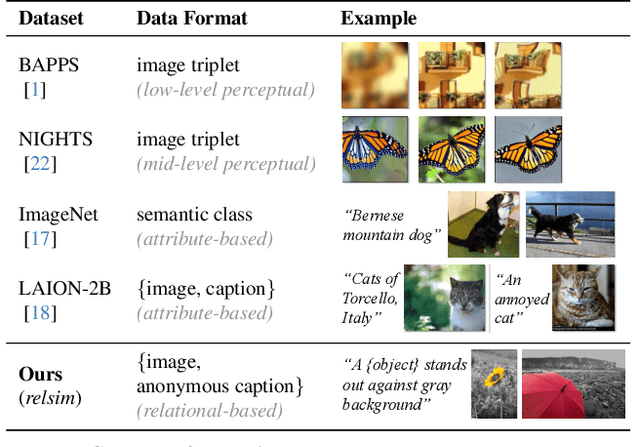
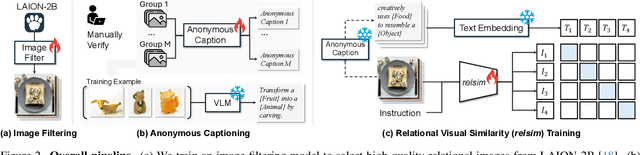
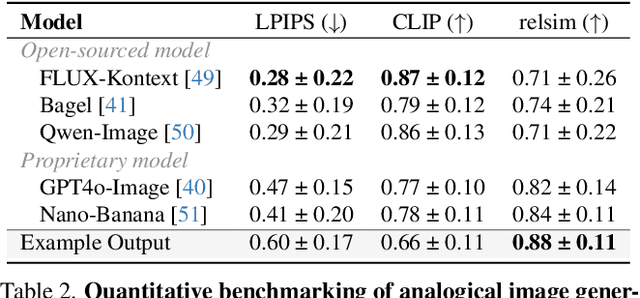

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
TurboEdit: Instant text-based image editing
Aug 14, 2024
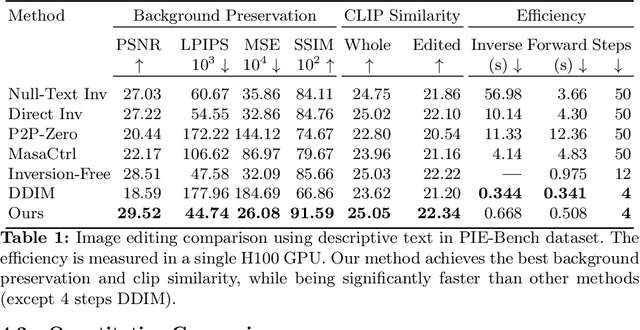
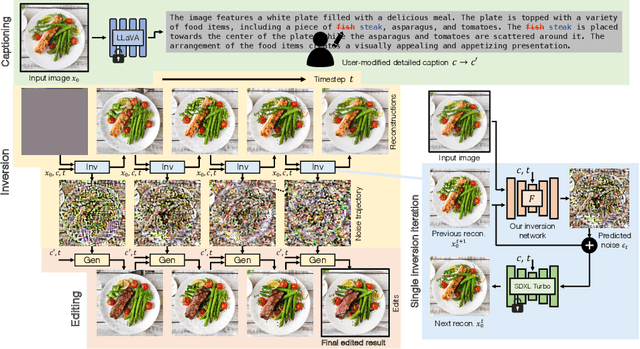

We address the challenges of precise image inversion and disentangled image editing in the context of few-step diffusion models. We introduce an encoder based iterative inversion technique. The inversion network is conditioned on the input image and the reconstructed image from the previous step, allowing for correction of the next reconstruction towards the input image. We demonstrate that disentangled controls can be easily achieved in the few-step diffusion model by conditioning on an (automatically generated) detailed text prompt. To manipulate the inverted image, we freeze the noise maps and modify one attribute in the text prompt (either manually or via instruction based editing driven by an LLM), resulting in the generation of a new image similar to the input image with only one attribute changed. It can further control the editing strength and accept instructive text prompt. Our approach facilitates realistic text-guided image edits in real-time, requiring only 8 number of functional evaluations (NFEs) in inversion (one-time cost) and 4 NFEs per edit. Our method is not only fast, but also significantly outperforms state-of-the-art multi-step diffusion editing techniques.
