 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Transfer Learning for Open-World Few-Shot Recognition
Nov 15, 2024Few-Shot Open-Set Recognition (FSOSR) targets a critical real-world challenge, aiming to categorize inputs into known categories, termed closed-set classes, while identifying open-set inputs that fall outside these classes. Although transfer learning where a model is tuned to a given few-shot task has become a prominent paradigm in closed-world, we observe that it fails to expand to open-world. To unlock this challenge, we propose a two-stage method which consists of open-set aware meta-learning with open-set free transfer learning. In the open-set aware meta-learning stage, a model is trained to establish a metric space that serves as a beneficial starting point for the subsequent stage. During the open-set free transfer learning stage, the model is further adapted to a specific target task through transfer learning. Additionally, we introduce a strategy to simulate open-set examples by modifying the training dataset or generating pseudo open-set examples. The proposed method achieves state-of-the-art performance on two widely recognized benchmarks, miniImageNet and tieredImageNet, with only a 1.5\% increase in training effort. Our work demonstrates the effectiveness of transfer learning in FSOSR.
Improving Small Footprint Few-shot Keyword Spotting with Supervision on Auxiliary Data
Aug 31, 2023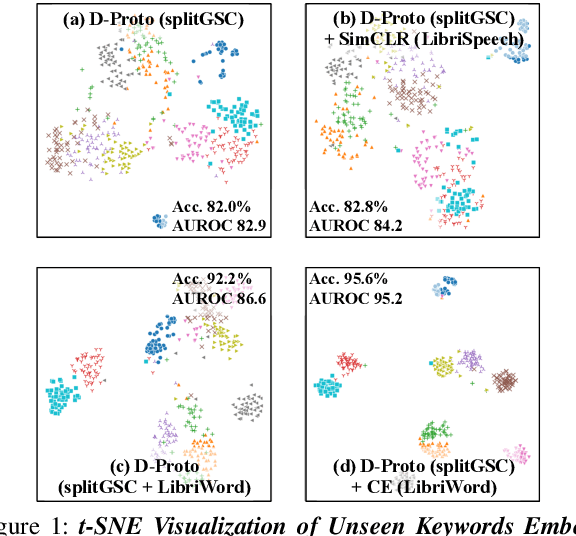
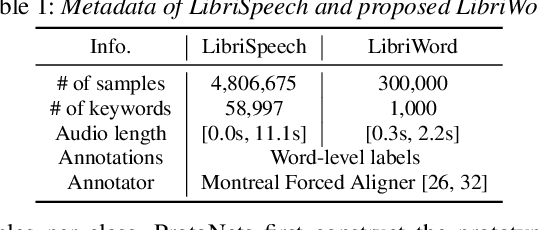
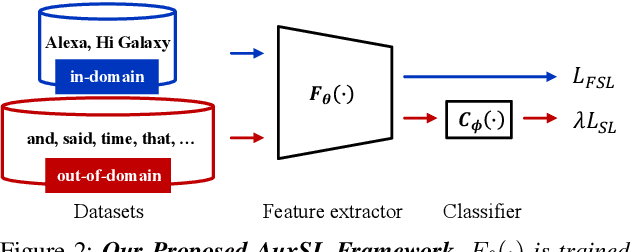
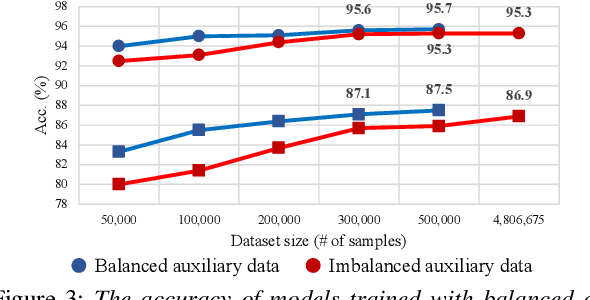
Few-shot keyword spotting (FS-KWS) models usually require large-scale annotated datasets to generalize to unseen target keywords. However, existing KWS datasets are limited in scale and gathering keyword-like labeled data is costly undertaking. To mitigate this issue, we propose a framework that uses easily collectible, unlabeled reading speech data as an auxiliary source. Self-supervised learning has been widely adopted for learning representations from unlabeled data; however, it is known to be suitable for large models with enough capacity and is not practical for training a small footprint FS-KWS model. Instead, we automatically annotate and filter the data to construct a keyword-like dataset, LibriWord, enabling supervision on auxiliary data. We then adopt multi-task learning that helps the model to enhance the representation power from out-of-domain auxiliary data. Our method notably improves the performance over competitive methods in the FS-KWS benchmark.
