 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFC-TTS: Style and Timbre Control in Zero-Shot Text-to-Speech with Disentangled Speech Representations
May 23, 2026Recent advances in zero-shot text-to-speech (TTS) have enabled accurate imitation of reference speech in terms of both speaking style and speaker timbre. However, achieving disentangled control over these aspects from separate references remains a challenging task. Several studies have proposed disentangled speech representations that decompose speech into interpretable attributes (e.g., timbre, prosody, and content), providing a promising foundation for TTS with attribute control from separate references. Yet, how to effectively integrate such representations into TTS systems to achieve independent and precise control remains underexplored. In this paper, we present FC-TTS, a zero-shot TTS framework that enables disentangled control of style and timbre by conditioning on two distinct reference utterances. Unlike existing systems that inherit limitations from those pre-trained disentangled representations, FC-TTS introduces key design strategies, including architectural choices, training framework, and auxiliary training objectives, which improve the reliability of attribute separation and dual-reference control. Experiments show that FC-TTS achieves high-fidelity synthesis and competitive zero-shot naturalness, while uniquely supporting consistent and independent manipulation of style and timbre. Audio samples are available at https://qualcomm-ai-research.github.io/fc-tts
FedHide: Federated Learning by Hiding in the Neighbors
Sep 12, 2024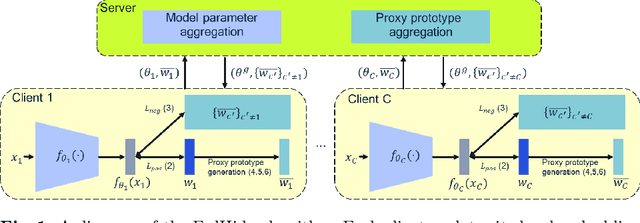

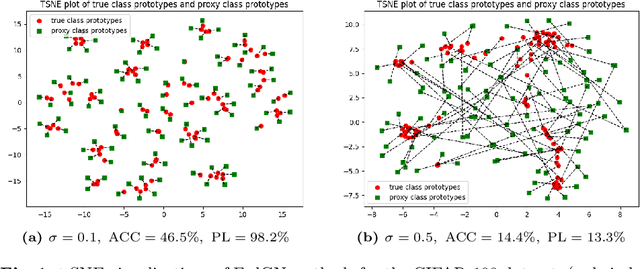
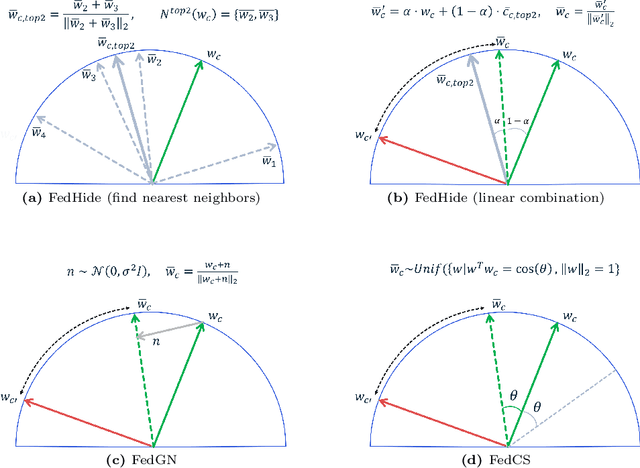
We propose a prototype-based federated learning method designed for embedding networks in classification or verification tasks. Our focus is on scenarios where each client has data from a single class. The main challenge is to develop an embedding network that can distinguish between different classes while adhering to privacy constraints. Sharing true class prototypes with the server or other clients could potentially compromise sensitive information. To tackle this issue, we propose a proxy class prototype that will be shared among clients instead of the true class prototype. Our approach generates proxy class prototypes by linearly combining them with their nearest neighbors. This technique conceals the true class prototype while enabling clients to learn discriminative embedding networks. We compare our method to alternative techniques, such as adding random Gaussian noise and using random selection with cosine similarity constraints. Furthermore, we evaluate the robustness of our approach against gradient inversion attacks and introduce a measure for prototype leakage. This measure quantifies the extent of private information revealed when sharing the proposed proxy class prototype. Moreover, we provide a theoretical analysis of the convergence properties of our approach. Our proposed method for federated learning from scratch demonstrates its effectiveness through empirical results on three benchmark datasets: CIFAR-100, VoxCeleb1, and VGGFace2.
