 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Zero: Self-Evolving Multi-Model Vision Language Models From Zero Data
Mar 10, 2026Self-evolving has emerged as a key paradigm for improving foundational models such as Large Language Models (LLMs) and Vision Language Models (VLMs) with minimal human intervention. While recent approaches have demonstrated that LLM agents can self-evolve from scratch with little to no data, VLMs introduce an additional visual modality that typically requires at least some seed data, such as images, to bootstrap the self-evolution process. In this work, we present Multi-model Multimodal Zero (MM-Zero), the first RL-based framework to achieve zero-data self-evolution for VLM reasoning. Moving beyond prior dual-role (Proposer and Solver) setups, MM-Zero introduces a multi-role self-evolving training framework comprising three specialized roles: a Proposer that generates abstract visual concepts and formulates questions; a Coder that translates these concepts into executable code (e.g., Python, SVG) to render visual images; and a Solver that performs multimodal reasoning over the generated visual content. All three roles are initialized from the same base model and trained using Group Relative Policy Optimization (GRPO), with carefully designed reward mechanisms that integrate execution feedback, visual verification, and difficulty balancing. Our experiments show that MM-Zero improves VLM reasoning performance across a wide range of multimodal benchmarks. MM-Zero establishes a scalable path toward self-evolving multi-model systems for multimodal models, extending the frontier of self-improvement beyond the conventional two-model paradigm.
Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
Dec 13, 2024



We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.
Isotropic Gaussian Splatting for Real-Time Radiance Field Rendering
Mar 21, 2024



The 3D Gaussian splatting method has drawn a lot of attention, thanks to its high performance in training and high quality of the rendered image. However, it uses anisotropic Gaussian kernels to represent the scene. Although such anisotropic kernels have advantages in representing the geometry, they lead to difficulties in terms of computation, such as splitting or merging two kernels. In this paper, we propose to use isotropic Gaussian kernels to avoid such difficulties in the computation, leading to a higher performance method. The experiments confirm that the proposed method is about {\bf 100X} faster without losing the geometry representation accuracy. The proposed method can be applied in a large range applications where the radiance field is needed, such as 3D reconstruction, view synthesis, and dynamic object modeling.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023
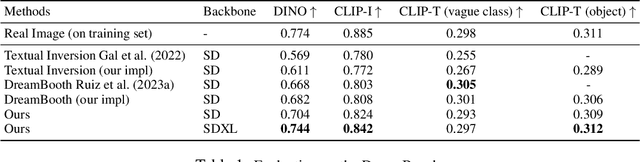

Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.
Offline Imitation Learning with Suboptimal Demonstrations via Relaxed Distribution Matching
Mar 05, 2023