Personalized Residuals for Concept-Driven Text-to-Image Generation
May 21, 2024
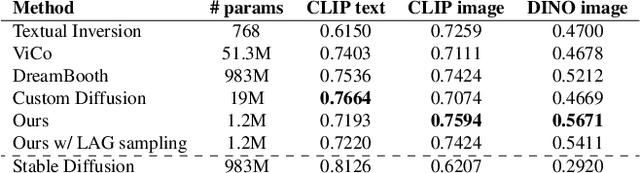
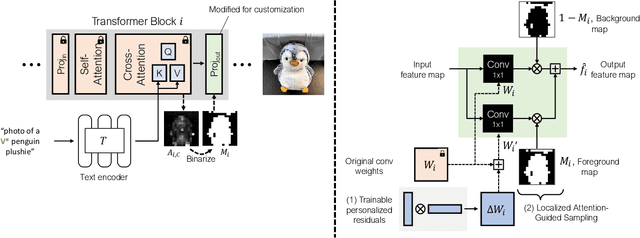
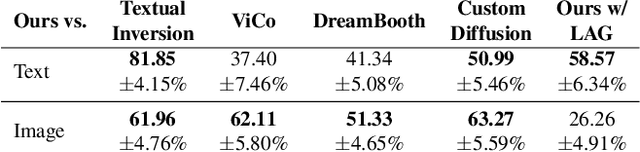
We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model's layers. The residual-based approach then directly enables application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions. Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image.
Generative Models: What do they know? Do they know things? Let's find out!
Nov 28, 2023Generative models have been shown to be capable of synthesizing highly detailed and realistic images. It is natural to suspect that they implicitly learn to model some image intrinsics such as surface normals, depth, or shadows. In this paper, we present compelling evidence that generative models indeed internally produce high-quality scene intrinsic maps. We introduce Intrinsic LoRA (I LoRA), a universal, plug-and-play approach that transforms any generative model into a scene intrinsic predictor, capable of extracting intrinsic scene maps directly from the original generator network without needing additional decoders or fully fine-tuning the original network. Our method employs a Low-Rank Adaptation (LoRA) of key feature maps, with newly learned parameters that make up less than 0.6% of the total parameters in the generative model. Optimized with a small set of labeled images, our model-agnostic approach adapts to various generative architectures, including Diffusion models, GANs, and Autoregressive models. We show that the scene intrinsic maps produced by our method compare well with, and in some cases surpass those generated by leading supervised techniques.
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023
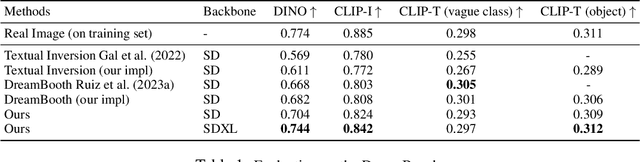

Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.
DIFF-NST: Diffusion Interleaving For deFormable Neural Style Transfer
Jul 11, 2023
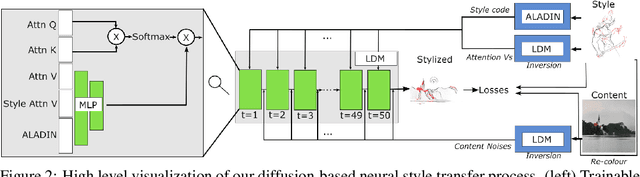


Neural Style Transfer (NST) is the field of study applying neural techniques to modify the artistic appearance of a content image to match the style of a reference style image. Traditionally, NST methods have focused on texture-based image edits, affecting mostly low level information and keeping most image structures the same. However, style-based deformation of the content is desirable for some styles, especially in cases where the style is abstract or the primary concept of the style is in its deformed rendition of some content. With the recent introduction of diffusion models, such as Stable Diffusion, we can access far more powerful image generation techniques, enabling new possibilities. In our work, we propose using this new class of models to perform style transfer while enabling deformable style transfer, an elusive capability in previous models. We show how leveraging the priors of these models can expose new artistic controls at inference time, and we document our findings in exploring this new direction for the field of style transfer.
