 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Bias in the Model for Continual Test-Time Adaptation
Mar 02, 2024
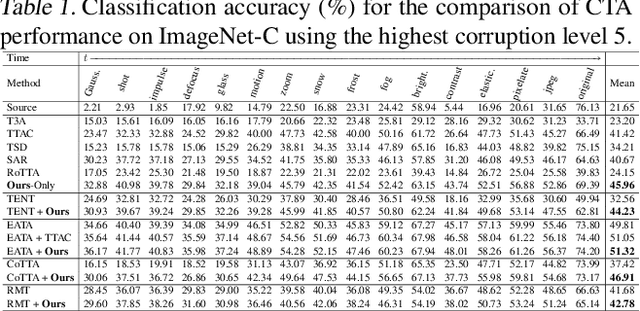
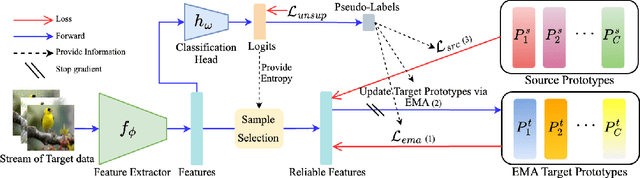
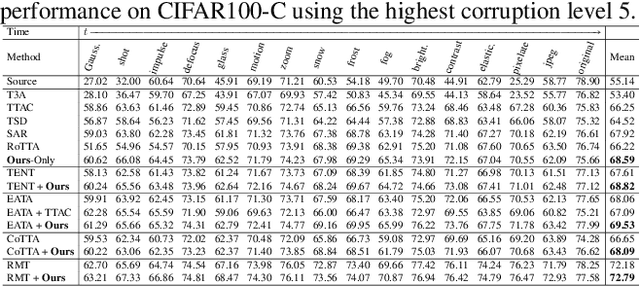
Continual Test-Time Adaptation (CTA) is a challenging task that aims to adapt a source pre-trained model to continually changing target domains. In the CTA setting, a model does not know when the target domain changes, thus facing a drastic change in the distribution of streaming inputs during the test-time. The key challenge is to keep adapting the model to the continually changing target domains in an online manner. We find that a model shows highly biased predictions as it constantly adapts to the chaining distribution of the target data. It predicts certain classes more often than other classes, making inaccurate over-confident predictions. This paper mitigates this issue to improve performance in the CTA scenario. To alleviate the bias issue, we make class-wise exponential moving average target prototypes with reliable target samples and exploit them to cluster the target features class-wisely. Moreover, we aim to align the target distributions to the source distribution by anchoring the target feature to its corresponding source prototype. With extensive experiments, our proposed method achieves noteworthy performance gain when applied on top of existing CTA methods without substantial adaptation time overhead.
What, How, and When Should Object Detectors Update in Continually Changing Test Domains?
Dec 12, 2023



It is a well-known fact that the performance of deep learning models deteriorates when they encounter a distribution shift at test time. Test-time adaptation (TTA) algorithms have been proposed to adapt the model online while inferring test data. However, existing research predominantly focuses on classification tasks through the optimization of batch normalization layers or classification heads, but this approach limits its applicability to various model architectures like Transformers and makes it challenging to apply to other tasks, such as object detection. In this paper, we propose a novel online adaption approach for object detection in continually changing test domains, considering which part of the model to update, how to update it, and when to perform the update. By introducing architecture-agnostic and lightweight adaptor modules and only updating these while leaving the pre-trained backbone unchanged, we can rapidly adapt to new test domains in an efficient way and prevent catastrophic forgetting. Furthermore, we present a practical and straightforward class-wise feature aligning method for object detection to resolve domain shifts. Additionally, we enhance efficiency by determining when the model is sufficiently adapted or when additional adaptation is needed due to changes in the test distribution. Our approach surpasses baselines on widely used benchmarks, achieving improvements of up to 4.9\%p and 7.9\%p in mAP for COCO $\rightarrow$ COCO-corrupted and SHIFT, respectively, while maintaining about 20 FPS or higher.
Open Domain Generalization with a Single Network by Regularization Exploiting Pre-trained Features
Dec 08, 2023



Open Domain Generalization (ODG) is a challenging task as it not only deals with distribution shifts but also category shifts between the source and target datasets. To handle this task, the model has to learn a generalizable representation that can be applied to unseen domains while also identify unknown classes that were not present during training. Previous work has used multiple source-specific networks, which involve a high computation cost. Therefore, this paper proposes a method that can handle ODG using only a single network. The proposed method utilizes a head that is pre-trained by linear-probing and employs two regularization terms, each targeting the regularization of feature extractor and the classification head, respectively. The two regularization terms fully utilize the pre-trained features and collaborate to modify the head of the model without excessively altering the feature extractor. This ensures a smoother softmax output and prevents the model from being biased towards the source domains. The proposed method shows improved adaptability to unseen domains and increased capability to detect unseen classes as well. Extensive experiments show that our method achieves competitive performance in several benchmarks. We also justify our method with careful analysis of the effect on the logits, features, and the head.