Scalable Weight Reparametrization for Efficient Transfer Learning
Feb 26, 2023This paper proposes a novel, efficient transfer learning method, called Scalable Weight Reparametrization (SWR) that is efficient and effective for multiple downstream tasks. Efficient transfer learning involves utilizing a pre-trained model trained on a larger dataset and repurposing it for downstream tasks with the aim of maximizing the reuse of the pre-trained model. However, previous works have led to an increase in updated parameters and task-specific modules, resulting in more computations, especially for tiny models. Additionally, there has been no practical consideration for controlling the number of updated parameters. To address these issues, we suggest learning a policy network that can decide where to reparametrize the pre-trained model, while adhering to a given constraint for the number of updated parameters. The policy network is only used during the transfer learning process and not afterward. As a result, our approach attains state-of-the-art performance in a proposed multi-lingual keyword spotting and a standard benchmark, ImageNet-to-Sketch, while requiring zero additional computations and significantly fewer additional parameters.
TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Feb 18, 2023This paper proposes a novel batch normalization strategy for test-time adaptation. Recent test-time adaptation methods heavily rely on the modified batch normalization, i.e., transductive batch normalization (TBN), which calculates the mean and the variance from the current test batch rather than using the running mean and variance obtained from the source data, i.e., conventional batch normalization (CBN). Adopting TBN that employs test batch statistics mitigates the performance degradation caused by the domain shift. However, re-estimating normalization statistics using test data depends on impractical assumptions that a test batch should be large enough and be drawn from i.i.d. stream, and we observed that the previous methods with TBN show critical performance drop without the assumptions. In this paper, we identify that CBN