NeAT: Neural Artistic Tracing for Beautiful Style Transfer
Apr 11, 2023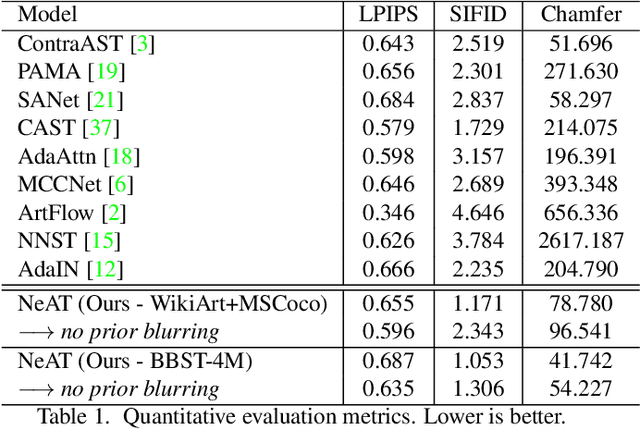
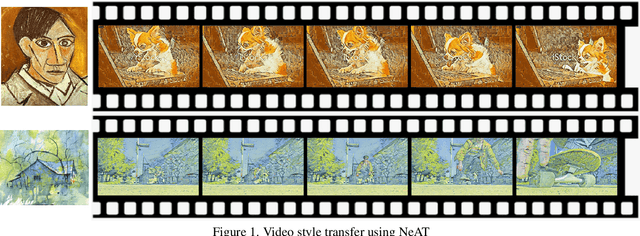
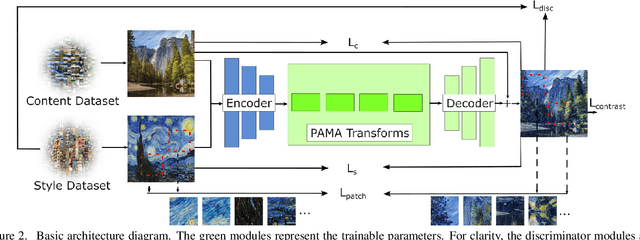
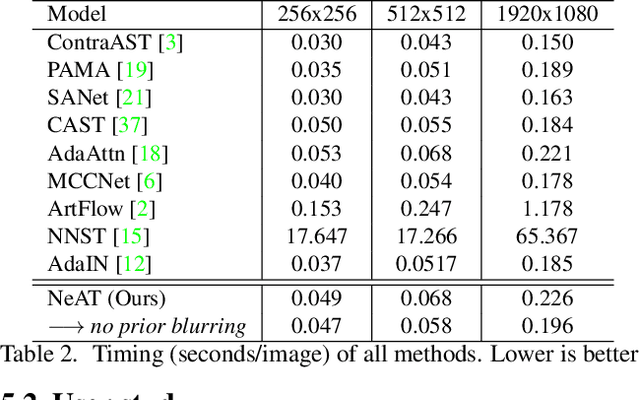
Style transfer is the task of reproducing the semantic contents of a source image in the artistic style of a second target image. In this paper, we present NeAT, a new state-of-the art feed-forward style transfer method. We re-formulate feed-forward style transfer as image editing, rather than image generation, resulting in a model which improves over the state-of-the-art in both preserving the source content and matching the target style. An important component of our model's success is identifying and fixing "style halos", a commonly occurring artefact across many style transfer techniques. In addition to training and testing on standard datasets, we introduce the BBST-4M dataset, a new, large scale, high resolution dataset of 4M images. As a component of curating this data, we present a novel model able to classify if an image is stylistic. We use BBST-4M to improve and measure the generalization of NeAT across a huge variety of styles. Not only does NeAT offer state-of-the-art quality and generalization, it is designed and trained for fast inference at high resolution.
