 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodbye Drift: Anchored Tree Sampling for Long-Horizon Video-to-Video Generation
May 19, 2026Long-horizon video generation suffers from two intertwined issues. First, there is drift, where video quality degrades over time. Second, there are continuity issues which manifest as object permanence issues, or improperly rendering transient content (e.g., an object that appears in non-consecutive frames changing color/style). Recent work has focused on autoregressive distillation techniques that attack both problems simultaneously. We instead choose to focus on drift directly and introduce \textbf{Anchored Tree Sampling (ATS)}: a training-free inference-time scheduler that replaces left-to-right rollout with sparse-to-dense, anchor-bounded imputation organized as a tree. A root call produces sparse anchors over the full horizon, recursive refinement generates intermediate anchors, and final leaf spans are synthesized between neighboring anchors. This reduces the critical path from $K$ sequential rollout steps to $L+1$ tree-hierarchical steps and converts horizon-compounding drift into anchor-bounded drift. We focus on V2V generation in the \emph{static-camera} regime, where sparse anchors over the horizon are well approximated by the dense conditioning signal, and the base model can produce them without retraining. We evaluate ATS against two contemporary autoregressive baselines on Wan $2.1$ $+$ VACE, across five conditioning modalities (inpainting, outpainting, edge, pose, depth). We show that ATS outperforms both competitors in overall quality, as well as in drift prevention. We additionally demonstrate stable $\geq 40$-minute generation on LTX-$2.3$ across the same five modalities. We conclude by proposing a path forward to extend ATS to arbitrarily long T2V generation, as well as the dynamic-camera and multi-shot regimes.
PoDAR: Power-Disentangled Audio Representation for Generative Modeling
May 11, 2026The performance of audio latent diffusion models is primarily governed by generator expressivity and the modelability of the underlying latent space. While recent research has focused primarily on the former, as well as improving the reconstruction fidelity of audio codecs, we demonstrate that latent modelability can be significantly improved through explicit factor disentanglement. We present PoDAR (Power-Disentangled Audio Representation), a framework that utilizes a randomized power augmentation and latent consistency objective to decouple signal power from invariant semantic content. This factorization makes the latent space easier to model, which both accelerates the convergence of downstream generative models and improves final overall performance. When applied to a Stable Audio 1.0 VAE with an F5-TTS generator, PoDAR achieves about a $2\times$ acceleration in convergence to match baseline performance, while increasing final speaker similarity by 0.055 and UTMOS by 0.22 on the LibriSpeech-PC dataset. Furthermore, isolating power into dedicated channels enables the application of CFG exclusively to power-invariant content, effectively extending the stable guidance regime to higher scales.
DreamTexture: Shape from Virtual Texture with Analysis by Augmentation
Mar 20, 2025DreamFusion established a new paradigm for unsupervised 3D reconstruction from virtual views by combining advances in generative models and differentiable rendering. However, the underlying multi-view rendering, along with supervision from large-scale generative models, is computationally expensive and under-constrained. We propose DreamTexture, a novel Shape-from-Virtual-Texture approach that leverages monocular depth cues to reconstruct 3D objects. Our method textures an input image by aligning a virtual texture with the real depth cues in the input, exploiting the inherent understanding of monocular geometry encoded in modern diffusion models. We then reconstruct depth from the virtual texture deformation with a new conformal map optimization, which alleviates memory-intensive volumetric representations. Our experiments reveal that generative models possess an understanding of monocular shape cues, which can be extracted by augmenting and aligning texture cues -- a novel monocular reconstruction paradigm that we call Analysis by Augmentation.