Feature Diversification and Adaptation for Federated Domain Generalization
Jul 11, 2024



Federated learning, a distributed learning paradigm, utilizes multiple clients to build a robust global model. In real-world applications, local clients often operate within their limited domains, leading to a `domain shift' across clients. Privacy concerns limit each client's learning to its own domain data, which increase the risk of overfitting. Moreover, the process of aggregating models trained on own limited domain can be potentially lead to a significant degradation in the global model performance. To deal with these challenges, we introduce the concept of federated feature diversification. Each client diversifies the own limited domain data by leveraging global feature statistics, i.e., the aggregated average statistics over all participating clients, shared through the global model's parameters. This data diversification helps local models to learn client-invariant representations while preserving privacy. Our resultant global model shows robust performance on unseen test domain data. To enhance performance further, we develop an instance-adaptive inference approach tailored for test domain data. Our proposed instance feature adapter dynamically adjusts feature statistics to align with the test input, thereby reducing the domain gap between the test and training domains. We show that our method achieves state-of-the-art performance on several domain generalization benchmarks within a federated learning setting.
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
Domain Generalization with Relaxed Instance Frequency-wise Normalization for Multi-device Acoustic Scene Classification
Jun 24, 2022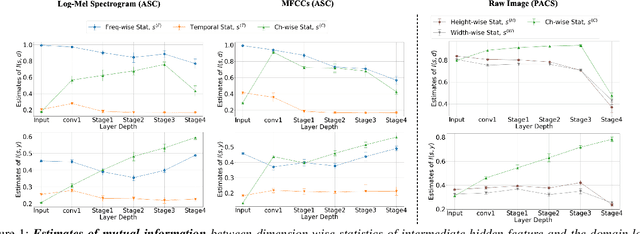
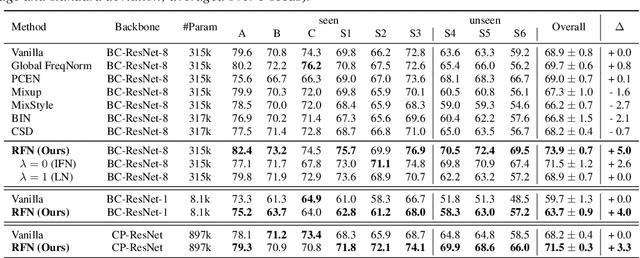
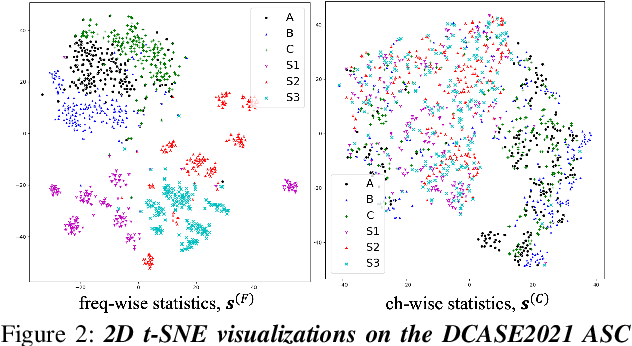
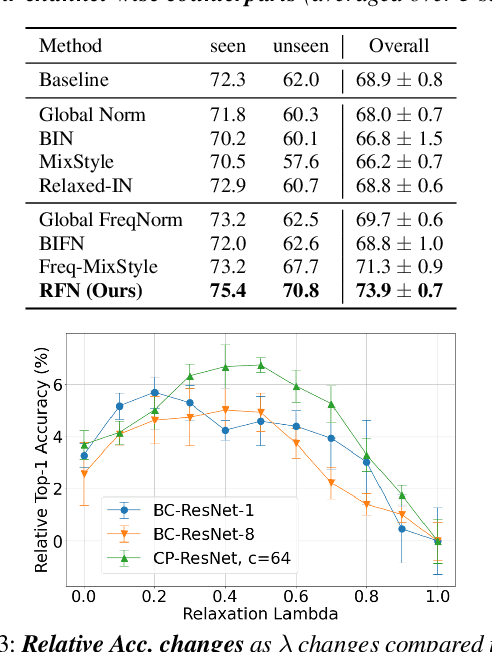