X-MAS: Extremely Large-Scale Multi-Modal Sensor Dataset for Outdoor Surveillance in Real Environments
Dec 30, 2022



In robotics and computer vision communities, extensive studies have been widely conducted regarding surveillance tasks, including human detection, tracking, and motion recognition with a camera. Additionally, deep learning algorithms are widely utilized in the aforementioned tasks as in other computer vision tasks. Existing public datasets are insufficient to develop learning-based methods that handle various surveillance for outdoor and extreme situations such as harsh weather and low illuminance conditions. Therefore, we introduce a new large-scale outdoor surveillance dataset named eXtremely large-scale Multi-modAl Sensor dataset (X-MAS) containing more than 500,000 image pairs and the first-person view data annotated by well-trained annotators. Moreover, a single pair contains multi-modal data (e.g. an IR image, an RGB image, a thermal image, a depth image, and a LiDAR scan). This is the first large-scale first-person view outdoor multi-modal dataset focusing on surveillance tasks to the best of our knowledge. We present an overview of the proposed dataset with statistics and present methods of exploiting our dataset with deep learning-based algorithms. The latest information on the dataset and our study are available at https://github.com/lge-robot-navi, and the dataset will be available for download through a server.
Unsupervised Domain Adaptation for One-stage Object Detector using Offsets to Bounding Box
Jul 20, 2022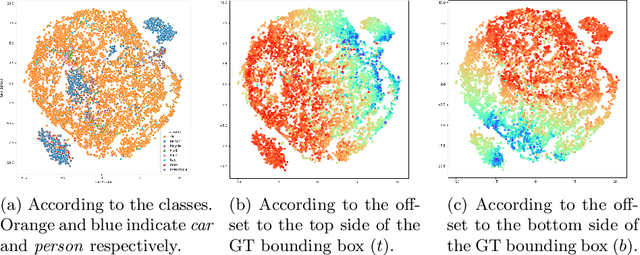


Most existing domain adaptive object detection methods exploit adversarial feature alignment to adapt the model to a new domain. Recent advances in adversarial feature alignment strives to reduce the negative effect of alignment, or negative transfer, that occurs because the distribution of features varies depending on the category of objects. However, by analyzing the features of the anchor-free one-stage detector, in this paper, we find that negative transfer may occur because the feature distribution varies depending on the regression value for the offset to the bounding box as well as the category. To obtain domain invariance by addressing this issue, we align the feature conditioned on the offset value, considering the modality of the feature distribution. With a very simple and effective conditioning method, we propose OADA (Offset-Aware Domain Adaptive object detector) that achieves state-of-the-art performances in various experimental settings. In addition, by analyzing through singular value decomposition, we find that our model enhances both discriminability and transferability.
