 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoGoColor: Local-Global 3D Colorization for 360° Scenes
Dec 10, 2025



Single-channel 3D reconstruction is widely used in fields such as robotics and medical imaging. While this line of work excels at reconstructing 3D geometry, the outputs are not colored 3D models, thus 3D colorization is required for visualization. Recent 3D colorization studies address this problem by distilling 2D image colorization models. However, these approaches suffer from an inherent inconsistency of 2D image models. This results in colors being averaged during training, leading to monotonous and oversimplified results, particularly in complex 360° scenes. In contrast, we aim to preserve color diversity by generating a new set of consistently colorized training views, thereby bypassing the averaging process. Nevertheless, eliminating the averaging process introduces a new challenge: ensuring strict multi-view consistency across these colorized views. To achieve this, we propose LoGoColor, a pipeline designed to preserve color diversity by eliminating this guidance-averaging process with a `Local-Global' approach: we partition the scene into subscenes and explicitly tackle both inter-subscene and intra-subscene consistency using a fine-tuned multi-view diffusion model. We demonstrate that our method achieves quantitatively and qualitatively more consistent and plausible 3D colorization on complex 360° scenes than existing methods, and validate its superior color diversity using a novel Color Diversity Index.
DivCon-NeRF: Generating Augmented Rays with Diversity and Consistency for Few-shot View Synthesis
Mar 17, 2025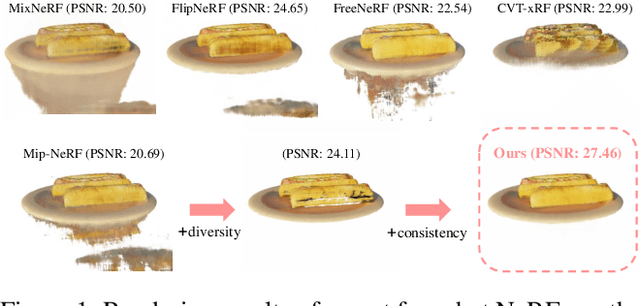

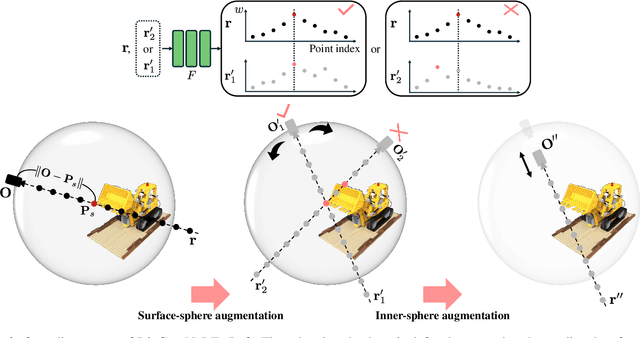

Neural Radiance Field (NeRF) has shown remarkable performance in novel view synthesis but requires many multiview images, making it impractical for few-shot scenarios. Ray augmentation was proposed to prevent overfitting for sparse training data by generating additional rays. However, existing methods, which generate augmented rays only near the original rays, produce severe floaters and appearance distortion due to limited viewpoints and inconsistent rays obstructed by nearby obstacles and complex surfaces. To address these problems, we propose DivCon-NeRF, which significantly enhances both diversity and consistency. It employs surface-sphere augmentation, which preserves the distance between the original camera and the predicted surface point. This allows the model to compare the order of high-probability surface points and filter out inconsistent rays easily without requiring the exact depth. By introducing inner-sphere augmentation, DivCon-NeRF randomizes angles and distances for diverse viewpoints, further increasing diversity. Consequently, our method significantly reduces floaters and visual distortions, achieving state-of-the-art performance on the Blender, LLFF, and DTU datasets. Our code will be publicly available.