Text-Free Learning of a Natural Language Interface for Pretrained Face Generators
Sep 08, 2022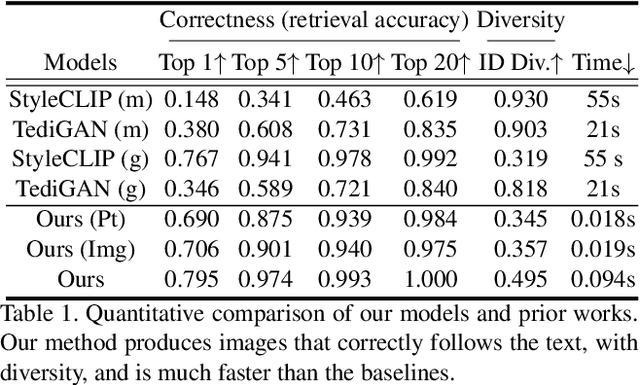
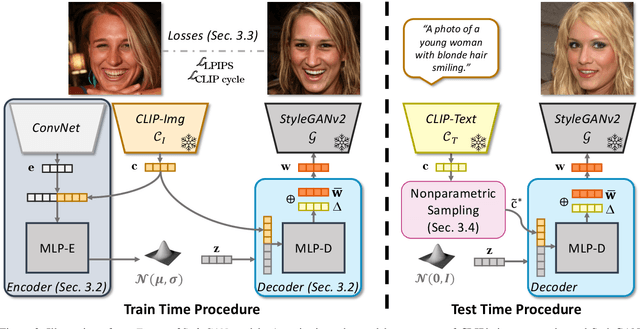
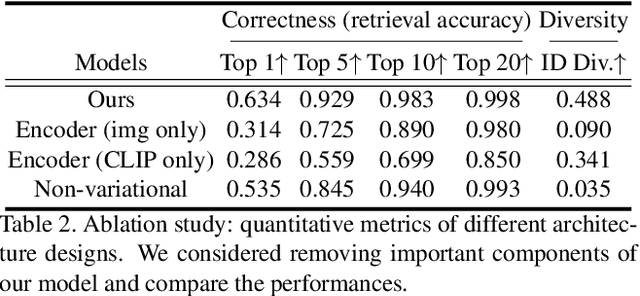

We propose Fast text2StyleGAN, a natural language interface that adapts pre-trained GANs for text-guided human face synthesis. Leveraging the recent advances in Contrastive Language-Image Pre-training (CLIP), no text data is required during training. Fast text2StyleGAN is formulated as a conditional variational autoencoder (CVAE) that provides extra control and diversity to the generated images at test time. Our model does not require re-training or fine-tuning of the GANs or CLIP when encountering new text prompts. In contrast to prior work, we do not rely on optimization at test time, making our method orders of magnitude faster than prior work. Empirically, on FFHQ dataset, our method offers faster and more accurate generation of images from natural language descriptions with varying levels of detail compared to prior work.
Neural Neighbor Style Transfer
Mar 24, 2022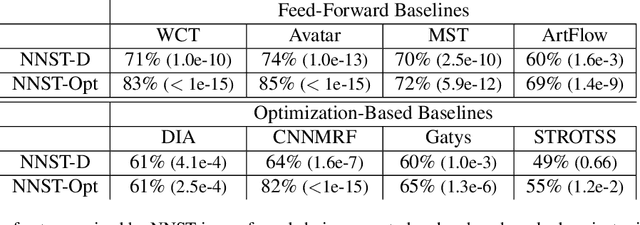
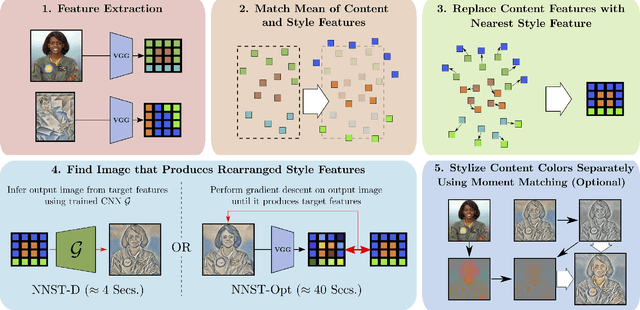


We propose Neural Neighbor Style Transfer (NNST), a pipeline that offers state-of-the-art quality, generalization, and competitive efficiency for artistic style transfer. Our approach is based on explicitly replacing neural features extracted from the content input (to be stylized) with those from a style exemplar, then synthesizing the final output based on these rearranged features. While the spirit of our approach is similar to prior work, we show that our design decisions dramatically improve the final visual quality.