Personalized Keyword Spotting through Multi-task Learning
Jun 28, 2022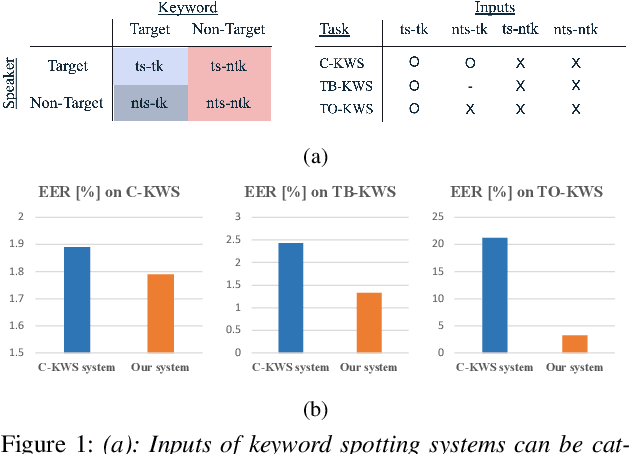
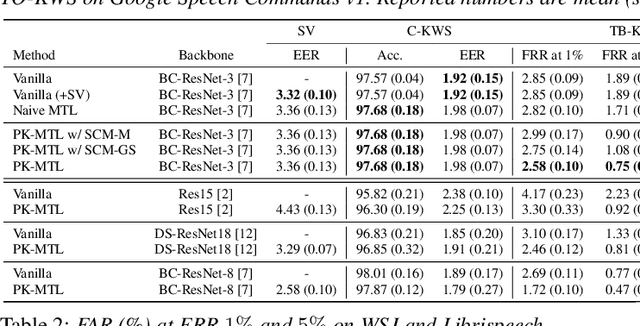
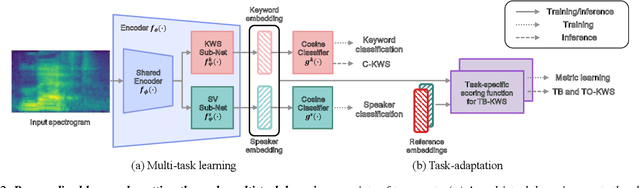
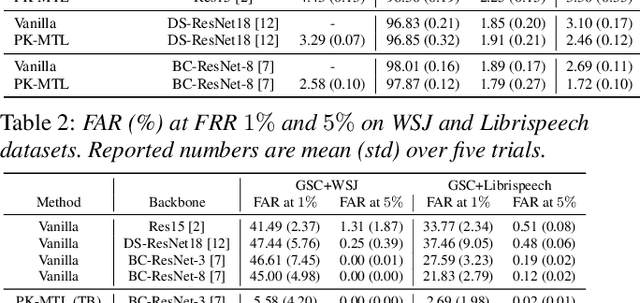
Keyword spotting (KWS) plays an essential role in enabling speech-based user interaction on smart devices, and conventional KWS (C-KWS) approaches have concentrated on detecting user-agnostic pre-defined keywords. However, in practice, most user interactions come from target users enrolled in the device which motivates to construct personalized keyword spotting. We design two personalized KWS tasks; (1) Target user Biased KWS (TB-KWS) and (2) Target user Only KWS (TO-KWS). To solve the tasks, we propose personalized keyword spotting through multi-task learning (PK-MTL) that consists of multi-task learning and task-adaptation. First, we introduce applying multi-task learning on keyword spotting and speaker verification to leverage user information to the keyword spotting system. Next, we design task-specific scoring functions to adapt to the personalized KWS tasks thoroughly. We evaluate our framework on conventional and personalized scenarios, and the results show that PK-MTL can dramatically reduce the false alarm rate, especially in various practical scenarios.
Dummy Prototypical Networks for Few-Shot Open-Set Keyword Spotting
Jun 28, 2022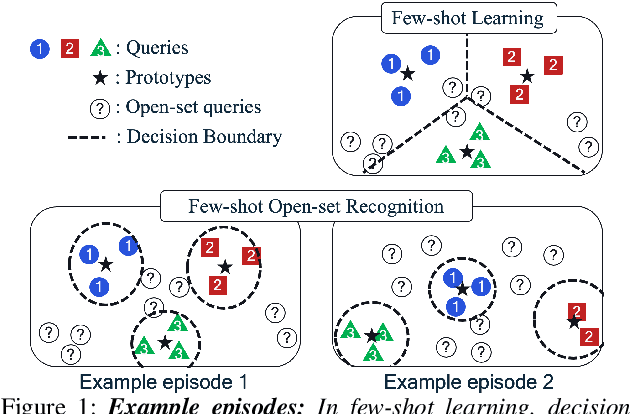
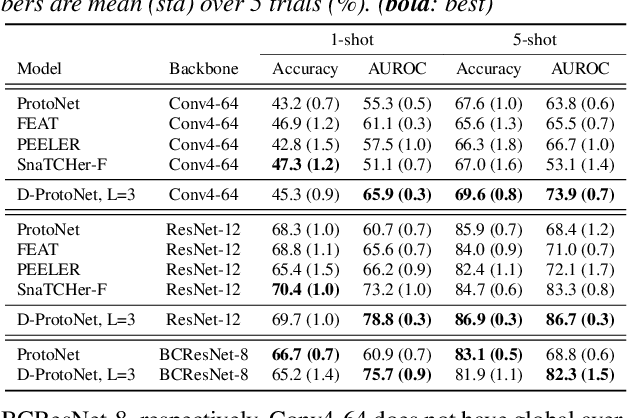

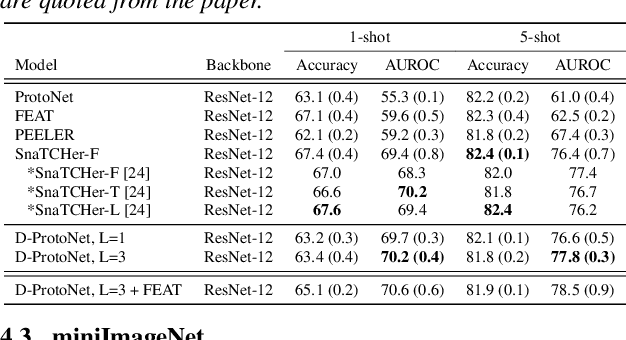
Keyword spotting is the task of detecting a keyword in streaming audio. Conventional keyword spotting targets predefined keywords classification, but there is growing attention in few-shot (query-by-example) keyword spotting, e.g., N-way classification given M-shot support samples. Moreover, in real-world scenarios, there can be utterances from unexpected categories (open-set) which need to be rejected rather than classified as one of the N classes. Combining the two needs, we tackle few-shot open-set keyword spotting with a new benchmark setting, named splitGSC. We propose episode-known dummy prototypes based on metric learning to detect an open-set better and introduce a simple and powerful approach, Dummy Prototypical Networks (D-ProtoNets). Our D-ProtoNets shows clear margins compared to recent few-shot open-set recognition (FSOSR) approaches in the suggested splitGSC. We also verify our method on a standard benchmark, miniImageNet, and D-ProtoNets shows the state-of-the-art open-set detection rate in FSOSR.