and TBN are in a trade-off relationship and present a new test-time normalization (TTN) method that interpolates the statistics by adjusting the importance between CBN and TBN according to the domain-shift sensitivity of each BN layer. Our proposed TTN improves model robustness to shifted domains across a wide range of batch sizes and in various realistic evaluation scenarios. TTN is widely applicable to other test-time adaptation methods that rely on updating model parameters via backpropagation. We demonstrate that adopting TTN further improves their performance and achieves state-of-the-art performance in various standard benchmarks.
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022
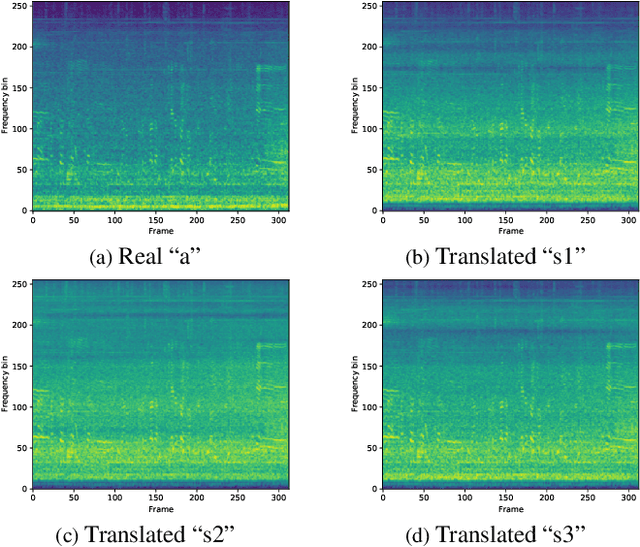
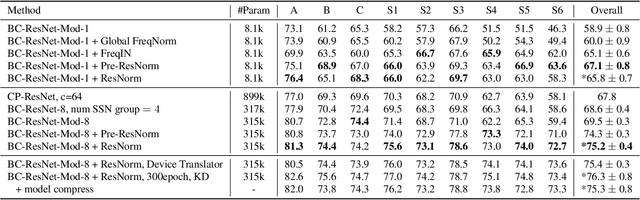
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
Personalized Keyword Spotting through Multi-task Learning
Jun 28, 2022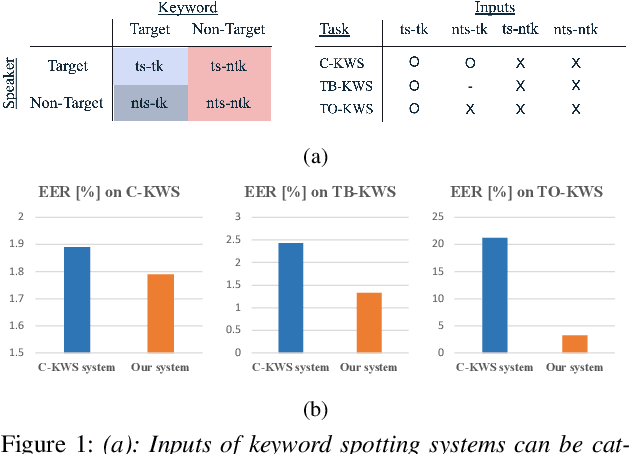
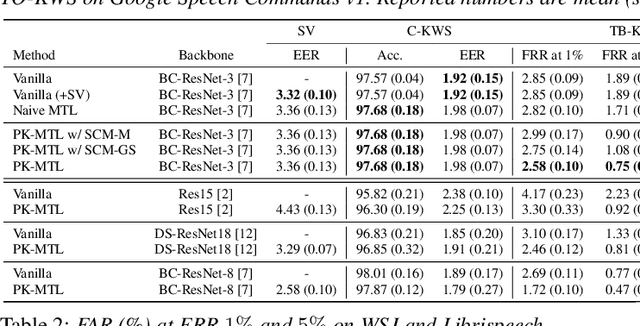
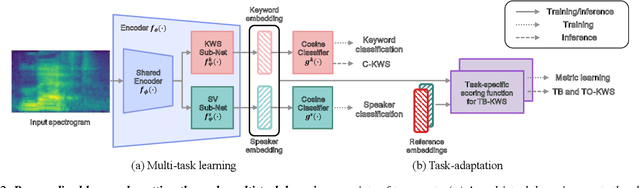
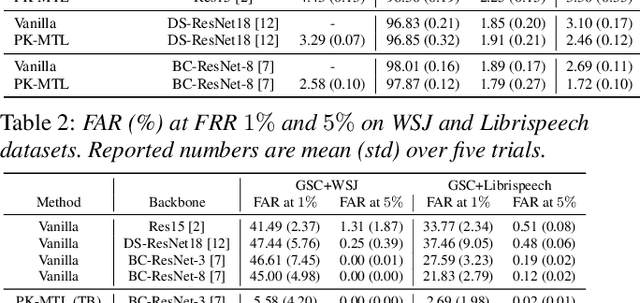
Keyword spotting (KWS) plays an essential role in enabling speech-based user interaction on smart devices, and conventional KWS (C-KWS) approaches have concentrated on detecting user-agnostic pre-defined keywords. However, in practice, most user interactions come from target users enrolled in the device which motivates to construct personalized keyword spotting. We design two personalized KWS tasks; (1) Target user Biased KWS (TB-KWS) and (2) Target user Only KWS (TO-KWS). To solve the tasks, we propose personalized keyword spotting through multi-task learning (PK-MTL) that consists of multi-task learning and task-adaptation. First, we introduce applying multi-task learning on keyword spotting and speaker verification to leverage user information to the keyword spotting system. Next, we design task-specific scoring functions to adapt to the personalized KWS tasks thoroughly. We evaluate our framework on conventional and personalized scenarios, and the results show that PK-MTL can dramatically reduce the false alarm rate, especially in various practical scenarios.