ROODI: Reconstructing Occluded Objects with Denoising Inpainters
Mar 13, 2025



While the quality of novel-view images has improved dramatically with 3D Gaussian Splatting, extracting specific objects from scenes remains challenging. Isolating individual 3D Gaussian primitives for each object and handling occlusions in scenes remain far from being solved. We propose a novel object extraction method based on two key principles: (1) being object-centric by pruning irrelevant primitives; and (2) leveraging generative inpainting to compensate for missing observations caused by occlusions. For pruning, we analyze the local structure of primitives using K-nearest neighbors, and retain only relevant ones. For inpainting, we employ an off-the-shelf diffusion-based inpainter combined with occlusion reasoning, utilizing the 3D representation of the entire scene. Our findings highlight the crucial synergy between pruning and inpainting, both of which significantly enhance extraction performance. We evaluate our method on a standard real-world dataset and introduce a synthetic dataset for quantitative analysis. Our approach outperforms the state-of-the-art, demonstrating its effectiveness in object extraction from complex scenes.
Unleash the Potential of CLIP for Video Highlight Detection
Apr 02, 2024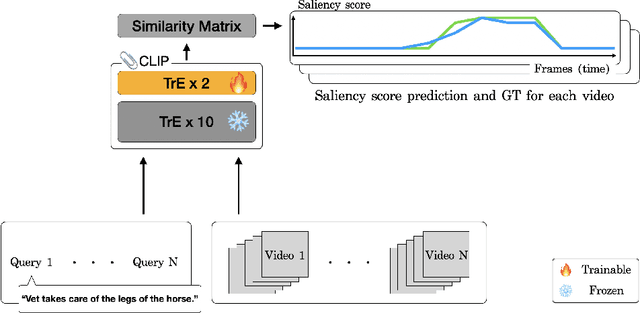
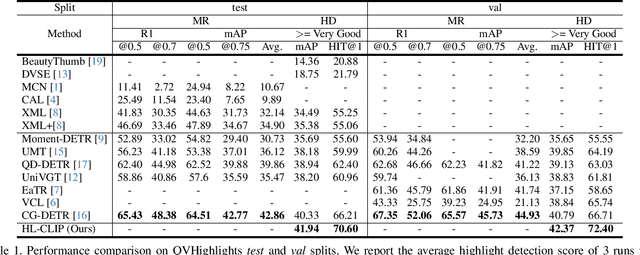
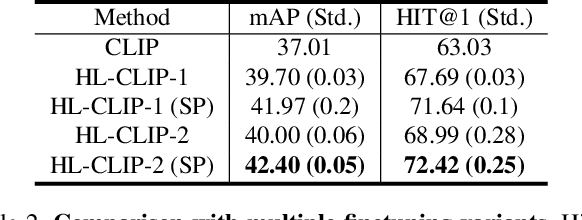
Multimodal and large language models (LLMs) have revolutionized the utilization of open-world knowledge, unlocking novel potentials across various tasks and applications. Among these domains, the video domain has notably benefited from their capabilities. In this paper, we present Highlight-CLIP (HL-CLIP), a method designed to excel in the video highlight detection task by leveraging the pre-trained knowledge embedded in multimodal models. By simply fine-tuning the multimodal encoder in combination with our innovative saliency pooling technique, we have achieved the state-of-the-art performance in the highlight detection task, the QVHighlight Benchmark, to the best of our knowledge.
HourglassNeRF: Casting an Hourglass as a Bundle of Rays for Few-shot Neural Rendering
Mar 16, 2024Recent advancements in the Neural Radiance Field (NeRF) have bolstered its capabilities for novel view synthesis, yet its reliance on dense multi-view training images poses a practical challenge. Addressing this, we propose HourglassNeRF, an effective regularization-based approach with a novel hourglass casting strategy. Our proposed hourglass is conceptualized as a bundle of additional rays within the area between the original input ray and its corresponding reflection ray, by featurizing the conical frustum via Integrated Positional Encoding (IPE). This design expands the coverage of unseen views and enables an adaptive high-frequency regularization based on target pixel photo-consistency. Furthermore, we propose luminance consistency regularization based on the Lambertian assumption, which is known to be effective for training a set of augmented rays under the few-shot setting. Leveraging the inherent property of a Lambertian surface, which retains consistent luminance irrespective of the viewing angle, we assume our proposed hourglass as a collection of flipped diffuse reflection rays and enhance the luminance consistency between the original input ray and its corresponding hourglass, resulting in more physically grounded training framework and performance improvement. Our HourglassNeRF outperforms its baseline and achieves competitive results on multiple benchmarks with sharply rendered fine details. The code will be available.
