 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullCircle: Effortless 3D Reconstruction from Casual 360$^\circ$ Captures
Mar 23, 2026Radiance fields have emerged as powerful tools for 3D scene reconstruction. However, casual capture remains challenging due to the narrow field of view of perspective cameras, which limits viewpoint coverage and feature correspondences necessary for reliable camera calibration and reconstruction. While commercially available 360$^\circ$ cameras offer significantly broader coverage than perspective cameras for the same capture effort, existing 360$^\circ$ reconstruction methods require special capture protocols and pre-processing steps that undermine the promise of radiance fields: effortless workflows to capture and reconstruct 3D scenes. We propose a practical pipeline for reconstructing 3D scenes directly from raw 360$^\circ$ camera captures. We require no special capture protocols or pre-processing, and exhibit robustness to a prevalent source of reconstruction errors: the human operator that is visible in all 360$^\circ$ imagery. To facilitate evaluation, we introduce a multi-tiered dataset of scenes captured as raw dual-fisheye images, establishing a benchmark for robust casual 360$^\circ$ reconstruction. Our method significantly outperforms not only vanilla 3DGS for 360$^\circ$ cameras but also robust perspective baselines when perspective cameras are simulated from the same capture, demonstrating the advantages of 360$^\circ$ capture for casual reconstruction. Additional results are available at: https://theialab.github.io/fullcircle
Making Video Models Adhere to User Intent with Minor Adjustments
Mar 20, 2026With the recent drastic advancements in text-to-video diffusion models, controlling their generations has drawn interest. A popular way for control is through bounding boxes or layouts. However, enforcing adherence to these control inputs is still an open problem. In this work, we show that by slightly adjusting user-provided bounding boxes we can improve both the quality of generations and the adherence to the control inputs. This is achieved by simply optimizing the bounding boxes to better align with the internal attention maps of the video diffusion model while carefully balancing the focus on foreground and background. In a sense, we are modifying the bounding boxes to be at places where the model is familiar with. Surprisingly, we find that even with small modifications, the quality of generations can vary significantly. To do so, we propose a smooth mask to make the bounding box position differentiable and an attention-maximization objective that we use to alter the bounding boxes. We conduct thorough experiments, including a user study to validate the effectiveness of our method. Our code is made available on the project webpage to foster future research from the community.
StochasticSplats: Stochastic Rasterization for Sorting-Free 3D Gaussian Splatting
Mar 31, 20253D Gaussian splatting (3DGS) is a popular radiance field method, with many application-specific extensions. Most variants rely on the same core algorithm: depth-sorting of Gaussian splats then rasterizing in primitive order. This ensures correct alpha compositing, but can cause rendering artifacts due to built-in approximations. Moreover, for a fixed representation, sorted rendering offers little control over render cost and visual fidelity. For example, and counter-intuitively, rendering a lower-resolution image is not necessarily faster. In this work, we address the above limitations by combining 3D Gaussian splatting with stochastic rasterization. Concretely, we leverage an unbiased Monte Carlo estimator of the volume rendering equation. This removes the need for sorting, and allows for accurate 3D blending of overlapping Gaussians. The number of Monte Carlo samples further imbues 3DGS with a way to trade off computation time and quality. We implement our method using OpenGL shaders, enabling efficient rendering on modern GPU hardware. At a reasonable visual quality, our method renders more than four times faster than sorted rasterization.
ROODI: Reconstructing Occluded Objects with Denoising Inpainters
Mar 13, 2025



While the quality of novel-view images has improved dramatically with 3D Gaussian Splatting, extracting specific objects from scenes remains challenging. Isolating individual 3D Gaussian primitives for each object and handling occlusions in scenes remain far from being solved. We propose a novel object extraction method based on two key principles: (1) being object-centric by pruning irrelevant primitives; and (2) leveraging generative inpainting to compensate for missing observations caused by occlusions. For pruning, we analyze the local structure of primitives using K-nearest neighbors, and retain only relevant ones. For inpainting, we employ an off-the-shelf diffusion-based inpainter combined with occlusion reasoning, utilizing the 3D representation of the entire scene. Our findings highlight the crucial synergy between pruning and inpainting, both of which significantly enhance extraction performance. We evaluate our method on a standard real-world dataset and introduce a synthetic dataset for quantitative analysis. Our approach outperforms the state-of-the-art, demonstrating its effectiveness in object extraction from complex scenes.