Unsupervised Keypoints from Pretrained Diffusion Models
Dec 05, 2023



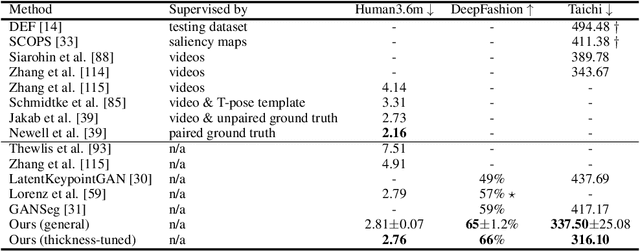
Unsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple datasets: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. Our code is publicly available and can be found through our project page: https://ubc-vision.github.io/StableKeypoints/
A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization
Nov 07, 2023
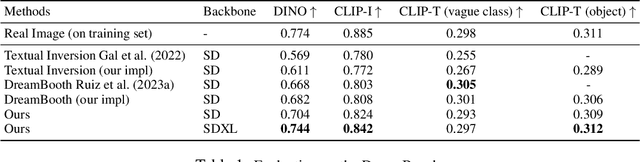

Large text-to-image models have revolutionized the ability to generate imagery using natural language. However, particularly unique or personal visual concepts, such as your pet, an object in your house, etc., will not be captured by the original model. This has led to interest in how to inject new visual concepts, bound to a new text token, using as few as 4-6 examples. Despite significant progress, this task remains a formidable challenge, particularly in preserving the subject's identity. While most researchers attempt to to address this issue by modifying model architectures, our approach takes a data-centric perspective, advocating the modification of data rather than the model itself. We introduce a novel regularization dataset generation strategy on both the text and image level; demonstrating the importance of a rich and structured regularization dataset (automatically generated) to prevent losing text coherence and better identity preservation. The better quality is enabled by allowing up to 5x more fine-tuning iterations without overfitting and degeneration. The generated renditions of the desired subject preserve even fine details such as text and logos; all while maintaining the ability to generate diverse samples that follow the input text prompt. Since our method focuses on data augmentation, rather than adjusting the model architecture, it is complementary and can be combined with prior work. We show on established benchmarks that our data-centric approach forms the new state of the art in terms of image quality, with the best trade-off between identity preservation, diversity, and text alignment.
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023



Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Neural Partial Differential Equations with Functional Convolution
Mar 10, 2023We present a lightweighted neural PDE representation to discover the hidden structure and predict the solution of different nonlinear PDEs. Our key idea is to leverage the prior of ``translational similarity'' of numerical PDE differential operators to drastically reduce the scale of learning model and training data. We implemented three central network components, including a neural functional convolution operator, a Picard forward iterative procedure, and an adjoint backward gradient calculator. Our novel paradigm fully leverages the multifaceted priors that stem from the sparse and smooth nature of the physical PDE solution manifold and the various mature numerical techniques such as adjoint solver, linearization, and iterative procedure to accelerate the computation. We demonstrate the efficacy of our method by robustly discovering the model and accurately predicting the solutions of various types of PDEs with small-scale networks and training sets. We highlight that all the PDE examples we showed were trained with up to 8 data samples and within 325 network parameters.
AutoLink: Self-supervised Learning of Human Skeletons and Object Outlines by Linking Keypoints
May 21, 2022
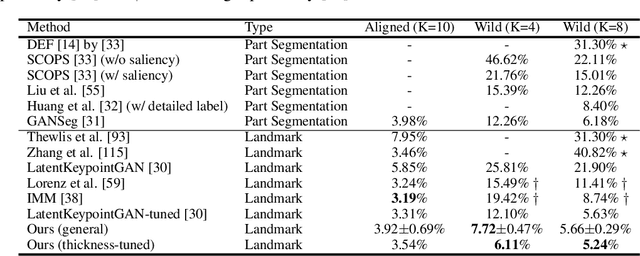
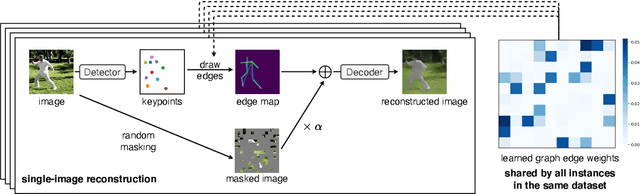
Structured representations such as keypoints are widely used in pose transfer, conditional image generation, animation, and 3D reconstruction. However, their supervised learning requires expensive annotation for each target domain. We propose a self-supervised method that learns to disentangle object structure from the appearance with a graph of 2D keypoints linked by straight edges. Both the keypoint location and their pairwise edge weights are learned, given only a collection of images depicting the same object class. The graph is interpretable, for example, AutoLink recovers the human skeleton topology when applied to images showing people. Our key ingredients are i) an encoder that predicts keypoint locations in an input image, ii) a shared graph as a latent variable that links the same pairs of keypoints in every image, iii) an intermediate edge map that combines the latent graph edge weights and keypoint locations in a soft, differentiable manner, and iv) an inpainting objective on randomly masked images. Although simpler, AutoLink outperforms existing self-supervised methods on the established keypoint and pose estimation benchmarks and paves the way for structure-conditioned generative models on more diverse datasets.