Fast Sun-aligned Outdoor Scene Relighting based on TensoRF
Nov 07, 2023

In this work, we introduce our method of outdoor scene relighting for Neural Radiance Fields (NeRF) named Sun-aligned Relighting TensoRF (SR-TensoRF). SR-TensoRF offers a lightweight and rapid pipeline aligned with the sun, thereby achieving a simplified workflow that eliminates the need for environment maps. Our sun-alignment strategy is motivated by the insight that shadows, unlike viewpoint-dependent albedo, are determined by light direction. We directly use the sun direction as an input during shadow generation, simplifying the requirements of the inference process significantly. Moreover, SR-TensoRF leverages the training efficiency of TensoRF by incorporating our proposed cubemap concept, resulting in notable acceleration in both training and rendering processes compared to existing methods.
ConcatPlexer: Additional Dim1 Batching for Faster ViTs
Aug 22, 2023Transformers have demonstrated tremendous success not only in the natural language processing (NLP) domain but also the field of computer vision, igniting various creative approaches and applications. Yet, the superior performance and modeling flexibility of transformers came with a severe increase in computation costs, and hence several works have proposed methods to reduce this burden. Inspired by a cost-cutting method originally proposed for language models, Data Multiplexing (DataMUX), we propose a novel approach for efficient visual recognition that employs additional dim1 batching (i.e., concatenation) that greatly improves the throughput with little compromise in the accuracy. We first introduce a naive adaptation of DataMux for vision models, Image Multiplexer, and devise novel components to overcome its weaknesses, rendering our final model, ConcatPlexer, at the sweet spot between inference speed and accuracy. The ConcatPlexer was trained on ImageNet1K and CIFAR100 dataset and it achieved 23.5% less GFLOPs than ViT-B/16 with 69.5% and 83.4% validation accuracy, respectively.
FlipNeRF: Flipped Reflection Rays for Few-shot Novel View Synthesis
Jul 16, 2023Neural Radiance Field (NeRF) has been a mainstream in novel view synthesis with its remarkable quality of rendered images and simple architecture. Although NeRF has been developed in various directions improving continuously its performance, the necessity of a dense set of multi-view images still exists as a stumbling block to progress for practical application. In this work, we propose FlipNeRF, a novel regularization method for few-shot novel view synthesis by utilizing our proposed flipped reflection rays. The flipped reflection rays are explicitly derived from the input ray directions and estimated normal vectors, and play a role of effective additional training rays while enabling to estimate more accurate surface normals and learn the 3D geometry effectively. Since the surface normal and the scene depth are both derived from the estimated densities along a ray, the accurate surface normal leads to more exact depth estimation, which is a key factor for few-shot novel view synthesis. Furthermore, with our proposed Uncertainty-aware Emptiness Loss and Bottleneck Feature Consistency Loss, FlipNeRF is able to estimate more reliable outputs with reducing floating artifacts effectively across the different scene structures, and enhance the feature-level consistency between the pair of the rays cast toward the photo-consistent pixels without any additional feature extractor, respectively. Our FlipNeRF achieves the SOTA performance on the multiple benchmarks across all the scenarios.