Sparse MDOD: Training End-to-End Multi-Object Detector without Bipartite Matching
May 18, 2022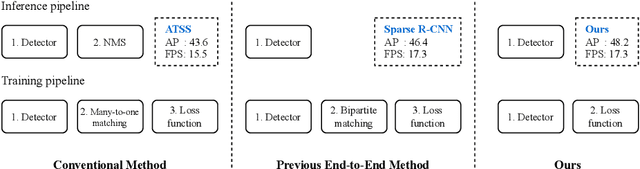
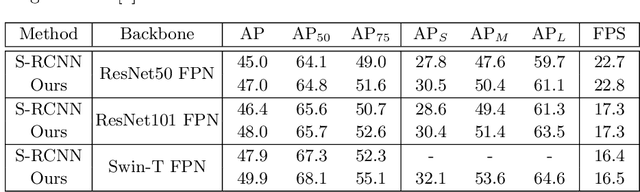
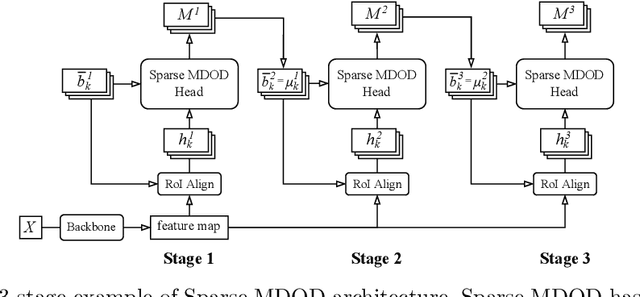
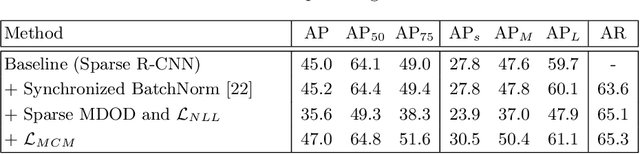
Recent end-to-end multi-object detectors simplify the inference pipeline by removing the hand-crafted process such as the duplicate bounding box removal using non-maximum suppression (NMS). However, in the training, they require bipartite matching to calculate the loss from the output of the detector. Contrary to the directivity of the end-to-end method, the bipartite matching makes the training of the end-to-end detector complex, heuristic, and reliant. In this paper, we aim to propose a method to train the end-to-end multi-object detector without bipartite matching. To this end, we approach end-to-end multi-object detection as a density estimation using a mixture model. Our proposed detector, called Sparse Mixture Density Object Detector (Sparse MDOD) estimates the distribution of bounding boxes using a mixture model. Sparse MDOD is trained by minimizing the negative log-likelihood and our proposed regularization term, maximum component maximization (MCM) loss that prevents duplicated predictions. During training, no additional procedure such as bipartite matching is needed, and the loss is directly computed from the network outputs. Moreover, our Sparse MDOD outperforms the existing detectors on MS-COCO, a renowned multi-object detection benchmark.