LatentKeypointGAN: Controlling Images via Latent Keypoints -- Extended Abstract
May 17, 2022
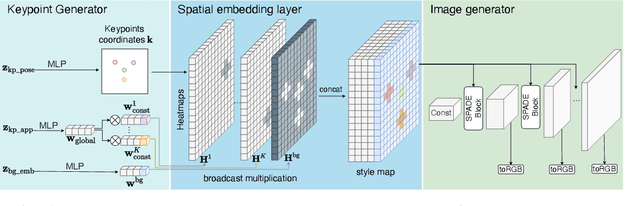
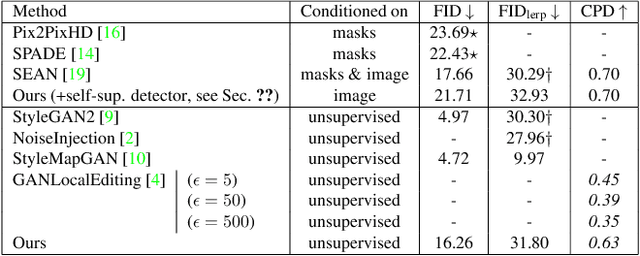
Generative adversarial networks (GANs) can now generate photo-realistic images. However, how to best control the image content remains an open challenge. We introduce LatentKeypointGAN, a two-stage GAN internally conditioned on a set of keypoints and associated appearance embeddings providing control of the position and style of the generated objects and their respective parts. A major difficulty that we address is disentangling the image into spatial and appearance factors with little domain knowledge and supervision signals. We demonstrate in a user study and quantitative experiments that LatentKeypointGAN provides an interpretable latent space that can be used to re-arrange the generated images by re-positioning and exchanging keypoint embeddings, such as generating portraits by combining the eyes, and mouth from different images. Notably, our method does not require labels as it is self-supervised and thereby applies to diverse application domains, such as editing portraits, indoor rooms, and full-body human poses.
GANSeg: Learning to Segment by Unsupervised Hierarchical Image Generation
Dec 02, 2021
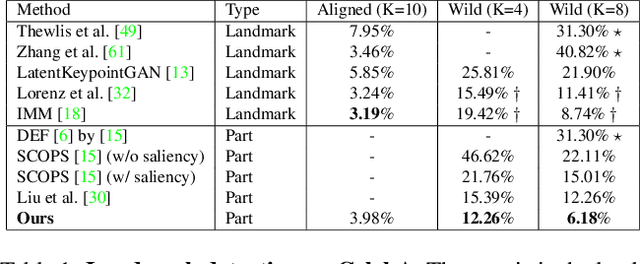
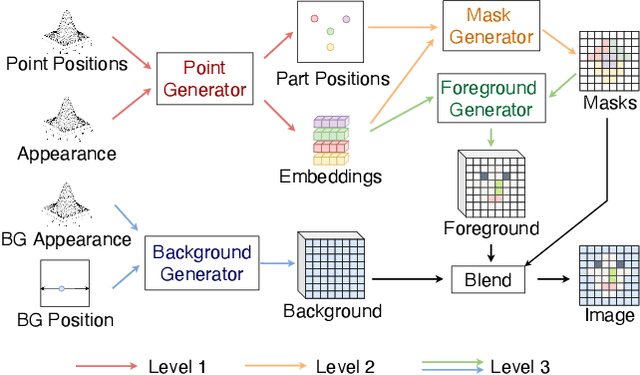
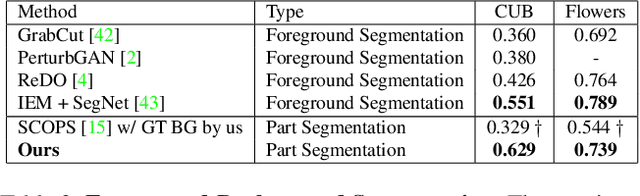
Segmenting an image into its parts is a frequent preprocess for high-level vision tasks such as image editing. However, annotating masks for supervised training is expensive. Weakly-supervised and unsupervised methods exist, but they depend on the comparison of pairs of images, such as from multi-views, frames of videos, and image transformations of single images, which limits their applicability. To address this, we propose a GAN-based approach that generates images conditioned on latent masks, thereby alleviating full or weak annotations required in previous approaches. We show that such mask-conditioned image generation can be learned faithfully when conditioning the masks in a hierarchical manner on latent keypoints that define the position of parts explicitly. Without requiring supervision of masks or points, this strategy increases robustness to viewpoint and object positions changes. It also lets us generate image-mask pairs for training a segmentation network, which outperforms the state-of-the-art unsupervised segmentation methods on established benchmarks.