Dummy Prototypical Networks for Few-Shot Open-Set Keyword Spotting
Jun 28, 2022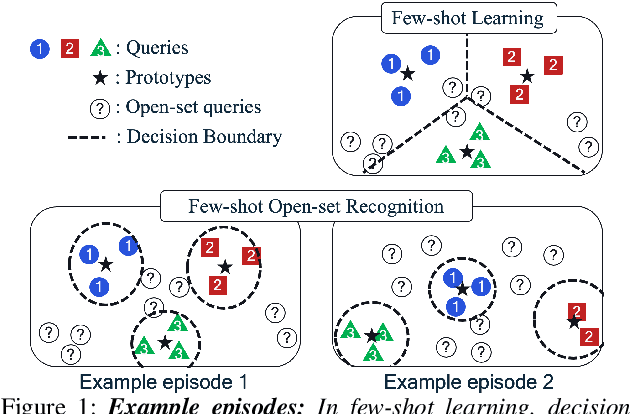
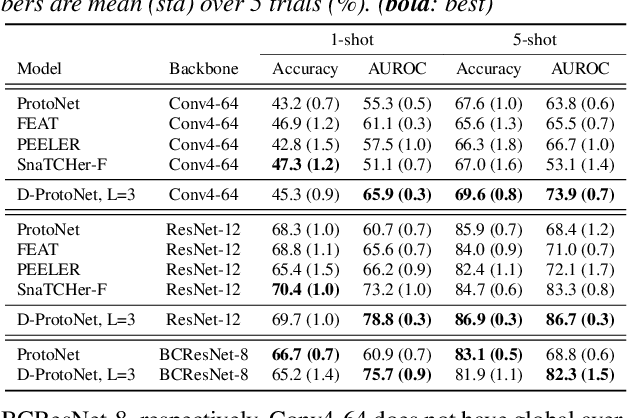

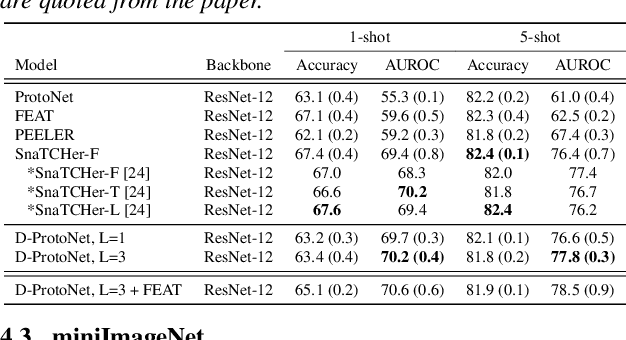
Keyword spotting is the task of detecting a keyword in streaming audio. Conventional keyword spotting targets predefined keywords classification, but there is growing attention in few-shot (query-by-example) keyword spotting, e.g., N-way classification given M-shot support samples. Moreover, in real-world scenarios, there can be utterances from unexpected categories (open-set) which need to be rejected rather than classified as one of the N classes. Combining the two needs, we tackle few-shot open-set keyword spotting with a new benchmark setting, named splitGSC. We propose episode-known dummy prototypes based on metric learning to detect an open-set better and introduce a simple and powerful approach, Dummy Prototypical Networks (D-ProtoNets). Our D-ProtoNets shows clear margins compared to recent few-shot open-set recognition (FSOSR) approaches in the suggested splitGSC. We also verify our method on a standard benchmark, miniImageNet, and D-ProtoNets shows the state-of-the-art open-set detection rate in FSOSR.
Domain Generalization with Relaxed Instance Frequency-wise Normalization for Multi-device Acoustic Scene Classification
Jun 24, 2022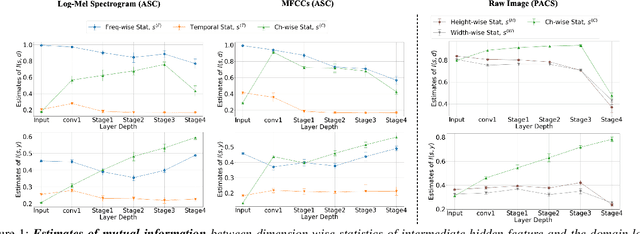
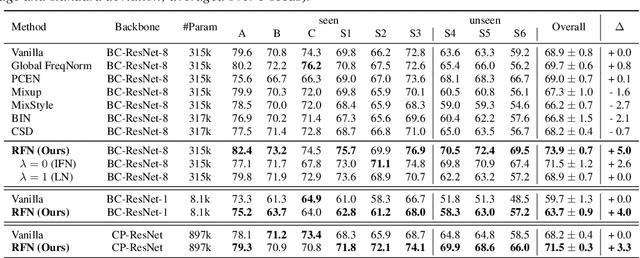
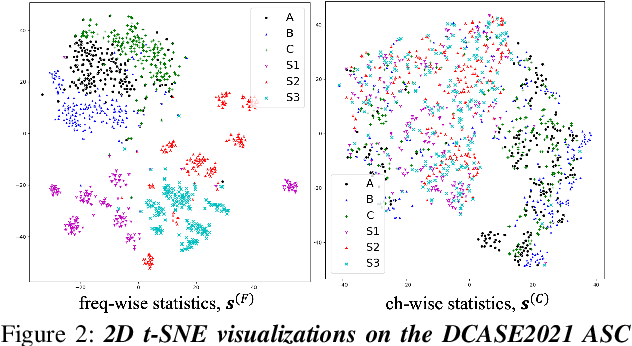
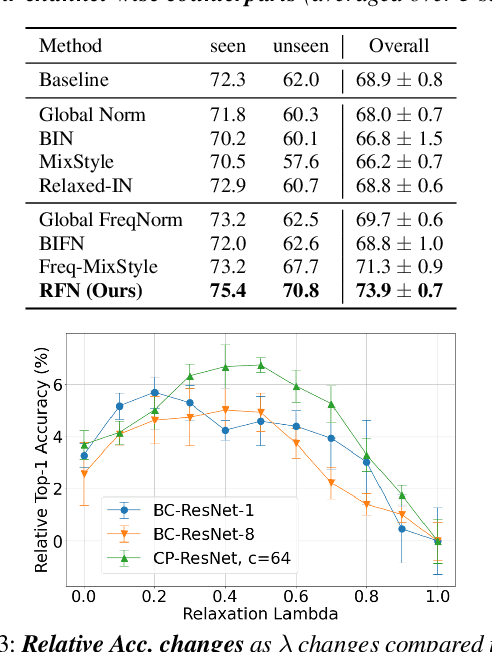
While using two-dimensional convolutional neural networks (2D-CNNs) in image processing, it is possible to manipulate domain information using channel statistics, and instance normalization has been a promising way to get domain-invariant features. However, unlike image processing, we analyze that domain-relevant information in an audio feature