Exploiting Inter-pixel Correlations in Unsupervised Domain Adaptation for Semantic Segmentation
Oct 21, 2021
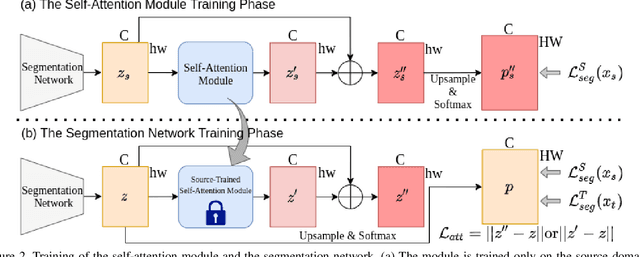
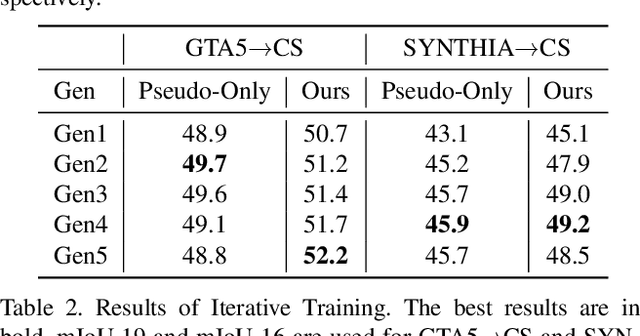
"Self-training" has become a dominant method for semantic segmentation via unsupervised domain adaptation (UDA). It creates a set of pseudo labels for the target domain to give explicit supervision. However, the pseudo labels are noisy, sparse and do not provide any information about inter-pixel correlations. We regard inter-pixel correlation quite important because semantic segmentation is a task of predicting highly structured pixel-level outputs. Therefore, in this paper, we propose a method of transferring the inter-pixel correlations from the source domain to the target domain via a self-attention module. The module takes the prediction of the segmentation network as an input and creates a self-attended prediction that correlates similar pixels. The module is trained only on the source domain to learn the domain-invariant inter-pixel correlations, then later, it is used to train the segmentation network on the target domain. The network learns not only from the pseudo labels but also by following the output of the self-attention module which provides additional knowledge about the inter-pixel correlations. Through extensive experiments, we show that our method significantly improves the performance on two standard UDA benchmarks and also can be combined with recent state-of-the-art method to achieve better performance.
Maximizing Cosine Similarity Between Spatial Features for Unsupervised Domain Adaptation in Semantic Segmentation
Mar 18, 2021


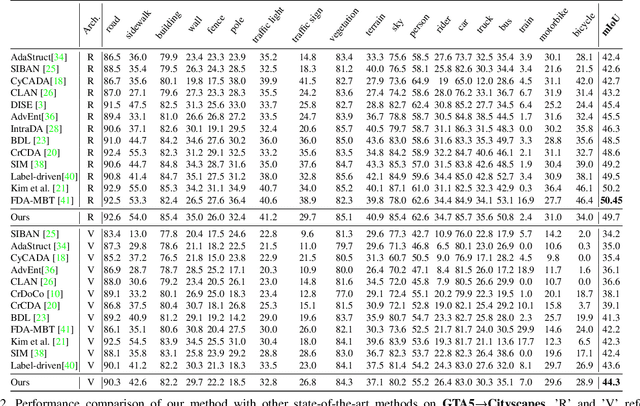
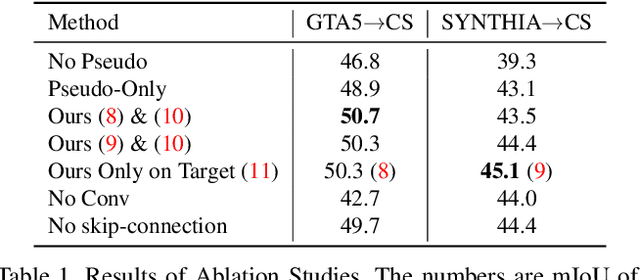
We propose a novel method that tackles the problem of unsupervised domain adaptation for semantic segmentation by maximizing the cosine similarity between the source and the target domain at the feature level. A segmentation network mainly consists of two parts, a feature extractor and a classification head. We expect that if we can make the two domains have small domain gap at the feature level, they would also have small domain discrepancy at the classification head. Our method computes a cosine similarity matrix between the source feature map and the target feature map, then we maximize the elements exceeding a threshold to guide the target features to have high similarity with the most similar source feature. Moreover, we use a class-wise source feature dictionary which stores the latest features of the source domain to prevent the unmatching problem when computing the cosine similarity matrix and be able to compare a target feature with various source features from various images. Through extensive experiments, we verify that our method gains performance on two unsupervised domain adaptation tasks (GTA5$\to$ Cityscaspes and SYNTHIA$\to$ Cityscapes).