While using two-dimensional convolutional neural networks (2D-CNNs) in image processing, it is possible to manipulate domain information using channel statistics, and instance normalization has been a promising way to get domain-invariant features. However, unlike image processing, we analyze that domain-relevant information in an audio feature is dominant in frequency statistics rather than channel statistics. Motivated by our analysis, we introduce Relaxed Instance Frequency-wise Normalization (RFN): a plug-and-play, explicit normalization module along the frequency axis which can eliminate instance-specific domain discrepancy in an audio feature while relaxing undesirable loss of useful discriminative information. Empirically, simply adding RFN to networks shows clear margins compared to previous domain generalization approaches on acoustic scene classification and yields improved robustness for multiple audio devices. Especially, the proposed RFN won the DCASE2021 challenge TASK1A, low-complexity acoustic scene classification with multiple devices, with a clear margin, and RFN is an extended work of our technical report.
Federated Learning of User Verification Models Without Sharing Embeddings
Apr 18, 2021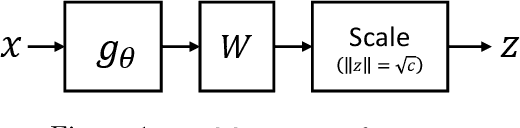
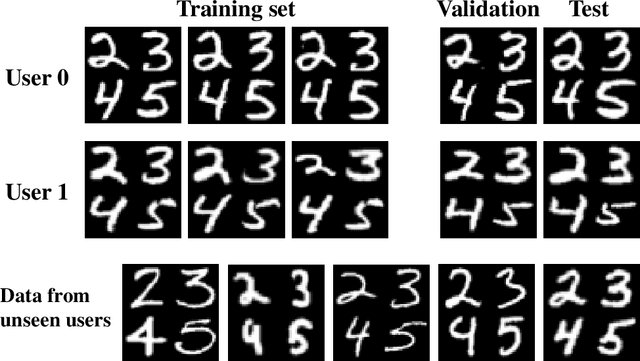
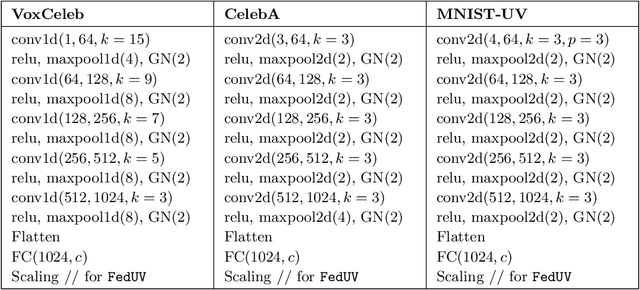
We consider the problem of training User Verification (UV) models in federated setting, where each user has access to the data of only one class and user embeddings cannot be shared with the server or other users. To address this problem, we propose Federated User Verification (FedUV), a framework in which users jointly learn a set of vectors and maximize the correlation of their instance embeddings with a secret linear combination of those vectors. We show that choosing the linear combinations from the codewords of an error-correcting code allows users to collaboratively train the model without revealing their embedding vectors. We present the experimental results for user verification with voice, face, and handwriting data and show that FedUV is on par with existing approaches, while not sharing the embeddings with other users or the server.