NoKSR: Kernel-Free Neural Surface Reconstruction via Point Cloud Serialization
Feb 19, 2025We present a novel approach to large-scale point cloud surface reconstruction by developing an efficient framework that converts an irregular point cloud into a signed distance field (SDF). Our backbone builds upon recent transformer-based architectures (i.e., PointTransformerV3), that serializes the point cloud into a locality-preserving sequence of tokens. We efficiently predict the SDF value at a point by aggregating nearby tokens, where fast approximate neighbors can be retrieved thanks to the serialization. We serialize the point cloud at different levels/scales, and non-linearly aggregate a feature to predict the SDF value. We show that aggregating across multiple scales is critical to overcome the approximations introduced by the serialization (i.e. false negatives in the neighborhood). Our frameworks sets the new state-of-the-art in terms of accuracy and efficiency (better or similar performance with half the latency of the best prior method, coupled with a simpler implementation), particularly on outdoor datasets where sparse-grid methods have shown limited performance.
Radiant Foam: Real-Time Differentiable Ray Tracing
Feb 03, 2025



Research on differentiable scene representations is consistently moving towards more efficient, real-time models. Recently, this has led to the popularization of splatting methods, which eschew the traditional ray-based rendering of radiance fields in favor of rasterization. This has yielded a significant improvement in rendering speeds due to the efficiency of rasterization algorithms and hardware, but has come at a cost: the approximations that make rasterization efficient also make implementation of light transport phenomena like reflection and refraction much more difficult. We propose a novel scene representation which avoids these approximations, but keeps the efficiency and reconstruction quality of splatting by leveraging a decades-old efficient volumetric mesh ray tracing algorithm which has been largely overlooked in recent computer vision research. The resulting model, which we name Radiant Foam, achieves rendering speed and quality comparable to Gaussian Splatting, without the constraints of rasterization. Unlike ray traced Gaussian models that use hardware ray tracing acceleration, our method requires no special hardware or APIs beyond the standard features of a programmable GPU.
Improving Generative Pre-Training: An In-depth Study of Masked Image Modeling and Denoising Models
Dec 26, 2024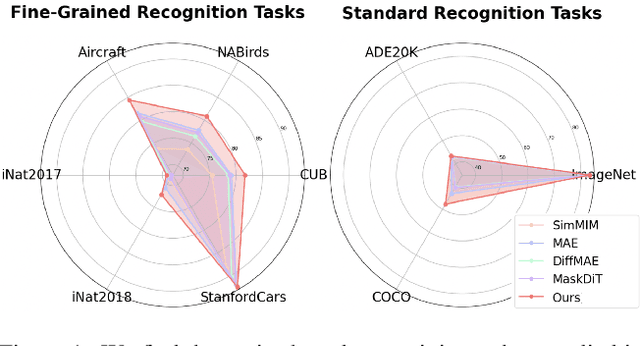
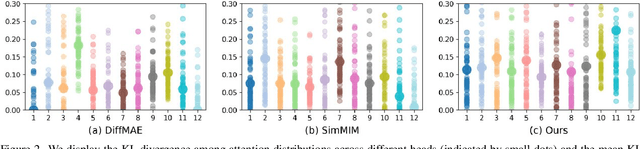

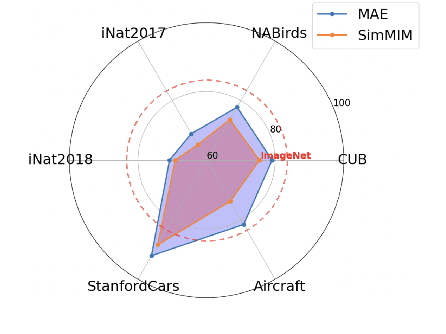
In this work, we dive deep into the impact of additive noise in pre-training deep networks. While various methods have attempted to use additive noise inspired by the success of latent denoising diffusion models, when used in combination with masked image modeling, their gains have been marginal when it comes to recognition tasks. We thus investigate why this would be the case, in an attempt to find effective ways to combine the two ideas. Specifically, we find three critical conditions: corruption and restoration must be applied within the encoder, noise must be introduced in the feature space, and an explicit disentanglement between noised and masked tokens is necessary. By implementing these findings, we demonstrate improved pre-training performance for a wide range of recognition tasks, including those that require fine-grained, high-frequency information to solve.