MDPose: Real-Time Multi-Person Pose Estimation via Mixture Density Model
Feb 17, 2023One of the major challenges in multi-person pose estimation is instance-aware keypoint estimation. Previous methods address this problem by leveraging an off-the-shelf detector, heuristic post-grouping process or explicit instance identification process, hindering further improvements in the inference speed which is an important factor for practical applications. From the statistical point of view, those additional processes for identifying instances are necessary to bypass learning the high-dimensional joint distribution of human keypoints, which is a critical factor for another major challenge, the occlusion scenario. In this work, we propose a novel framework of single-stage instance-aware pose estimation by modeling the joint distribution of human keypoints with a mixture density model, termed as MDPose. Our MDPose estimates the distribution of human keypoints' coordinates using a mixture density model with an instance-aware keypoint head consisting simply of 8 convolutional layers. It is trained by minimizing the negative log-likelihood of the ground truth keypoints. Also, we propose a simple yet effective training strategy, Random Keypoint Grouping (RKG), which significantly alleviates the underflow problem leading to successful learning of relations between keypoints. On OCHuman dataset, which consists of images with highly occluded people, our MDPose achieves state-of-the-art performance by successfully learning the high-dimensional joint distribution of human keypoints. Furthermore, our MDPose shows significant improvement in inference speed with a competitive accuracy on MS COCO, a widely-used human keypoint dataset, thanks to the proposed much simpler single-stage pipeline.
MixNeRF: Modeling a Ray with Mixture Density for Novel View Synthesis from Sparse Inputs
Feb 17, 2023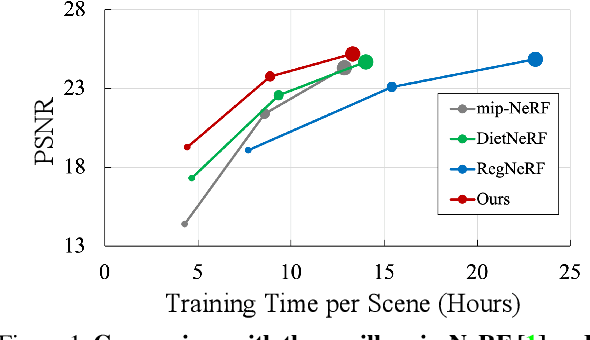
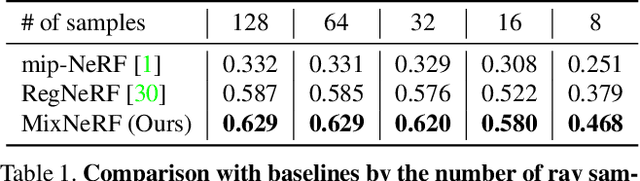
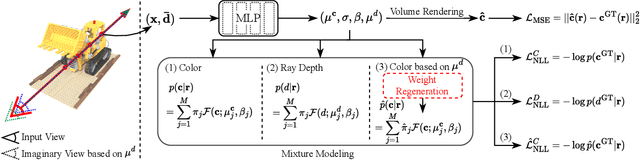
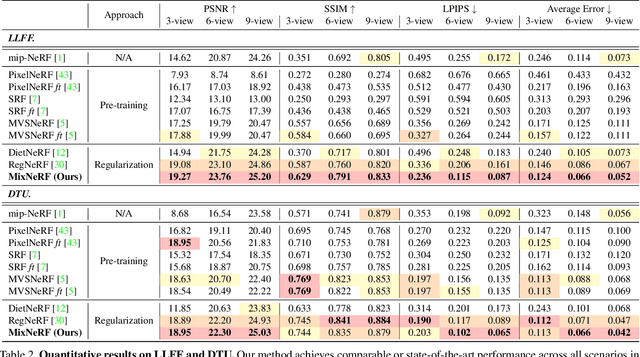
Neural Radiance Field (NeRF) has broken new ground in the novel view synthesis due to its simple concept and state-of-the-art quality. However, it suffers from severe performance degradation unless trained with a dense set of images with different camera poses, which hinders its practical applications. Although previous methods addressing this problem achieved promising results, they relied heavily on the additional training resources, which goes against the philosophy of sparse-input novel-view synthesis pursuing the training efficiency. In this work, we propose MixNeRF, an effective training strategy for novel view synthesis from sparse inputs by modeling a ray with a mixture density model. Our MixNeRF estimates the joint distribution of RGB colors along the ray samples by modeling it with mixture of distributions. We also propose a new task of ray depth estimation as a useful training objective, which is highly correlated with 3D scene geometry. Moreover, we remodel the colors with regenerated blending weights based on the estimated ray depth and further improves the robustness for colors and viewpoints. Our MixNeRF outperforms other state-of-the-art methods in various standard benchmarks with superior efficiency of training and inference.