SubSpectral Normalization for Neural Audio Data Processing
Mar 25, 2021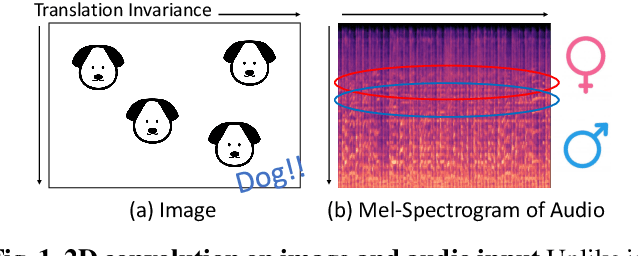

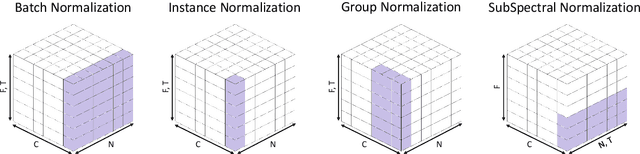
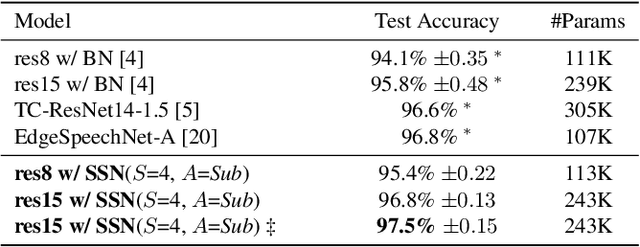
Convolutional Neural Networks are widely used in various machine learning domains. In image processing, the features can be obtained by applying 2D convolution to all spatial dimensions of the input. However, in the audio case, frequency domain input like Mel-Spectrogram has different and unique characteristics in the frequency dimension. Thus, there is a need for a method that allows the 2D convolution layer to handle the frequency dimension differently. In this work, we introduce SubSpectral Normalization (SSN), which splits the input frequency dimension into several groups (sub-bands) and performs a different normalization for each group. SSN also includes an affine transformation that can be applied to each group. Our method removes the inter-frequency deflection while the network learns a frequency-aware characteristic. In the experiments with audio data, we observed that SSN can efficiently improve the network's performance.
Federated Learning of User Authentication Models
Jul 09, 2020
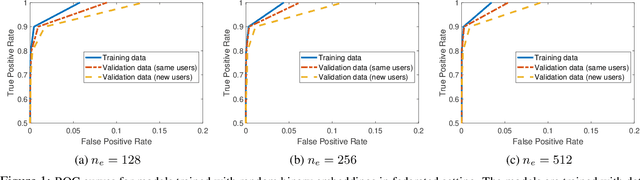
Machine learning-based User Authentication (UA) models have been widely deployed in smart devices. UA models are trained to map input data of different users to highly separable embedding vectors, which are then used to accept or reject new inputs at test time. Training UA models requires having direct access to the raw inputs and embedding vectors of users, both of which are privacy-sensitive information. In this paper, we propose Federated User Authentication (FedUA), a framework for privacy-preserving training of UA models. FedUA adopts federated learning framework to enable a group of users to jointly train a model without sharing the raw inputs. It also allows users to generate their embeddings as random binary vectors, so that, unlike the existing approach of constructing the spread out embeddings by the server, the embedding vectors are kept private as well. We show our method is privacy-preserving, scalable with number of users, and allows new users to be added to training without changing the output layer. Our experimental results on the VoxCeleb dataset for speaker verification shows our method reliably rejects data of unseen users at very high true positive rates.