HyperNet Fields: Efficiently Training Hypernetworks without Ground Truth by Learning Weight Trajectories
Dec 22, 2024To efficiently adapt large models or to train generative models of neural representations, Hypernetworks have drawn interest. While hypernetworks work well, training them is cumbersome, and often requires ground truth optimized weights for each sample. However, obtaining each of these weights is a training problem of its own-one needs to train, e.g., adaptation weights or even an entire neural field for hypernetworks to regress to. In this work, we propose a method to train hypernetworks, without the need for any per-sample ground truth. Our key idea is to learn a Hypernetwork `Field` and estimate the entire trajectory of network weight training instead of simply its converged state. In other words, we introduce an additional input to the Hypernetwork, the convergence state, which then makes it act as a neural field that models the entire convergence pathway of a task network. A critical benefit in doing so is that the gradient of the estimated weights at any convergence state must then match the gradients of the original task -- this constraint alone is sufficient to train the Hypernetwork Field. We demonstrate the effectiveness of our method through the task of personalized image generation and 3D shape reconstruction from images and point clouds, demonstrating competitive results without any per-sample ground truth.
Disk2Planet: A Robust and Automated Machine Learning Tool for Parameter Inference in Disk-Planet Systems
Sep 25, 2024
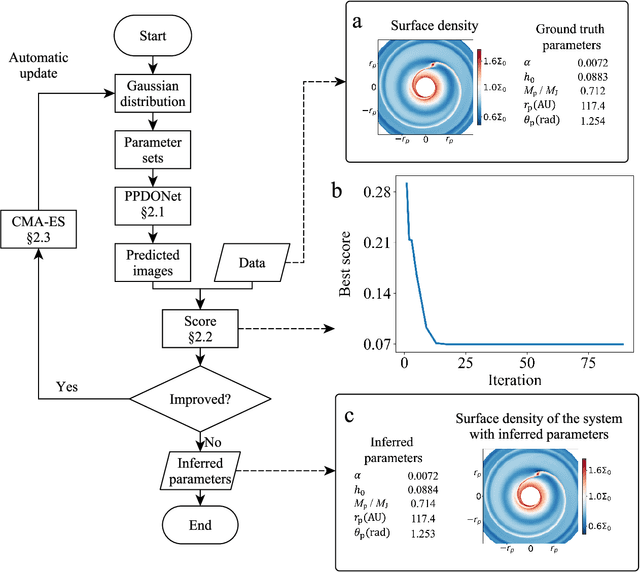
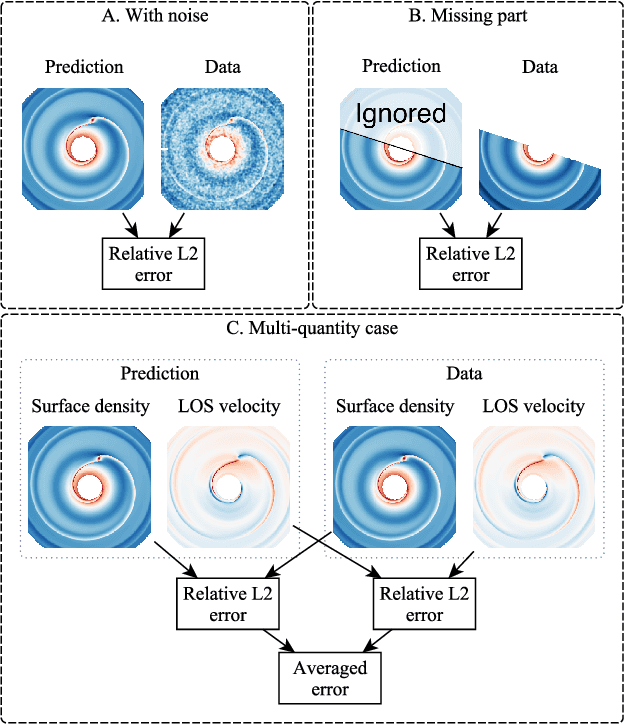
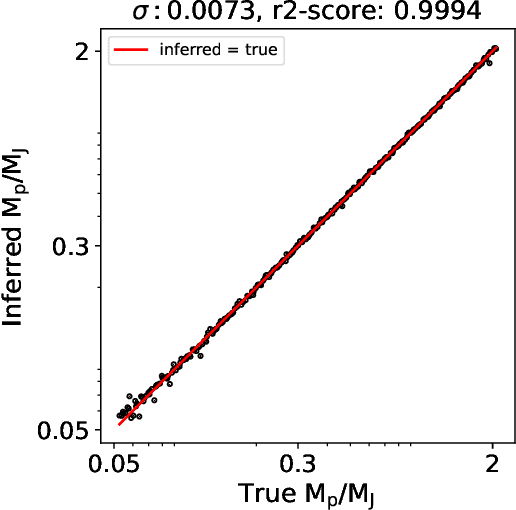
We introduce Disk2Planet, a machine learning-based tool to infer key parameters in disk-planet systems from observed protoplanetary disk structures. Disk2Planet takes as input the disk structures in the form of two-dimensional density and velocity maps, and outputs disk and planet properties, that is, the Shakura--Sunyaev viscosity, the disk aspect ratio, the planet--star mass ratio, and the planet's radius and azimuth. We integrate the Covariance Matrix Adaptation Evolution Strategy (CMA--ES), an evolutionary algorithm tailored for complex