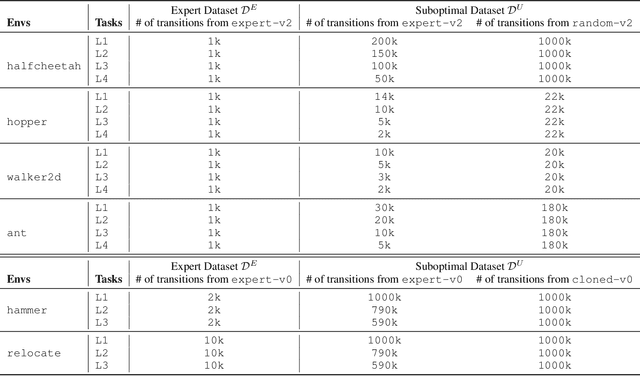
Offline imitation learning (IL) promises the ability to learn performant policies from pre-collected demonstrations without interactions with the environment. However, imitating behaviors fully offline typically requires numerous expert data. To tackle this issue, we study the setting where we have limited expert data and supplementary suboptimal data. In this case, a well-known issue is the distribution shift between the learned policy and the behavior policy that collects the offline data. Prior works mitigate this issue by regularizing the KL divergence between the stationary state-action distributions of the learned policy and the behavior policy. We argue that such constraints based on exact distribution matching can be overly conservative and hamper policy learning, especially when the imperfect offline data is highly suboptimal. To resolve this issue, we present RelaxDICE, which employs an asymmetrically-relaxed f-divergence for explicit support regularization. Specifically, instead of driving the learned policy to exactly match the behavior policy, we impose little penalty whenever the density ratio between their stationary state-action distributions is upper bounded by a constant. Note that such formulation leads to a nested min-max optimization problem, which causes instability in practice. RelaxDICE addresses this challenge by supporting a closed-form solution for the inner maximization problem. Extensive empirical study shows that our method significantly outperforms the best prior offline IL method in six standard continuous control environments with over 30% performance gain on average, across 22 settings where the imperfect dataset is highly suboptimal.
Generalizing Bayesian Optimization with Decision-theoretic Entropies
Oct 04, 2022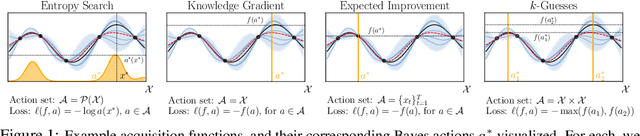
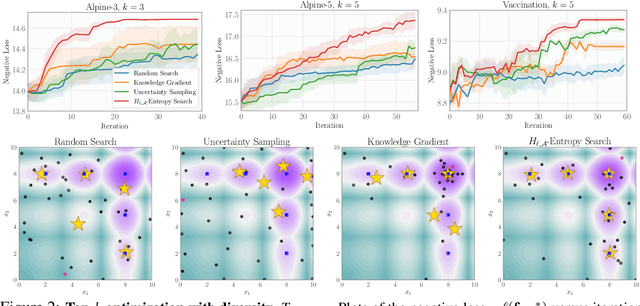
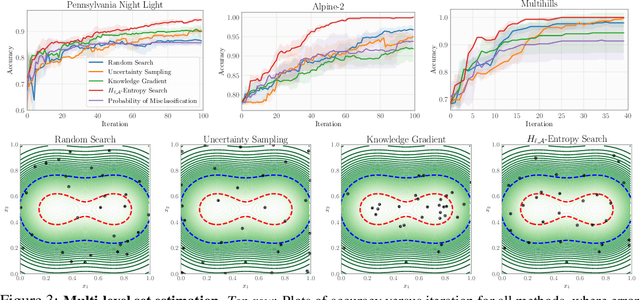
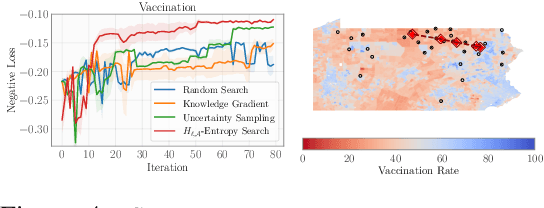
Bayesian optimization (BO) is a popular method for efficiently inferring optima of an expensive black-box function via a sequence of queries. Existing information-theoretic BO procedures aim to make queries that most reduce the uncertainty about optima, where the uncertainty is captured by Shannon entropy. However, an optimal measure of uncertainty would, ideally, factor in how we intend to use the inferred quantity in some downstream procedure. In this paper, we instead consider a generalization of Shannon entropy from work in statistical decision theory (DeGroot 1962, Rao 1984), which contains a broad class of uncertainty measures parameterized by a problem-specific loss function corresponding to a downstream task. We first show that special cases of this entropy lead to popular acquisition functions used in BO procedures such as knowledge gradient, expected improvement, and entropy search. We then show how alternative choices for the loss yield a flexible family of acquisition functions that can be customized for use in novel optimization settings. Additionally, we develop gradient-based methods to efficiently optimize our proposed family of acquisition functions, and demonstrate strong empirical performance on a diverse set of sequential decision making tasks, including variants of top-$k$ optimization, multi-level set estimation, and sequence search.
A General Recipe for Likelihood-free Bayesian Optimization
Jun 27, 2022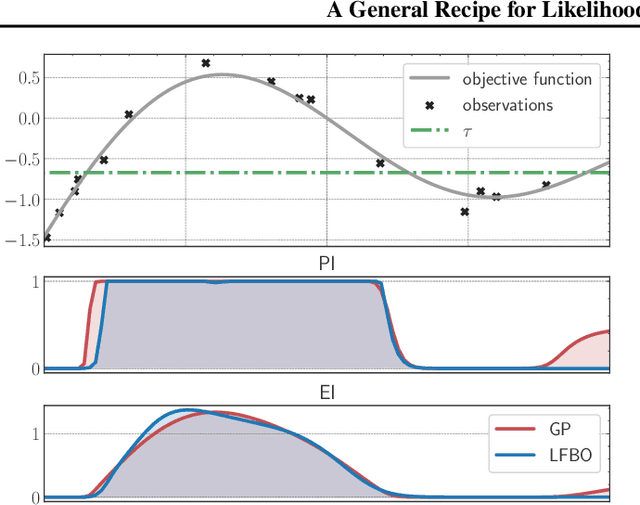