Meta-Learning via Feature-Label Memory Network
Oct 19, 2017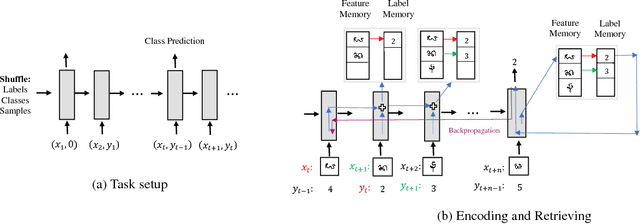
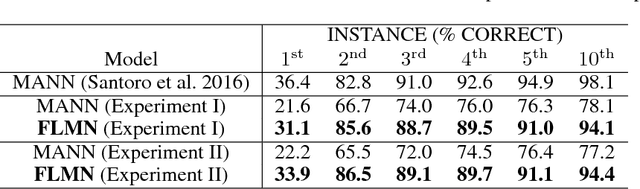
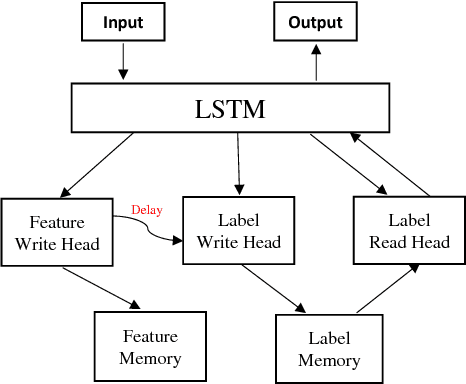
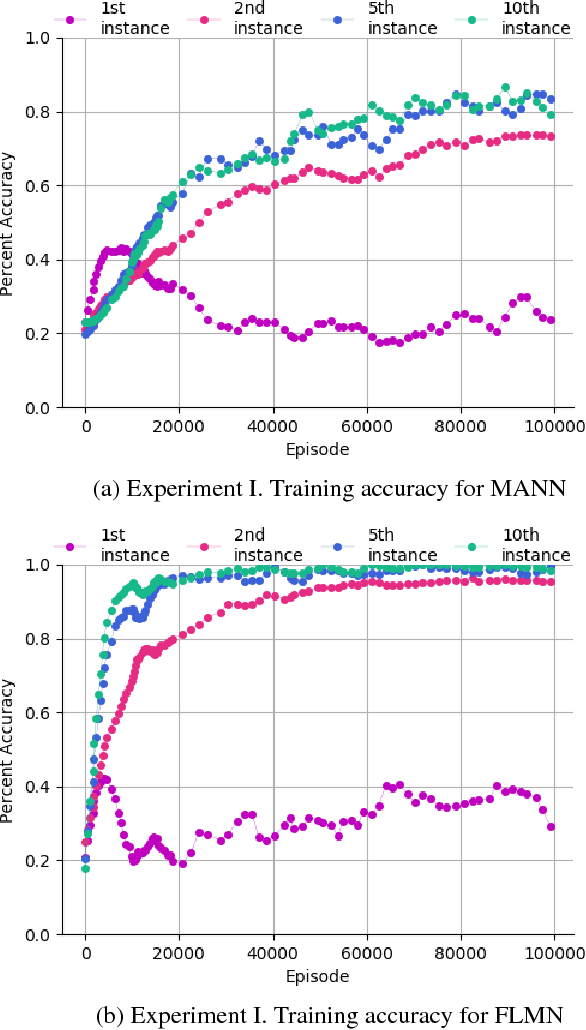
Deep learning typically requires training a very capable architecture using large datasets. However, many important learning problems demand an ability to draw valid inferences from small size datasets, and such problems pose a particular challenge for deep learning. In this regard, various researches on "meta-learning" are being actively conducted. Recent work has suggested a Memory Augmented Neural Network (MANN) for meta-learning. MANN is an implementation of a Neural Turing Machine (NTM) with the ability to rapidly assimilate new data in its memory, and use this data to make accurate predictions. In models such as MANN, the input data samples and their appropriate labels from previous step are bound together in the same memory locations. This often leads to memory interference when performing a task as these models have to retrieve a feature of an input from a certain memory location and read only the label information bound to that location. In this paper, we tried to address this issue by presenting a more robust MANN. We revisited the idea of meta-learning and proposed a new memory augmented neural network by explicitly splitting the external memory into feature and label memories. The feature memory is used to store the features of input data samples and the label memory stores their labels. Hence, when predicting the label of a given input, our model uses its feature memory unit as a reference to extract the stored feature of the input, and based on that feature, it retrieves the label information of the input from the label memory unit. In order for the network to function in this framework, a new memory-writingmodule to encode label information into the label memory in accordance with the meta-learning task structure is designed. Here, we demonstrate that our model outperforms MANN by a large margin in supervised one-shot classification tasks using Omniglot and MNIST datasets.