optimization problems, and the Protoplanetary Disk Operator Network (PPDONet), a neural network designed to predict solutions of disk--planet interactions. Our tool is fully automated and can retrieve parameters in one system in three minutes on an Nvidia A100 graphics processing unit. We empirically demonstrate that our tool achieves percent-level or higher accuracy, and is able to handle missing data and unknown levels of noise.
NESI: Shape Representation via Neural Explicit Surface Intersection
Sep 09, 2024



Compressed representations of 3D shapes that are compact, accurate, and can be processed efficiently directly in compressed form, are extremely useful for digital media applications. Recent approaches in this space focus on learned implicit or parametric representations. While implicits are well suited for tasks such as in-out queries, they lack natural 2D parameterization, complicating tasks such as texture or normal mapping. Conversely, parametric representations support the latter tasks but are ill-suited for occupancy queries. We propose a novel learned alternative to these approaches, based on intersections of localized explicit, or height-field, surfaces. Since explicits can be trivially expressed both implicitly and parametrically, NESI directly supports a wider range of processing operations than implicit alternatives, including occupancy queries and parametric access. We represent input shapes using a collection of differently oriented height-field bounded half-spaces combined using volumetric Boolean intersections. We first tightly bound each input using a pair of oppositely oriented height-fields, forming a Double Height-Field (DHF) Hull. We refine this hull by intersecting it with additional localized height-fields (HFs) that capture surface regions in its interior. We minimize the number of HFs necessary to accurately capture each input and compactly encode both the DHF hull and the local HFs as neural functions defined over subdomains of R^2. This reduced dimensionality encoding delivers high-quality compact approximations. Given similar parameter count, or storage capacity, NESI significantly reduces approximation error compared to the state of the art, especially at lower parameter counts.