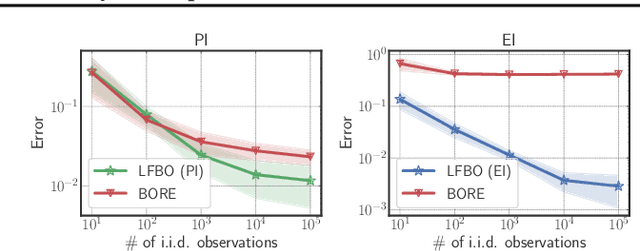
The acquisition function, a critical component in Bayesian optimization (BO), can often be written as the expectation of a utility function under a surrogate model. However, to ensure that acquisition functions are tractable to optimize, restrictions must be placed on the surrogate model and utility function. To extend BO to a broader class of models and utilities, we propose likelihood-free BO (LFBO), an approach based on likelihood-free inference. LFBO directly models the acquisition function without having to separately perform inference with a probabilistic surrogate model. We show that computing the acquisition function in LFBO can be reduced to optimizing a weighted classification problem, where the weights correspond to the utility being chosen. By choosing the utility function for expected improvement (EI), LFBO outperforms various state-of-the-art black-box optimization methods on several real-world optimization problems. LFBO can also effectively leverage composite structures of the objective function, which further improves its regret by several orders of magnitude.
GeoDiff: a Geometric Diffusion Model for Molecular Conformation Generation
Mar 06, 2022
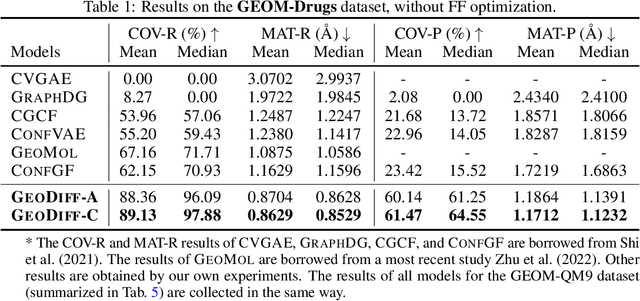
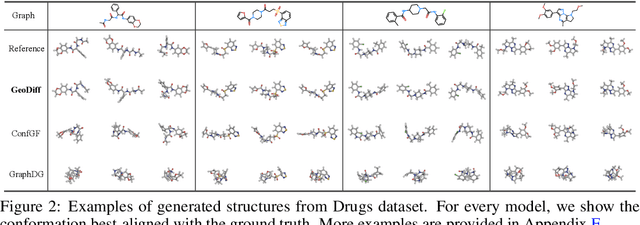

Predicting molecular conformations from molecular graphs is a fundamental problem in cheminformatics and drug discovery. Recently, significant progress has been achieved with machine learning approaches, especially with deep generative models. Inspired by the diffusion process in classical non-equilibrium thermodynamics where heated particles will diffuse from original states to a noise distribution, in this paper, we propose a novel generative model named GeoDiff for molecular conformation prediction. GeoDiff treats each atom as a particle and learns to directly reverse the diffusion process (i.e., transforming from a noise distribution to stable conformations) as a Markov chain. Modeling such a generation process is however very challenging as the likelihood of conformations should be roto-translational invariant. We theoretically show that Markov chains evolving with equivariant Markov kernels can induce an invariant distribution by design, and further propose building blocks for the Markov kernels to preserve the desirable equivariance property. The whole framework can be efficiently trained in an end-to-end fashion by optimizing a weighted variational lower bound to the (conditional) likelihood. Experiments on multiple benchmarks show that GeoDiff is superior or comparable to existing state-of-the-art approaches, especially on large molecules.
A Unified Framework for Multi-distribution Density Ratio Estimation
Dec 07, 2021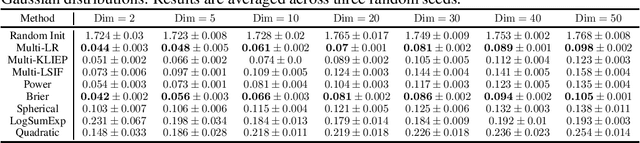
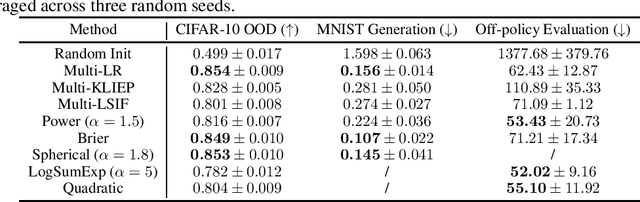
Binary density ratio estimation (DRE), the problem of estimating the ratio $p_1/p_2$ given their empirical samples, provides the foundation for many state-of-the-art machine learning algorithms such as contrastive representation learning and covariate shift adaptation. In this work, we consider a generalized setting where given samples from multiple distributions $p_1, \ldots, p_k$ (for $k > 2$), we aim to efficiently estimate the density ratios between all pairs of distributions. Such a generalization leads to important new applications such as estimating statistical discrepancy among multiple random variables like multi-distribution $f$-divergence, and bias correction via multiple importance sampling. We then develop a general framework from the perspective of Bregman divergence minimization, where each strictly convex multivariate function induces a proper loss for multi-distribution DRE. Moreover, we rederive the theoretical connection between multi-distribution density ratio estimation and class probability estimation, justifying the use of any strictly proper scoring rule composite with a link function for multi-distribution DRE. We show that our framework leads to methods that strictly generalize their counterparts in binary DRE, as well as new methods that show comparable or superior performance on various downstream tasks.