 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperNet Fields: Efficiently Training Hypernetworks without Ground Truth by Learning Weight Trajectories
Dec 22, 2024To efficiently adapt large models or to train generative models of neural representations, Hypernetworks have drawn interest. While hypernetworks work well, training them is cumbersome, and often requires ground truth optimized weights for each sample. However, obtaining each of these weights is a training problem of its own-one needs to train, e.g., adaptation weights or even an entire neural field for hypernetworks to regress to. In this work, we propose a method to train hypernetworks, without the need for any per-sample ground truth. Our key idea is to learn a Hypernetwork `Field` and estimate the entire trajectory of network weight training instead of simply its converged state. In other words, we introduce an additional input to the Hypernetwork, the convergence state, which then makes it act as a neural field that models the entire convergence pathway of a task network. A critical benefit in doing so is that the gradient of the estimated weights at any convergence state must then match the gradients of the original task -- this constraint alone is sufficient to train the Hypernetwork Field. We demonstrate the effectiveness of our method through the task of personalized image generation and 3D shape reconstruction from images and point clouds, demonstrating competitive results without any per-sample ground truth.
NESI: Shape Representation via Neural Explicit Surface Intersection
Sep 09, 2024



Compressed representations of 3D shapes that are compact, accurate, and can be processed efficiently directly in compressed form, are extremely useful for digital media applications. Recent approaches in this space focus on learned implicit or parametric representations. While implicits are well suited for tasks such as in-out queries, they lack natural 2D parameterization, complicating tasks such as texture or normal mapping. Conversely, parametric representations support the latter tasks but are ill-suited for occupancy queries. We propose a novel learned alternative to these approaches, based on intersections of localized explicit, or height-field, surfaces. Since explicits can be trivially expressed both implicitly and parametrically, NESI directly supports a wider range of processing operations than implicit alternatives, including occupancy queries and parametric access. We represent input shapes using a collection of differently oriented height-field bounded half-spaces combined using volumetric Boolean intersections. We first tightly bound each input using a pair of oppositely oriented height-fields, forming a Double Height-Field (DHF) Hull. We refine this hull by intersecting it with additional localized height-fields (HFs) that capture surface regions in its interior. We minimize the number of HFs necessary to accurately capture each input and compactly encode both the DHF hull and the local HFs as neural functions defined over subdomains of R^2. This reduced dimensionality encoding delivers high-quality compact approximations. Given similar parameter count, or storage capacity, NESI significantly reduces approximation error compared to the state of the art, especially at lower parameter counts.
Unsupervised Keypoints from Pretrained Diffusion Models
Dec 05, 2023



Unsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple datasets: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. Our code is publicly available and can be found through our project page: https://ubc-vision.github.io/StableKeypoints/
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
A Simple Method to Boost Human Pose Estimation Accuracy by Correcting the Joint Regressor for the Human3.6m Dataset
Apr 29, 2022
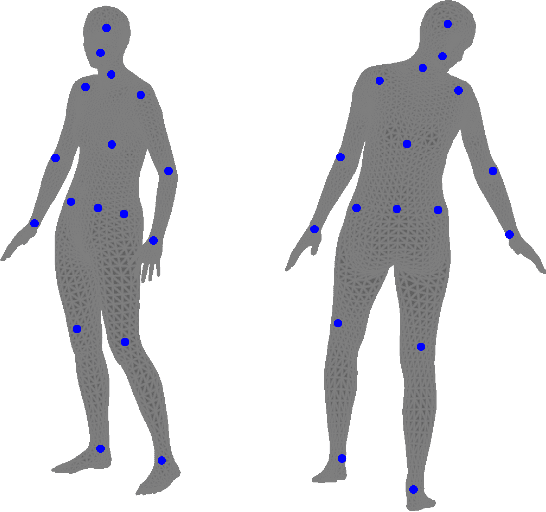


Many human pose estimation methods estimate Skinned Multi-Person Linear (SMPL) models and regress the human joints from these SMPL estimates. In this work, we show that the most widely used SMPL-to-joint linear layer (joint regressor) is inaccurate, which may mislead pose evaluation results. To achieve a more accurate joint regressor, we propose a method to create pseudo-ground-truth SMPL poses, which can then be used to train an improved regressor. Specifically, we optimize SMPL estimates coming from a state-of-the-art method so that its projection matches the silhouettes of humans in the scene, as well as the ground-truth 2D joint locations. While the quality of this pseudo-ground-truth is challenging to assess due to the lack of actual ground-truth SMPL, with the Human 3.6m dataset, we qualitatively show that our joint locations are more accurate and that our regressor leads to improved pose estimations results on the test set without any need for retraining. We release our code and joint regressor at https://github.com/ubc-vision/joint-regressor-refinement