is dominant in frequency statistics rather than channel statistics. Motivated by our analysis, we introduce Relaxed Instance Frequency-wise Normalization (RFN): a plug-and-play, explicit normalization module along the frequency axis which can eliminate instance-specific domain discrepancy in an audio feature while relaxing undesirable loss of useful discriminative information. Empirically, simply adding RFN to networks shows clear margins compared to previous domain generalization approaches on acoustic scene classification and yields improved robustness for multiple audio devices. Especially, the proposed RFN won the DCASE2021 challenge TASK1A, low-complexity acoustic scene classification with multiple devices, with a clear margin, and RFN is an extended work of our technical report.
Domain Generalization on Efficient Acoustic Scene Classification using Residual Normalization
Nov 12, 2021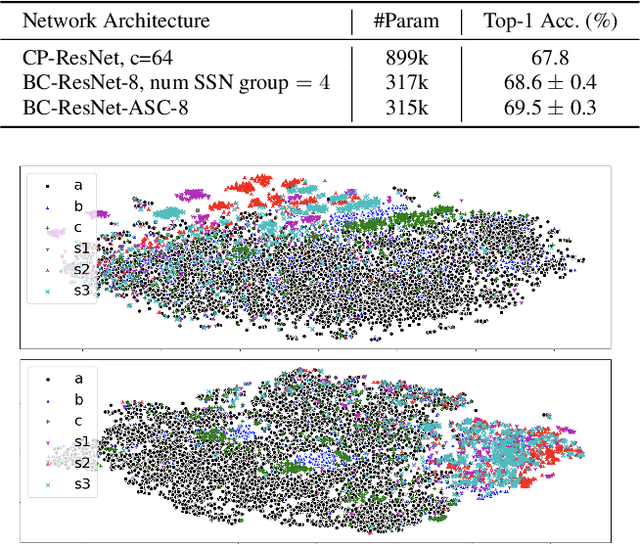
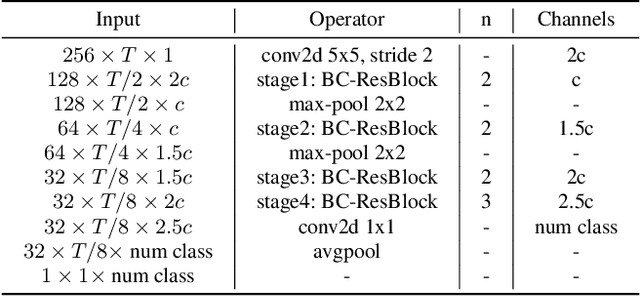
It is a practical research topic how to deal with multi-device audio inputs by a single acoustic scene classification system with efficient design. In this work, we propose Residual Normalization, a novel feature normalization method that uses frequency-wise normalization % instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Moreover, we introduce an efficient architecture, BC-ResNet-ASC, a modified version of the baseline architecture with a limited receptive field. BC-ResNet-ASC outperforms the baseline architecture even though it contains the small number of parameters. Through three model compression schemes: pruning, quantization, and knowledge distillation, we can reduce model complexity further while mitigating the performance degradation. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters. The proposed method won the 1st place in DCASE 2021 challenge, TASK1A.