Early Improving Recurrent Elastic Highway Network
Aug 14, 2017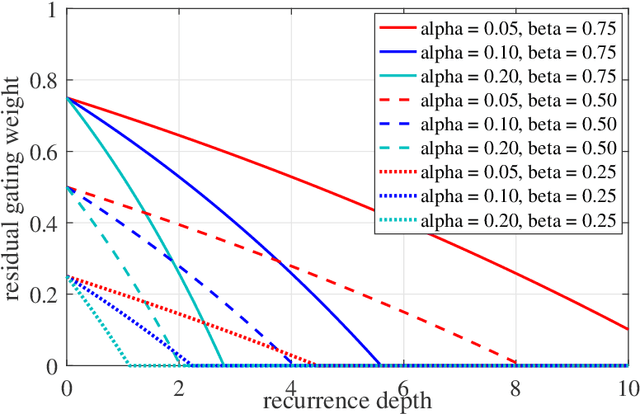
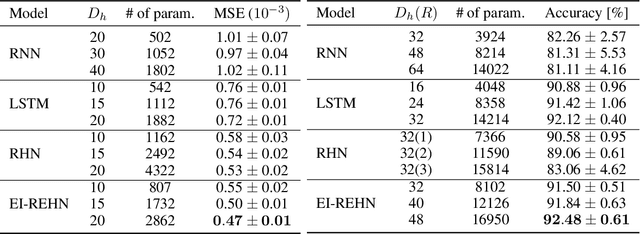
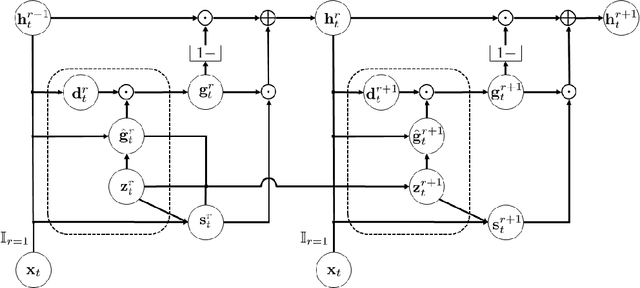

To model time-varying nonlinear temporal dynamics in sequential data, a recurrent network capable of varying and adjusting the recurrence depth between input intervals is examined. The recurrence depth is extended by several intermediate hidden state units, and the weight parameters involved in determining these units are dynamically calculated. The motivation behind the paper lies on overcoming a deficiency in Recurrent Highway Networks and improving their performances which are currently at the forefront of RNNs: 1) Determining the appropriate number of recurrent depth in RHN for different tasks is a huge burden and just setting it to a large number is computationally wasteful with possible repercussion in terms of performance degradation and high latency. Expanding on the idea of adaptive computation time (ACT), with the use of an elastic gate in the form of a rectified exponentially decreasing function taking on as arguments as previous hidden state and input, the proposed model is able to evaluate the appropriate recurrent depth for each input. The rectified gating function enables the most significant intermediate hidden state updates to come early such that significant performance gain is achieved early. 2) Updating the weights from that of previous intermediate layer offers a richer representation than the use of shared weights across all intermediate recurrence layers. The weight update procedure is just an expansion of the idea underlying hypernetworks. To substantiate the effectiveness of the proposed network, we conducted three experiments: regression on synthetic data, human activity recognition, and language modeling on the Penn Treebank dataset. The proposed networks showed better performance than other state-of-the-art recurrent networks in all three experiments.