Broadcasted Residual Learning for Efficient Keyword Spotting
Jun 30, 2021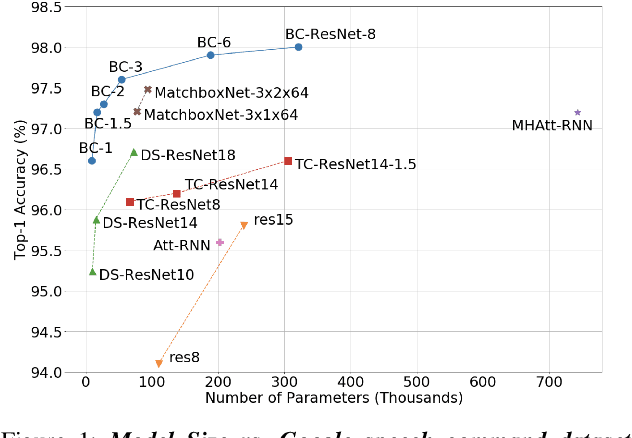
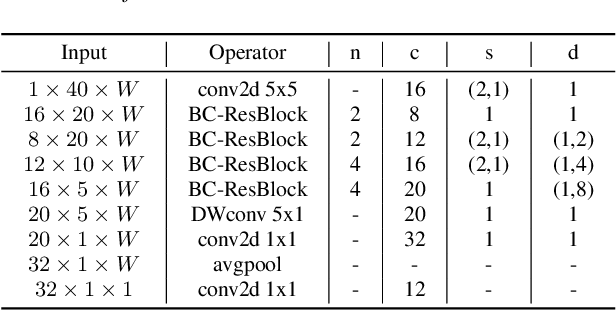
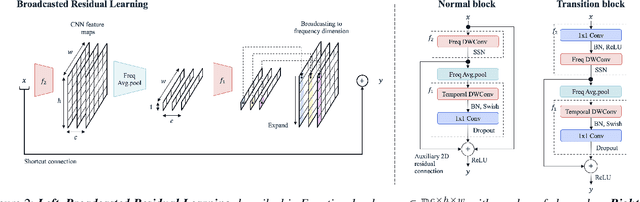
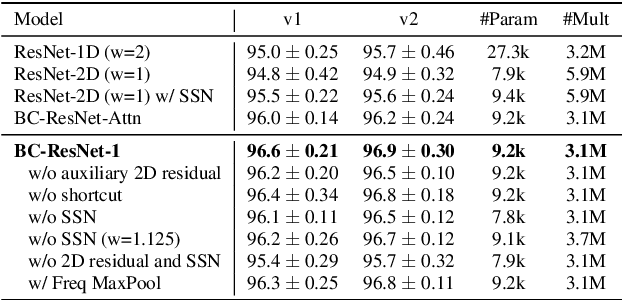
Keyword spotting is an important research field because it plays a key role in device wake-up and user interaction on smart devices. However, it is challenging to minimize errors while operating efficiently in devices with limited resources such as mobile phones. We present a broadcasted residual learning method to achieve high accuracy with small model size and computational load. Our method configures most of the residual functions as 1D temporal convolution while still allows 2D convolution together using a broadcasted-residual connection that expands temporal output to frequency-temporal dimension. This residual mapping enables the network to effectively represent useful audio features with much less computation than conventional convolutional neural networks. We also propose a novel network architecture, Broadcasting-residual network (BC-ResNet), based on broadcasted residual learning and describe how to scale up the model according to the target device's resources. BC-ResNets achieve state-of-the-art 98.0% and 98.7% top-1 accuracy on Google speech command datasets v1 and v2, respectively, and consistently outperform previous approaches, using fewer computations and parameters.